一文搞懂spark中shuffle原理,基于最新版本spark3.0.0源码分析
文章目录
- 前言
- spark中shuffle机制
- 1 shuffleReader读取数据
- 2 shuffleWriter写数据
- 2.1 shuffle具体写操作
- 3 shuffle的分类
- 3.1 HashShuffle
- 3.1.1 未优化的HashShuffle
- 3.1.2优化的HashShuffle
- 3.2 SortShuffle
- 3.2.1 普通SortShuffle
- 3.2.2 bypass SortShuffle
- 3.2.3 SortShuffle的管理
- shuffleWriter划分总结:
前言
在执行Task过程中,我们知道有的算子会造成数据的打乱重组,即在这个过程中我们需要将数据落盘并且下一阶段会将数据读取,我们把整个过程叫做shuffle
就像我们之前学的hadoop中MapReduce差不多,也会有个shuffle阶段,还记得我们当时MapReduce的shuffle是怎么操作的吗?
如果不记得的,可以看一下我之前写的一篇关于MapReduce中shuffle的文章
【hadoop中MR的shuffle阶段源码分析】
好了废话不多说了,我们今天就来谈谈spark底层关于shuffle是怎么操作的以及它与hadoop中MapReduce的shuffle有什么区别
先赞后看,养成好习惯!

spark中shuffle机制
在划分stage时,最后一个stage称为finalStage(其实就是一个变量名,我们在源码中看到过),它本质上是一个ResultStage对象,前面的所有stage被称为ShuffleMapStage。
ShuffleMapStage的结束伴随着shuffle文件的写磁盘,并且当有多个ShuffleMapStage时肯定也会有读取磁盘数据的操作。
ResultStage基本上对应代码中的action算子,即将一个函数应用在RDD的各个partition的数据集上,意味着一个job的运行结束。
spark中shuffle也借鉴MapReduce的shuffle,有两个阶段map和reduce,注意这只是逻辑思路中的,和我们的map和reduce算子没有一点关系
1 shuffleReader读取数据
因为我们的Task都是发送到Executor端进行执行计算,所以我们先进入CoarseGrainedExecutorBackend类中的receive方法中
case LaunchTask(data) =>
if (executor == null) {
exitExecutor(1, "Received LaunchTask command but executor was null")
} else {
val taskDesc = TaskDescription.decode(data.value)
logInfo("Got assigned task " + taskDesc.taskId)
taskResources(taskDesc.taskId) = taskDesc.resources
executor.launchTask(this, taskDesc)
}
如果executor不为空则,进入launchTask方法
def launchTask(context: ExecutorBackend, taskDescription: TaskDescription): Unit = {
val tr = new TaskRunner(context, taskDescription)
runningTasks.put(taskDescription.taskId, tr)
threadPool.execute(tr)
}
class TaskRunner(
execBackend: ExecutorBackend,
private val taskDescription: TaskDescription)
extends Runnable
我们可以看到将我们的Task任务封装为TaskRunner对象,又通过一个线程池来执行我们的任务线程
所以我们大概应该知道,我们的Task任务肯定会有一个run方法,因为封装为TaskRunner的类继承了Runnable
我们又知道了,我们在ShuffleMapStage阶段中的创建ShuffleMapTask,在ResultStage阶段创建了ResultTask
ShuffleMapStage阶段就是rdd产生shuffle操作,所以划分的,所以ResultStage生成的Task肯定会读取数据
我们进入ResultTask中
我们发现没有run方法,只有runTask方法,按道理是不可能的,所以我们进入它的父类看看,果然有run方法
try {
runTask(context)
} catch {
case e: Throwable =>
// Catch all errors; run task failure callbacks, and rethrow the exception.
