该系列合集会同步发布于 GitHub HomePage
目录
SVD算法
如何求出SVD分解后的U,Σ,V这三个矩阵?
SVD的一些性质
从文本分类的角度理解SVD分解所得三个矩阵的含义
SVD用于PCA降维
1. SVD算法
矩阵A可以如下分解成三个矩阵的乘积:
其中X是一个酉矩阵 (Unitary Matrix),Y则是一个酉矩阵的共轭矩阵
与其共轭矩阵转置相乘等于单位阵的矩阵是酉矩阵,因此酉矩阵及其共轭矩阵都是方阵
B是一个对角阵,即只有对角线上是非0值
维基百科上给出了下面的例子:
那么如何进行奇异值分解呢?
一般分两步进行:
(1)将矩阵A变换成一个双对角矩阵(除了两行对角线元素非零,剩下的都是零),这个过程的计算量为,如果矩阵是稀疏的,那么可以大大缩短计算时间;
(2)将双对角矩阵变成奇异值分解的三个矩阵。这一步的计算量只是第一步的零头;
奇异值分解的一个重要目的是进行数据的低维度表示,即将 转换为
直观一点的:

降维表示:
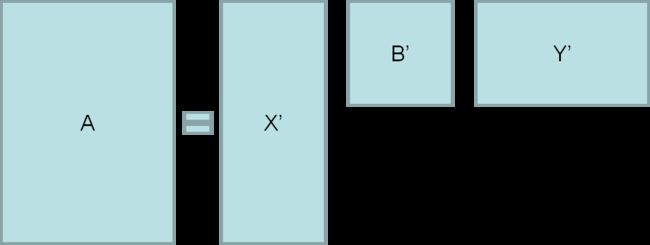
如何从原始的矩阵分解结果得到它的降维表示呢?为什么可以这么做?
由于对角矩阵B的对角线上的元素的很多值相对于其他的值非常小,或者干脆为0,故而可以省略,例如,当B为如下情况时:
则可以对B进行简化,省略都是0的行和列,得到B':
那么想对应地,X保留前n列,Y保留前n行
2. 如何求出SVD分解后的U,Σ,V这三个矩阵?
对于下面表示形式的奇异值分解
如果我们将A的转置和A做矩阵乘法,那么会得到n×n的一个方阵。既然是方阵,那么我们就可以进行特征分解,得到的特征值和特征向量满足下式
这样我们就可以得到矩阵的n个特征值和对应的n个特征向量v了。将ATA的所有特征向量张成一个n×n的矩阵V,就是我们SVD公式里面的矩阵了。一般我们将V中的每个特征向量叫做A的右奇异向量
如果我们将A和A的转置做矩阵乘法,那么会得到m×m的一个方阵。既然是方阵,那么我们就可以进行特征分解,得到的特征值和特征向量满足下式:
这样我们就可以得到矩阵的m个特征值和对应的m个特征向量u了。将AAT的所有特征向量张成一个m×m的矩阵U,就是我们SVD公式里面的矩阵了。一般我们将U中的每个特征向量叫做A的左奇异向量
U和V我们都求出来了,现在就剩下奇异值矩阵没有求出了
由于除了对角线上是奇异值其他位置都是0,那我们只需要求出每个奇异值就可以了
由于
这样我们可以求出我们的每个奇异值,进而求出奇异值矩阵
那么为什么说的特征向量组成的就是我们SVD中的矩阵,而的特征向量组成的就是我们SVD中的矩阵?
