零基础入门数据挖掘:Task2 数据分析
学习终于正式开始了,首先这里说一下,所谓零基础也不是随便拉个人来就能学的。作为一个大一的小小小白,没有概率统计基础,在数据分析这里实在是吃了一个大鳖。。。但是如果能克服这个困难,入门也不算很难。(恶补中)博客里大多数看起来很整齐的东西都来自这里
载入库和数据
我们主要会用到 pandas、numpy、scipy; matplotlib、seabon;missingno。
这里有导入warnings包,过滤掉警告语句
import warnings
warnings.filterwarnings('ignore')
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import missingno as msno
然后载入训练集和测试集
这里路径的 斜杠 和电脑里地址栏的路径的 斜杠 不一样
,一直报错,搞了半天结果毛病出在这里(捂脸哭)
path = './datalab/231784/'
Train_data = pd.read_csv(path+'used_car_train_20200313.csv', sep=' ')
Test_data = pd.read_csv(path+'used_car_testA_20200313.csv', sep=' ')
总览并清洗分析数据
这里罗列一下特征集
name - 汽车编码
regDate - 汽车注册时间
model - 车型编码
brand - 品牌
bodyType - 车身类型
fuelType - 燃油类型
gearbox - 变速箱
power - 汽车功率
kilometer - 汽车行驶公里
notRepairedDamage - 汽车有尚未修复的损坏
regionCode - 看车地区编码
seller - 销售方
offerType - 报价类型
creatDate - 广告发布时间
price - 汽车价格
v_0', 'v_1', 'v_2', 'v_3', 'v_4', 'v_5', 'v_6', 'v_7', 'v_8', 'v_9', 'v_10', 'v_11', 'v_12', 'v_13','v_14' 【匿名特征,包含v0-14在内15个匿名特征】
利用这这段代码来总览一下数据
# 主要统计量
Train_data.head().append(Train_data.tail())
Test_data.head().append(Train_data.tail())
# 数据类型
Train_data.info()
Test_data.info()
判断缺失和异常
# 查看nan
Train_data.isnull().sum()
Test_data.isnull().sum()
# 查看缺省
msno.matrix(Train_data.sample(250))
msno.bar(Train_data.sample(1000))
msno.matrix(Test_data.sample(250))
msno.bar(Test_data.sample(1000))
两个集的缺省情况差不多,其中notRepairedDamage比较多
把缺省值替换成nan
Train_data['notRepairedDamage'].value_counts()
Train_data['notRepairedDamage'].replace('-', np.nan, inplace=True)
删去严重倾斜的数据(验证步骤跳过)
del Train_data["seller"]
del Train_data["offerType"]
del Test_data["seller"]
del Test_data["offerType"]
了解预测值的分布
import scipy.stats as st
y = Train_data['price']
plt.figure(1); plt.title('Johnson SU')
sns.distplot(y, kde=False, fit=st.johnsonsu)
plt.figure(2); plt.title('Normal')
sns.distplot(y, kde=False, fit=st.norm)
plt.figure(3); plt.title('Log Normal')
sns.distplot(y, kde=False, fit=st.lognorm)
通过观察绘图发现:价格不服从正态分布,所以在进行回归之前,它必须进行转换。虽然对数变换做得很好,但最佳拟合是无界约翰逊分布
查看偏度和峰值
(yysy,把各种库都装好了,你想要什么直接就能搞出来,方便的很。)
sns.distplot(Train_data['price']);
print("Skewness: %f" % Train_data['price'].skew())
print("Kurtosis: %f" % Train_data['price'].kurt())
类别特征和数字特征
# 分离label即预测值
Y_train = Train_data['price']
# 这个区别方式适用于没有直接label coding的数据
# 这里不适用,需要人为根据实际含义来区分
# 数字特征
# numeric_features = Train_data.select_dtypes(include=[np.number])
# numeric_features.columns
# # 类型特征
# categorical_features = Train_data.select_dtypes(include=[np.object])
# categorical_features.columns
numeric_features = ['power', 'kilometer', 'v_0', 'v_1', 'v_2', 'v_3', 'v_4', 'v_5', 'v_6', 'v_7', 'v_8', 'v_9', 'v_10', 'v_11', 'v_12', 'v_13','v_14' ]