try {
context.markTaskFailed(e)
} catch {
case t: Throwable =>
e.addSuppressed(t)
}
context.markTaskCompleted(Some(e))
throw e
}
我们发现该run方法是final修饰的,子类是不能重写的,但是在里面调用了runTask方法,这就是模板方法设计模式
我们进入runTask方法
func(context, rdd.iterator(partition, context))
final def iterator(split: Partition, context: TaskContext): Iterator[T] = {
if (storageLevel != StorageLevel.NONE) {
//如果存储等级不为空,则调用getOrCompute方法
getOrCompute(split, context)
} else {
computeOrReadCheckpoint(split, context)
}
}
进入getOrCompute方法
computeOrReadCheckpoint(partition, context)
private[spark] def computeOrReadCheckpoint(split: Partition, context: TaskContext): Iterator[T] =
{
if (isCheckpointedAndMaterialized) {
firstParent[T].iterator(split, context)
} else {
compute(split, context)
}
}
我们进入compute方法
发现方法是抽象的,我们要找其实现类,因为进行了shuffle所以肯定是ShuffleRDD,所以进入ShuffleRDD的
compute方法
override def compute(split: Partition, context: TaskContext): Iterator[(K, C)] = {
val dep = dependencies.head.asInstanceOf[ShuffleDependency[K, V, C]]
val metrics = context.taskMetrics().createTempShuffleReadMetrics()
//spark的环境获取的shuffle管理器获取了reader并调用read方法
SparkEnv.get.shuffleManager.getReader(
dep.shuffleHandle, split.index, split.index + 1, context, metrics)
.read()
.asInstanceOf[Iterator[(K, C)]]
}
我们可以看到这个shuffle管理器获取reader对象之后调用了read方法
2 shuffleWriter写数据
ShuffleMapStage的结束伴随着shuffle文件的写磁盘,所以最后ShuffleMapTask肯定会有写数据的操作
我们进入ShuffleMapTask的run方法
和读取数据一样,是一个模板方法涉及模式,所以我们进入runTask方法
dep.shuffleWriterProcessor.write(rdd, dep, mapId, context, partition)
进入write方法
var writer: ShuffleWriter[Any, Any] = null
try {
//创建shuffle管理器
val manager = SparkEnv.get.shuffleManager
//获取writer对象
writer = manager.getWriter[Any, Any](
dep.shuffleHandle,
mapId,
context,
createMetricsReporter(context))
//调用write方法
writer.write(
rdd.iterator(partition, context).asInstanceOf[Iterator[_ <: Product2[Any, Any]]])
创建shuffle管理器然后获取Writer对象调用write方法,这就开始写操作了
我们应该可以知道ShuffleMapStage阶段之前也可以有ShuffleMapStage阶段所以,并不会只有write方法,肯定应该也有read方法,再仔细看write方法里面
writer.write(
rdd.iterator(partition, context).asInstanceOf[Iterator[_ <: Product2[Any, Any]]])
和上面ResultTask的何其相似,都是调用的rdd的iterator方法,我们可以知道,在写数据之前会先进行读取操作,当然如果没有就说明是自开始阶段,也就是数据来源是内存或者外部存储
2.1 shuffle具体写操作
我们进入write方法
//创建mapOutputWriter对象,内部是对数据的规划以及分区的规划