以矩阵的证明为例
上式证明使用了:,
可以看出的特征向量组成的的确就是我们SVD中的矩阵。类似的方法可以得到的特征向量组成的就是我们SVD中的矩阵
进一步我们还可以看出我们的特征值矩阵等于奇异值矩阵的平方,也就是说特征值和奇异值满足如下关系:
这样就可以不用 来计算奇异值,也可以通过求出的特征值取平方根来求奇异值
3. SVD的一些性质
对于奇异值,它跟我们特征分解中的特征值类似,在奇异值矩阵中也是按照从大到小排列,而且奇异值的减少特别的快,在很多情况下,前10%甚至1%的奇异值的和就占了全部的奇异值之和的99%以上的比例
也就是说,我们也可以用最大的k个的奇异值和对应的左右奇异向量来近似描述矩阵
由于这个重要的性质,SVD可以用于
PCA降维,来做数据压缩和去噪;
推荐算法,将用户和喜好对应的矩阵做特征分解,进而得到隐含的用户需求来做推荐;
NLP中的算法,比如潜在语义索引(LSI)
4. 从文本分类的角度理解SVD分解所得三个矩阵的含义
用一个打矩阵来表示成千上万篇文章和几十上百万个词的关联性
在这个矩阵中,每行表示一个词,每列表示一篇文章,如果有M篇文章,N个词,则可以得到一个MxN的矩阵:
其中表示的是第j篇文章的第i个词的加权词频(比如用词的TF-IDF)。一般来说这个矩阵会非常非常大
对A进行奇异值分解后:
原始矩阵A的元素个数为,奇异值分解后得到的上小矩阵的元素总是为,一般情况下,这使得数据的存储量和计算量都远小于原始矩阵
这三个矩阵都有非常清晰的物理含义:
-
矩阵X
矩阵X是对词进行分类的结果,它的每一行表示一个词,每一列表示一个语义相近的词类,或者称为语义类
这一行的每个非零元素表示这个词在每个语义类的重要性(或者说是相关性),例如:
则第一个词与第一个词类最相关,而与第二个此类的关系比较弱,以此类推
-
矩阵Y
矩阵Y是对文本的分类结果,它的每一列对应一篇文章,每一行对应一个文章主题
这一列的每个非零元素表示这篇文章在每个的主题重要性(或者说是相关性),例如:
则第一篇文章很明显属于第一个主题,第二篇文章和第二个主题很相关,以此类推
-
矩阵B
中间的矩阵则表示词的类和文章的类之间的相关性,例如
则第一个词的语义类与第一个主题相关,而第二个主题相关性较弱,而第二个词的语义类则相反
5. SVD用于PCA降维
用PCA降维,需要找到样本协方差矩阵的最大的d个特征向量,然后用这最大的d个特征向量张成的矩阵来做低维投影降维。可以看出,在这个过程中需要先求出协方差矩阵,当样本数多样本特征数也多的时候,这个计算量是很大的
回顾上面SVD的计算过程,我们可以发现:求的d个最大的特征值对应的特征向量张成的矩阵,其实相当于对进行奇异值分解得到右奇异矩阵
SVD有个好处,有一些SVD的实现算法可以不求先求出协方差矩阵,也能求出我们的右奇异矩。也就是说,我们的PCA算法可以不用做特征分解,而是做SVD来完成,这个方法在样本量很大的时候很有效
实际上,scikit-learn的PCA算法的背后真正的实现就是用的SVD,而不是我们我们认为的暴力特征分解
另一方面,注意到PCA仅仅使用了我们SVD的右奇异矩阵,没有使用左奇异矩阵,那么左奇异矩阵有什么用呢?
假设我们的样本是m×n的矩阵X,如果我们通过SVD找到了矩阵最大的d个特征向量张成的m×d维矩阵,则我们如果进行如下处理:
可以得到一个d×n的矩阵,这个矩阵和我们原来的m×n维样本矩阵X相比,行数从m减到了d,可见对行数进行了压缩。也就是说,左奇异矩阵可以用于行数的压缩。相对的,右奇异矩阵可以用于列数即特征维度的压缩,也就是我们的PCA降维。
参考资料:
(1) 吴军《数学之美(第二版)》
(2) 刘建平Pinard《奇异值分解(SVD)原理与在降维中的应用》