目录
1. 虚拟宽带远程接入服务:从BRAS到vBRAS的演进
2. 高性能vBRAS的设计方法
3. 基于Arria10 FPGA的智能网卡解析
4. 性能测试
5. 结语
1. 虚拟宽带远程接入服务:从BRAS到vBRAS的演进

上图为我们展示了传统BRAS逐步演进到vBRAS的三个主要过程:
第一阶段:传统的BRAS使用专用设备,且控制面和转发面紧耦合。图中可以看到控制路径和数据路径是相互重合的。
第二阶段:采用了虚拟化技术,且采用了服务器取代了专用BRAS设备,使用软件和虚拟机实现多个vBRAS。但同时也可以看到,此时控制面和转发面还是相互耦合实现。由于两者性能差别很大,这种实现方式很容易造成数据通路的性能瓶颈,或因数据通路流量过大而占用了控制面的带宽。反之,控制面的流量会影响数据面的线速包处理的能力。
第三阶段:采用虚拟化技术,且控制面和转发面相互分离。从图中可以看到,控制面和转发面由两个服务器分开实现,控制流量和转发流量相互不影响。此外,控制流量能在数据/转发服务器和控制服务器之间双向流动,实现控制面对转发面的控制。
这第三个阶段就是目前英特尔、HPE和中国电信北研院联合研发的最新成果。接下来就详细讲解其技术细节。
2. 高性能vBRAS的设计方法
设计实现上述第三阶段中高性能的vBRAS方案,需要分别实现vBRAS-c (control) 和vBRAS-d (data),即vBRAS控制设备和vBRAS数据设备。这两类设备都应该使用标准化的通用服务器实现。此外,对于vBRAS数据设备而言,需要针对计算量庞大的应用进行专门的优化和加速,使其能进行高吞吐量、低延时的数据包处理。
下图展示了本应用实例中,vBRAS-c和vBRAS-d的设计方法。

对于vBRAS-c节点,其重要的设计思想就是轻量化和虚拟化,使其方便在数据中心或云端进行扩展和移植,同时可以分布式实现,以控制多个数据平面节点。
在本例中,vBRAS-c由一个独立的HPE DL380服务器实现。DL380服务器中包含两个CPU插槽(socket),每个插槽中均有一块14核的Xeon处理器。服务器的总内存为128GB。网络接口方面,vBRAS-c可以使用标准的网卡进行网络通信,比如一块或多块英特尔X710 10GbE网卡即可满足控制平面的流量要求。具体的vBRAS控制应用则在虚拟机中实现,多个虚拟机由SDN控制器统一控制。
对于vBRAS-d节点,总体也通过独立的DL380实现。针对上文提到的优化加速的部分,本实例中使用了基于Arria10 FPGA的智能网卡加速网络功能,如线速处理QoS和多级流量整形。在一个DL380中,可以插入多块FPGA智能网卡,实现并行数据处理,成倍提高数据吞吐量。同时,vBRAS-d节点通过OpenFlow与SDN控制器交互,且一台vBRAS-c设备可以控制多个vBRAS-d设备。
3. 基于Arria10 FPGA的智能网卡解析
使用FPGA智能网卡进行网络加速的好处有以下几点:
解放了宝贵的CPU内核,将原本在CPU中实现的数据处理卸载到FPGA上进行加速实现。这样CPU可以用来做其他的工作,在虚拟化的基础上进一步实现了资源的有效利用。
FPGA拥有低功耗、灵活可编程的特点。在白皮书中提到,在选用的Arria10 GT1150 器件上实现了硬件QoS和多级流量整形后,只占用了FPGA的40%的逻辑资源。换言之,还有60%的资源可以被用来进行其他的网络功能处理和加速。同时,可以随时对FPGA进行编程,因此多种网络功能的加速都可以用一套硬件设备完成,不需要更换加速卡或其他硬件设备。即使是用户自己定义的功能,也可以实现,不需要专有设备完成。这样很好的平衡了高性能和高通用性两者间的矛盾。
FPGA能进行高速并行的数据包处理,且本身就广泛应用于网络通信领域,解决方案丰富且成熟。
下图概括介绍了本实例中在FPGA中实现的数据包转发的数据通路设计。