val mapOutputWriter = shuffleExecutorComponents.createMapOutputWriter(
dep.shuffleId, mapId, dep.partitioner.numPartitions)
//排序器对已经分好区的数据进行写操作
sorter.writePartitionedMapOutput(dep.shuffleId, mapId, mapOutputWriter)
//提交所有的分区
val partitionLengths = mapOutputWriter.commitAllPartitions()
我们看最后提交的方法commitAllPartitions
blockResolver.writeIndexFileAndCommit(shuffleId, mapId, partitionLengths, resolvedTmp);
接下来方法我们重点来看
def writeIndexFileAndCommit(
shuffleId: Int,
mapId: Long,
lengths: Array[Long],
dataTmp: File): Unit = {
//创建索引文件
val indexFile = getIndexFile(shuffleId, mapId)
//创建索引文件的临时文件
val indexTmp = Utils.tempFileWith(indexFile)
try {
//创建数据文件
val dataFile = getDataFile(shuffleId, mapId)
synchronized {
//检查索引文件和数据文件
//如果索引文件第一个元素不为0L则返回null或者数据文件的长度等于所有块大小就返回null
val existingLengths = checkIndexAndDataFile(indexFile, dataFile, lengths.length)
if (existingLengths != null) {
System.arraycopy(existingLengths, 0, lengths, 0, lengths.length)
//如果索引临时文件不为空且存在就删除
if (dataTmp != null && dataTmp.exists()) {
dataTmp.delete()
}
else{
//如果索引文件存在就删除
if (indexFile.exists()) {
indexFile.delete()
}
//如果数据文件存在就删除
if (dataFile.exists()) {
dataFile.delete()
}
//将索引临时文件改名为索引文件
if (!indexTmp.renameTo(indexFile)) {
throw new IOException("fail to rename file " + indexTmp + " to " + indexFile)
}
if (dataTmp != null && dataTmp.exists() && !dataTmp.renameTo(dataFile)) {
throw new IOException("fail to rename file " + dataTmp + " to " + dataFile)
}
}
}
我们仔细看完整个写入磁盘的流程,发现就是创建一个索引文件,索引临时文件和数据文件,然后就是对索引文件和数据文件的删除以及将索引临时文件改名为索引文件
看到这个流程是不是觉得有点熟悉,我们曾经在哪个框架看到过,没错,就是kafka,kafka也会生成一个索引文件和数据文件,用来保证数据的大吞吐量,所以这也是为什么说spark比hadoop要快那么多的原因了,不仅在别的地方进行了优化,对于shuffle落盘也进行了优化,保证数据的快速读取
3 shuffle的分类
3.1 HashShuffle
3.1.1 未优化的HashShuffle
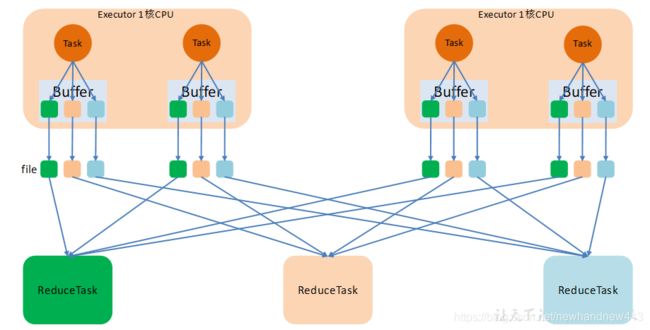
以Task为单位,我们可以看到每个Task都必须生成相同Reducer个数的文件,索引当Task比较多时,我们需要生成很多个文件,我们要知道大数据对多个小文件是非常拒绝的,所以我们需要进行优化
3.1.2优化的HashShuffle

现在我们是以CPU为单位,每个核只需要生成相同reducer 个数的文件就行,不管一个核中有多少个Task,但是我们仔细思考其实还是有很大缺陷的,当我们集群核数比较多,并且Reducer也比较多的时候文件其实还是会很多,而文件过多会进行过多的磁盘IO以及网络IO,非常消耗性能
3.2 SortShuffle
3.2.1 普通SortShuffle

正如我们之前看到那样,我们spark现在使用的就是SortShuffle,只会生成两个文件,一个索引文件,一个数据文件,通过索引文件来快速查找在数据文件中位置,但是我们要考虑到一些特殊情况,当我们数据量不是非常大的时候,做排序操作其实是很消耗性能的,当数据量不是很大时,我们能不能不用sort,而用另一种方式代替呢?