categorical_features = ['name', 'model', 'brand', 'bodyType', 'fuelType', 'gearbox', 'notRepairedDamage', 'regionCode',]
# 特征nunique分布
for cat_fea in categorical_features:
print(cat_fea + "的特征分布如下:")
print("{}特征有个{}不同的值".format(cat_fea, Train_data[cat_fea].nunique()))
print(Train_data[cat_fea].value_counts())
特征unique分布
# 特征nunique分布
for cat_fea in categorical_features:
print(cat_fea + "的特征分布如下:")
print("{}特征有个{}不同的值".format(cat_fea, Test_data[cat_fea].nunique()))
print(Test_data[cat_fea].value_counts())
数字特征分析:
numeric_features.append('price')
numeric_features
# 相关性分析
price_numeric = Train_data[numeric_features]
correlation = price_numeric.corr()
print(correlation['price'].sort_values(ascending = False),'\n')
f , ax = plt.subplots(figsize = (7, 7))
plt.title('Correlation of Numeric Features with Price',y=1,size=16)
sns.heatmap(correlation,square = True, vmax=0.8)
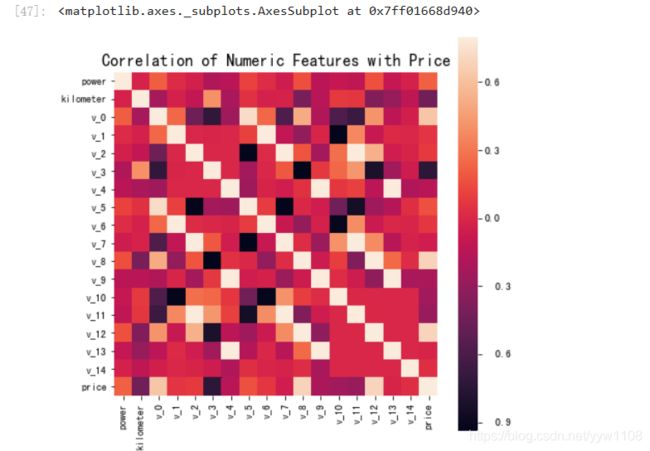
del price_numeric['price']
## 2) 查看几个特征得 偏度和峰值
for col in numeric_features:
print('{:15}'.format(col),
'Skewness: {:05.2f}'.format(Train_data[col].skew()) ,
' ' ,
'Kurtosis: {:06.2f}'.format(Train_data[col].kurt())
)
## 3) 每个数字特征得分布可视化
f = pd.melt(Train_data, value_vars=numeric_features)
g = sns.FacetGrid(f, col="variable", col_wrap=2, sharex=False, sharey=False)
g = g.map(sns.distplot, "value")
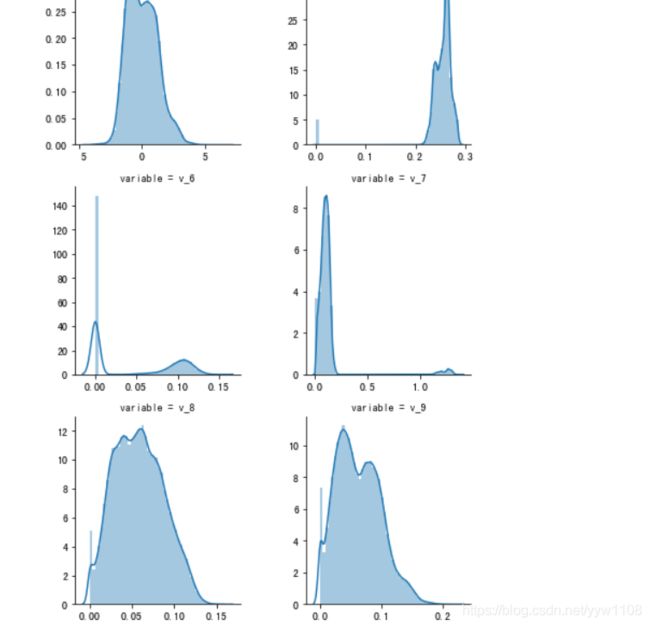 可以看出匿名特征相对分布均匀
可以看出匿名特征相对分布均匀
sns.set()
columns = ['price', 'v_12', 'v_8' , 'v_0', 'power', 'v_5', 'v_2', 'v_6', 'v_1', 'v_14']
sns.pairplot(Train_data[columns],size = 2 ,kind ='scatter',diag_kind='kde')
plt.show()
类别特征分析
## 2) 类别特征箱形图可视化
# 因为 name和 regionCode的类别太稀疏了,这里我们把不稀疏的几类画一下
categorical_features = ['model',
'brand',
'bodyType',
'fuelType',
'gearbox',
'notRepairedDamage']
for c in categorical_features:
Train_data[c] = Train_data[c].astype('category')
if Train_data[c].isnull().any():
Train_data[c] = Train_data[c].cat.add_categories(['MISSING'])
Train_data[c] = Train_data[c].fillna('MISSING')
def boxplot(x, y, **kwargs):
sns.boxplot(x=x, y=y)
x=plt.xticks(rotation=90)
f = pd.melt(Train_data, id_vars=['price'], value_vars=categorical_features)
g = sns.FacetGrid(f, col="variable", col_wrap=2, sharex=False, sharey=False, size=5)
g = g.map(boxplot, "value", "price")
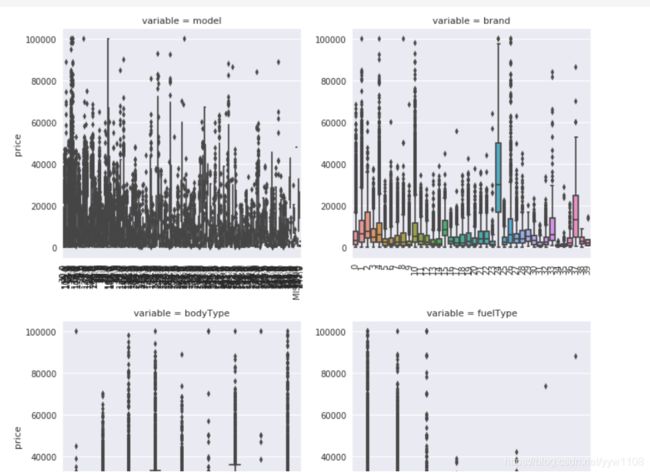
生成数据报告
#用pandas_profiling生成数据报告
import pandas_profiling
pfr = pandas_profiling.ProfileReport(Train_data)
pfr.to_file("./example.html")
打开html即可查看