离散数据编码方式总结(OneHotEncoder、LabelEncoder、OrdinalEncoder、get_dummies、DictVectorizer、to_categorical的区别?)
写在前面
在机器学习的特征选择的时候,往往有一些离散的特征不好计算,此时需要对这些特征进行编码,但是编码方式有很多,不同的包也会有不同的编码方式。(明白OneHotEncoder、LabelEncoder、OrdinalEncoder、get_dummies、DictVectorizer的区别吗?)
通过在Titanic预测的学习, 在这里对不同包的编码方式进行一个小总结。 至少以后使用的时候,不那么的乱用了。
先记住对离散数据进行编码的总原则:
- 离散特征的取值之间没有大小的意义,比如color:[red,blue], 性别的男女等,那么就使用OneHot编码
- 离散特征的取值有大小的意义,比如size:[X,XL,XXL],身高的高,中,低等,那么就使用数值的映射(数字){X:1,XL:2,XXL:3}进行编码
下面就分别梳理一下不同的包里面一些不同的函数进行编码时使用方法,这里以Titanic中的数值处理的例子展开:
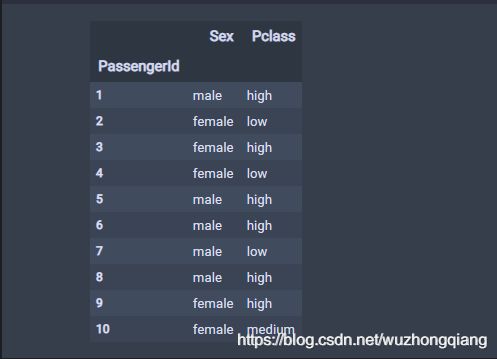
Titanic数据的原始形式长这个样子:

在这里面,可以发现,Sex列的这一个特征有’male’和’female’两个取值,而这两个值相互之间没有大小的意义,所以需要对Sex列进行独热编码。
而Pclass列的取值“3”,“2”, “1” 表示的船票的等级,有大小的意义,我们对其进行数字编码(因为这个3, 2, 1本身是数字,后面我为了更好的解释数字编码,提取数据的时候,把3, 2, 1转换成“high”, “medium”, “low”,这样带有等级意义的字符串)
所以下面,我单独提取这两列数据进行操作,任务就是把Sex列进行Onehot编码, 对Pclass列进行数字编码。我提取处理后的数据长这样:
首先,我先列出不同的包可以实现上面功能的函数
- 进行OneHot编码
- sklearn.preprocessing.OneHotEncoder()
- sklearn.feature_extraction.DictVectorizer()
- pd.get_dummies()
- 进行数字编码
- sklearn.preprocessing.LabelEncoder()
- sklearn.preprocessing.OrdinalEncoder()
- map函数映射
任务一:对Sex列进行OneHot编码
方法1:pd.get_dummies
这是pandas自带的将数据转成独热编码的方式,简单,并且好用,可以当做首选,尤其是表格数据的时候。详情可以参考官方文档,也可以简单的参考一下这篇笔记pandas.get_dummies 的用法。
这里,我只想通过上面的任务看看应该怎么使用。
再看一遍数据的样子:
print(data)

看上面的data数据,如果我直接对整个data进行编码的话
d = pd.get_dummies(data)
print(d)
结果如下:

当然这里,我们只需要对Sex列进行独热编码
data1 = pd.get_dummies(data['Sex'], columns=np.unique(data['Sex'].values))
data1
结果如下:

注意: get_dummies转独热编码,是针对离散的字符串的数据,整数的话我发现仍然保留原来的样子。
方法2:OneHotEncoder()
看了好几个博客,说这种方式只能对整数进行编码,字符串不行,但是我今天试了一下,字符串是可以的,官方文档也是说输入是字符串或者整数。
但是要注意,OneHotEncoder的fit_transform()函数接收是二维数组的形式,所以如果是pandas表格的某一列,也需要到时候转换一下,直接看操作把。输出也是二维数组的形式。下面我又DataFrame了一下
ohe = OneHotEncoder(sparse=False) # 非稀疏
data2 = ohe.fit_transform(data['Sex'].values.reshape(-1, 1)) # 转成二维数组
data2 = pd.DataFrame(data2, columns=['female', 'male'])
data2
结果长这样:

方法3:DictVectorizer
实现了 “one-of-K” 或 “one-hot” 编码,用于分类(也称为标称,离散)特征。分类功能是 “属性值” 对,其中该值被限制为不排序的可能性的离散列表(例如主题标识符,对象类型,标签,名称…)。也就是说,其他的整数的这种情况会保留原来的值。
这个fit_transform里面接收的要是一个字典的形式,输出是二维数组。
dvec = DictVectorizer(sparse=False)
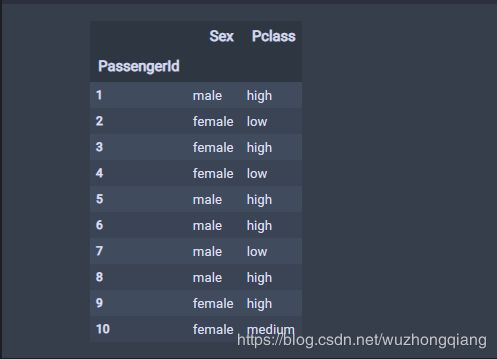
data3 = dvec.fit_transform(data.to_dict(orient='record'))
data3
这里我先用了整个data看看效果,会发现那两列字符串都转成了OneHot的形式
如果是只需要转换Sex列,需要下面这样:
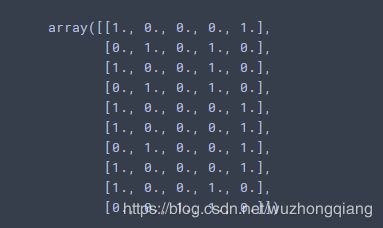
temp = pd.DataFrame(data['Sex'], columns=['Sex'])
dvec = DictVectorizer(sparse=False)
data3 = dvec.fit_transform(temp.to_dict(orient='record'))
data3
把Sex列单独拿出来处理。
方法四: 这个是附加一个keras.utils.to_categorical
这个也是实现的one-hot编码,不过一般是用于类别,也就是标签的时候,是把类别标签转换为onehot编码(categorical就是类别标签的意思,表示现实世界中你分类的各类别),如果特征想要编码成one-hot,还是不要用这个了吧。原型如下:
to_categorical(y, num_classes=None, dtype=‘float32’)
将整型的类别标签转为onehot编码。y为int数组,num_classes为标签类别总数,大于max(y)(标签从0开始的)。
返回:如果num_classes=None,返回len(y) * [max(y)+1](维度,m*n表示m行n列矩阵,下同),否则为len(y) * num_classes。
下面看个例子:
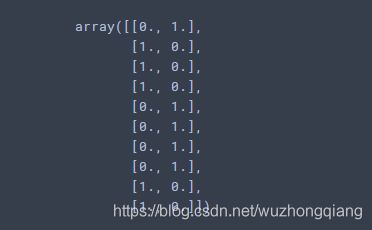
import keras
ohl=keras.utils.to_categorical([1,3])
# ohl=keras.utils.to_categorical([[1],[3]])
print(ohl)
"""
[[0. 1. 0. 0.]
[0. 0. 0. 1.]]
"""
ohl=keras.utils.to_categorical([1,3],num_classes=5)
print(ohl)
"""
[[0. 1. 0. 0. 0.]
[0. 0. 0. 1. 0.]]
"""
任务二:对Pclass列进行数字映射编码
方法一:map()函数映射
这是一种很方便,很快的方式。使用map()函数。
pclass_map = {label:idx for idx, label in enumerate(set(data['Pclass']))}
# 也可以pclass_map = {"low":0, "medium":1, "high":2}
d1 = data['Pclass'].map(pclass_map)
d1
上面可以发现,如果是用for循环的这种map函数, 编码形式虽然是0,1,2这种数字形式,但是含义已经掩盖掉了。 也就是说0,1,2已经不能说明什么意义了,只是分别代表high,medium,low这三个字符串。所以如果类别少的话,我们最好是自己自定义进行映射,比如上面我注释掉的那个,那个的0, 1, 2还分别代表低,中,高,顺序意义还在。
为什么说这点呢? 接下往下看。
方法二:LabelEncoder()
这个看官方文档,一般是用于类别标签的,如果用于特征的话,默认并不是按照低、中、高这样的顺序进行编码的,也就是说,这个和上面那种for循环定义映射的那个一样,虽然成功的改成了数字,但是意义不在了。
le = LabelEncoder()
d2 = le.fit_transform(data['Pclass'])
d2

所以人家官方文档才把这个函数的作用说成:
使用0到n_classes-1之间的值对目标标签进行编码。该转换器应用于编码目标值,即 y,而不是输入X。
所以这个函数,别乱用到特征的编码。
方法三:OrdinalEncoder()
将分类特征编码为整数数组。
该转换器的输入应为整数或字符串之类的数组,表示分类(离散)特征所采用的值。要素将转换为序数整数。这将导致每个要素的一列整数(0到n_categories-1)。
所以,这个才是真正的用到分类特征上的映射数字编码,并且还会保留原来的顺序。
oe = OrdinalEncoder()
d3 = oe.fit_transform(data['Pclass'].values.reshape(-1, 1))
d3

看这个函数,把低,中,高分别编码成了0, 1, 2. 保留了原来的顺序。
所以这个函数编码中也是很好用的。
总结一下
根据上面的使用简单的总结一下:
-
sklearn.preprocessing.OneHotEncoder、pd.get_dummies、sklearn.feature_extraction.DictVectorizer都可以用来对离散的特征且数据直接无大小意义的数据进行独热编码,但用法不同,接收和输出也不同。
- OneHotEnCoder的fit_transform(这里面的参数是个二维数组),输出的形式也是二维数组
- get_dummies(数据可以是pandas), 并且输出的时候,会多出转换后的几列。这个好用一点。
- DictVectorizer的fit_transform(这里面的参数是字典的形式),输出的形式也是二维数组。
-
sklearn.preprocessing.LabelEncoder、sklearn.preprocessing.OrdinalEncoder、map()映射都可以对离散的且数据有大小意义的数据进行数字编码,但用法也不同
- LableEncoder是用于类别标签的,不会保留大小意义
- OrdinalEncoder是用于特征的,可以保留大小意义
- map()映射灵活性很强,就看自己怎么写了。
参考博客:
- scikit-learn 中 OneHotEncoder 解析
- pandas的get_dummies
- 对类别Category数据编码的几种方法
- pandas使用get_dummies进行one-hot编码
- Python数据预处理中的LabelEncoder与OneHotEncoder
- python数据处理:对类别Category进行编码(转化为数值)