3.2.2 bypass SortShuffle
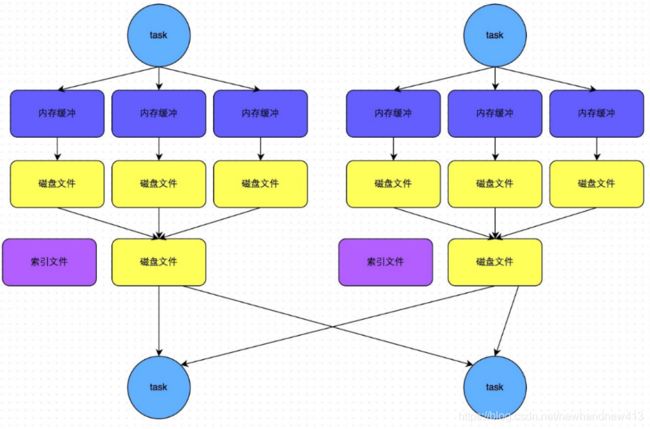
结合了hashshuffle的一些特性,即当数据量不是很大时候,不需要对数据进行排序,对数据进行hash分区存储即可,和hashMap一样,当数据量不是很大时,其实hash的性能会更好一点
3.2.3 SortShuffle的管理
说了那么多,我们来实际看看spark底层是怎么控制和调用到底使用哪个SortShuffle呢?
下面进入大家最喜欢的源码环节
在上面shuffleWriter写数据阶段时,我们已经分析到具体怎么写操作的了,我们直接进入ShuffleMapTask类的runTask方法中
dep.shuffleWriterProcessor.write(rdd, dep, mapId, context, partition)
def write(
rdd: RDD[_],
dep: ShuffleDependency[_, _, _],
mapId: Long,
context: TaskContext,
partition: Partition): MapStatus = {
var writer: ShuffleWriter[Any, Any] = null
try {
val manager = SparkEnv.get.shuffleManager
writer = manager.getWriter[Any, Any](
dep.shuffleHandle,
mapId,
context,
createMetricsReporter(context))
//我们知道这里就是调用写操作了
writer.write(
rdd.iterator(partition, context).asInstanceOf[Iterator[_ <: Product2[Any, Any]]])
writer.stop(success = true).get
我们进入write方法,发现
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-t6W6unJI-1596263606563)(C:\Users\15907\Desktop\流程或源码分析\imgs\QQ截图20200801114134.png)]
有三个实现类,此时就是需要考虑到底使用哪个实现类的write方法了,所以我们回退到之前方法,应该是ShuffleManager创建writer的时候应该就已经判断好了
我们回退到之前的方法
val manager = SparkEnv.get.shuffleManager
writer = manager.getWriter[Any, Any](
dep.shuffleHandle,
mapId,
context,
createMetricsReporter(context))
override def getWriter[K, V](
handle: ShuffleHandle,
mapId: Long,
context: TaskContext,
metrics: ShuffleWriteMetricsReporter): ShuffleWriter[K, V] = {
val mapTaskIds = taskIdMapsForShuffle.computeIfAbsent(
handle.shuffleId, _ => new OpenHashSet[Long](16))
mapTaskIds.synchronized { mapTaskIds.add(context.taskAttemptId()) }
val env = SparkEnv.get
handle match {
case unsafeShuffleHandle: SerializedShuffleHandle[K @unchecked, V @unchecked] =>
new UnsafeShuffleWriter(
env.blockManager,
context.taskMemoryManager(),
unsafeShuffleHandle,
mapId,
context,
env.conf,
metrics,
shuffleExecutorComponents)
case bypassMergeSortHandle: BypassMergeSortShuffleHandle[K @unchecked, V @unchecked] =>
new BypassMergeSortShuffleWriter(
env.blockManager,
bypassMergeSortHandle,
mapId,
env.conf,
metrics,
shuffleExecutorComponents)
case other: BaseShuffleHandle[K @unchecked, V @unchecked, _] =>
new SortShuffleWriter(
shuffleBlockResolver, other, mapId, context, shuffleExecutorComponents)
}
}
我们发现了是通过传递的handle参数的类型进行的模式匹配,并进行相应的操作,匹配到就创建相应的SortShuffleWriter对象,后面再调用相对应实现类的write方法
我们往回找最早之前传递handle参数,并给handle参数赋值的方法
writer = manager.getWriter[Any, Any](
dep.shuffleHandle,
mapId,
context,
createMetricsReporter(context))
val shuffleHandle: ShuffleHandle = _rdd.context.env.shuffleManager.registerShuffle(
shuffleId, this)
override def registerShuffle[K, V, C](
shuffleId: Int,
dependency: ShuffleDependency[K, V, C]): ShuffleHandle = {
if (SortShuffleWriter.shouldBypassMergeSort(conf, dependency)) {