本设计包含多个模块,如Parser、Look-Up、Buffer Manager、Packet Processor,以及内存控制器和DMA等。数据包进入FPGA后,依次通过各个模块进行特征提取、分类、查找,如果需要就通过PCIe和DMA与CPU进行交互。同时,Buffer Manager会对不同来源的数据包进行流量控制、QoS和流量整形等操作。
这款FPGA智能网卡支持多种包处理模式,即可以将数据包完全在FPGA内部处理后转发,不经过CPU;也可以将数据包通过PCIe传送到CPU,使用DPDK进行包处理,再通过FPGA转发;或者二者结合,一部分功能在CPU中实现,另外一部分卸载到FPGA上完成。可见灵活度很高。
4. 性能测试
下图展示了进行性能测试时的硬件搭建情况。
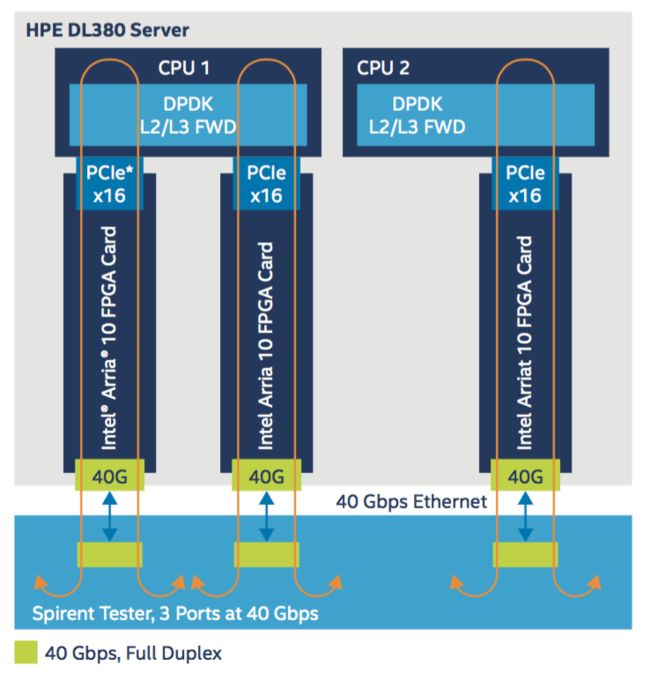
一个DL380服务器上插了3块相互独立的FPGA智能网卡,每块网卡支持40Gbps数据吞吐量,因此一个vBRAS-d服务器支持的总吞吐量为120Gbps。每块网卡通过PCIex16接口与CPU相连,在CPU中运行DPDK L2/L3 FWD应用,将数据转发回FPGA,然后在FPGA中进行QoS和数据整形。在测试中,流量的产生和接收都通过Spirent测试仪实现。
对于QoS,每个智能网卡可以支持4000用户,故单服务器支持12000个用户。每个用户支持2个优先级,且分配给每个用户的带宽可以编程控制。例如,每个用户分配8.5Mbps带宽,则开启流量整形后单服务器总流量应为12000x8.5=102Gbps,如下图所示。

当数据包为定长512字节时,关闭流量整形功能后,高优先级流量和低优先级流量都没有损失,各为60Gbps(对应每个用户的实际流量为5Mbps高优先级+5Mbps低优先级),因此总流量为120Gbps。开启流量整形功能后,高优先级流量没有损失,仍为60Gbps。
对于低优先级,由于每个用户分配8.5Mbps带宽且高优先级已经占用了其中的5Mbps,因此只剩余3.5Mbps带宽供低优先级流量通过。可见低优先级流量遭到限流,总流量变成3.5Mx12000=42Gbps,使得总流量变成102Gbps。这在总体上证明了单个vBRAS-d节点可以支持超过100Gbps的流量处理。
此外还进行了一些功耗测试能性能对比,我在此挑选了一张结果图如下所示。

这张图表示了实现不同带宽时,总功耗性能比的一系列比较。功耗性能比的定义为,实现1Tbps时所需要的总功耗(千瓦)。图中将不含FPGA智能网卡的vBRAS实现50Gbps时的功耗性能比作为基准值(100%)。由图中可以看到,vBRAS+FPGA智能网卡的方案总能降低超过40%的总功耗,最多可达到60%。这进一步印证了上文中阐述过的使用FPGA进行网络功能加速的好处所在。
其他性能测试和对比不再赘述,详细内容在白皮书中可以看到。总体而言,相比于传统的vBRAS服务器+标准网卡的方案,使用vBRAS+FPGA智能网卡的解决方案可以减少约50%的功耗,以及带来超过3倍的性能提升。
5. 结语
这篇白皮书为我们展示了业界领先的企业当前在NFV和SDN领域所做的最新工作,特别是使用FPGA作为硬件加速平台,对网络功能进行卸载和加速。通过对FPGA的使用,大幅提高了硬件资源的利用率,同时带来了系统性能的提升和能耗的下降,降低了部署和运行成本。
现如今,各大互联网公司、云服务提供商、电信网络提供商都开始尝试在他们的数据中心中部署FPGA,其中微软的Azure云服务更是已经大规模采用了Intel FPGA进行硬件加速。这也为今后如何高效的使用FPGA提出了很多全新的要求,很多甚至是我们从未考虑过的。例如:
- 如何有效的设计CPU+FPGA这样的异构计算微结构;
- 如何实现狭义和广义上的计算、控制和存储资源的有效管理和分配;
- 上述设计如何在数据中心进行高效部署;
- 如何设计商业模型以明确FPGA在整个体系中的位置和作用。
老石相信,如何有效解决这些问题都将会是未来一段时间内的研究热点。
参考文献
- 白皮书《为下一代电信基础设施寻找有效的虚拟网络体系架构》,
https://www.intel.com/content/dam/www/programmable/us/en/pdfs/literature/wp/wp-01273-finding-an-efficient-virtual-network-function-architecture.pdf
(原文最早于2017年8月发表在老石的个人博客“老石谈芯” https://xiaotanzhong.github.io/。欢迎扫描下方二维码关注公众号)