new BypassMergeSortShuffleHandle[K, V](
shuffleId, dependency.asInstanceOf[ShuffleDependency[K, V, V]])
} else if (SortShuffleManager.canUseSerializedShuffle(dependency)) {
new SerializedShuffleHandle[K, V](
shuffleId, dependency.asInstanceOf[ShuffleDependency[K, V, V]])
} else {
new BaseShuffleHandle(shuffleId, dependency)
}
}
我们来分别分析这几种情况
1)第一种情况
if (SortShuffleWriter.shouldBypassMergeSort(conf, dependency)) {
new BypassMergeSortShuffleHandle[K, V](
shuffleId, dependency.asInstanceOf[ShuffleDependency[K, V, V]])
}
private[spark] val SHUFFLE_SORT_BYPASS_MERGE_THRESHOLD =
ConfigBuilder("spark.shuffle.sort.bypassMergeThreshold")
.doc("In the sort-based shuffle manager, avoid merge-sorting data if there is no " +
"map-side aggregation and there are at most this many reduce partitions")
.version("1.1.1")
.intConf
.createWithDefault(200)
def shouldBypassMergeSort(conf: SparkConf, dep: ShuffleDependency[_, _, _]): Boolean = {
// We cannot bypass sorting if we need to do map-side aggregation.
//如果需要进行map端的聚合,则无法绕过排序,返回false
if (dep.mapSideCombine) {
false
} else {
val bypassMergeThreshold: Int = conf.get(config.SHUFFLE_SORT_BYPASS_MERGE_THRESHOLD)
//分区数小于等于200
dep.partitioner.numPartitions <= bypassMergeThreshold
}
}
2)第二种情况
else if (SortShuffleManager.canUseSerializedShuffle(dependency)) {
// Otherwise, try to buffer map outputs in a serialized form, since this is more efficient:
new SerializedShuffleHandle[K, V](
shuffleId, dependency.asInstanceOf[ShuffleDependency[K, V, V]])
}
def canUseSerializedShuffle(dependency: ShuffleDependency[_, _, _]): Boolean = {
val shufId = dependency.shuffleId
val numPartitions = dependency.partitioner.numPartitions
// private[spark] def supportsRelocationOfSerializedObjects: Boolean = false
if (!dependency.serializer.supportsRelocationOfSerializedObjects) {
false
//如果需要进行map端的聚合,则无法绕过排序,返回false
} else if (dependency.mapSideCombine) {
false
// static final int MAXIMUM_PARTITION_ID = (1 << 24) - 1; // 16777215
// val MAX_SHUFFLE_OUTPUT_PARTITIONS_FOR_SERIALIZED_MODE =
// PackedRecordPointer.MAXIMUM_PARTITION_ID + 1
} else if (numPartitions > MAX_SHUFFLE_OUTPUT_PARTITIONS_FOR_SERIALIZED_MODE) {
false
//其他情况下都为true
} else {
true
}
}
3)第三种情况
else {
// Otherwise, buffer map outputs in a deserialized form:
new BaseShuffleHandle(shuffleId, dependency)
}
上面情况不满足的情况下,就是BaseShuffleHandle,也就是SortShuffleWriter
shuffleWriter划分总结:
1)当需要进行map端聚合的情况下,返回false,其他情况都返回true,即创建BypassMergeSortShuffleWriter
2) ①当序列化器不支持序列化对象的搬迁,返回false
②当map端需要进行聚合时,返回false
③当总分区数大于16777215+1时,返回false
④其他情况都不满足时,返回true ,即创建UnsafeShuffleWriter
3)当上面两种情况都不满足的情况下,创建SortShuffleWriter
自此,spark一系列的源码分析就到此结束了,小伙伴如果有什么不懂的地方欢迎评论区留言,如果spark中还有什么地方想了解的欢迎私信我,如果觉得写的不错,点个赞再走