android 国际化之Locale
一、Locale
Locale对象表示了一个特定的地理,政治或文化区域。需要使用到Locale执行其任务的操作称为区域设置敏感,并使用Locale为用户定制信息。例如显示一个数字就是一个区域设置敏感的操作–该数字应根据用户所在国家,地区或文化的习俗和惯例进行格式化。
Android Locale类实现了IETF BCP 47标准 (它由RFC 4647“匹配语言标签”和RFC 5646“识别语言标签”组成,支持LDML(UTS#35,“Unicode语言环境数据标记语言”)) BCP 47兼容 区域数据交换的扩展。
1.1、IETF BCP 47 language Tag
一个IETF BCP 47 language tag 是一个用于识别人类语言的代码。例如 en 这个tag代表英语,es-419表示拉美西班牙语; nan-Hant-TW 表示闽南华人在台湾地区用繁体中文字符。为了区分国家,地区,文字等的语言变体,IETF language tags 结合了其他标准的子标签,如ISO 639,ISO 15924,ISO 3166-1和UN M.49。这些tag结构已由互联网工程任务组(IETF)在最佳实践(BCP)47中标准化; 这些子标签由IANA语言子标签注册管理机构维护,IANA语言子标签注册表。
1.2、BCP47 标准简要介绍
BCP 47, RFC 5646 官方文档:链接
对应的中文翻译文档:链接
语言标签ABNF
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 |
Language-Tag = langtag ; 普通语言标签 / privateuse ; 私有标签 / grandfathered ; 继承标签,用于兼容
langtag = language ; 语言 ["-" script] ; 书写 ["-" region] ; 区域 *("-" variant) ; 变体 *("-" extension) ; 扩充 ["-" privateuse] ; 私有 language = 2*3ALPHA ; 最短 ISO 639 代码 ["-" extlang] ; 方言子标签 / 4ALPHA ; 或保留供将来使用 / 5*8ALPHA ; 或注册为语言子标签 extlang = 3ALPHA ; 选择 ISO 639 代码 *2("-" 3ALPHA) ; 永久保留 script = 4ALPHA ; ISO 15924 代码 region = 2ALPHA ; ISO 3166-1 代码 / 3DIGIT ; UN M.49 代码 variant = 5*8alphanum ; 变体 / (DIGIT 3alphanum) extension = singleton 1*("-" (2*8alphanum)) ; 单字母「x」保留供私有使用 singleton = DIGIT ; 0 - 9 / %x41-57 ; A - W / %59-5A ; Y - Z / %61-77 ; a - w / %79-7A ; y - z privateuse = "x" 1*("-" (1*8alphaunm)) grandfathered = irregular ; 已注册的非冗余标签 / regular ; 在「RFC 3066」中 irregular = "en-GB-oed" ; 「irregular」标签与「langtag」并不匹配,不被视为正确格式。 / "i-ami" ; 这些标签都是有效的,但大多数已被弃用,建议使用更现代的子标签或子标签组合。 / "i-bnn" ; / "i-default" ; / "i-enochian" ; / "i-hak" ; / "i-klingon" ; / "i-lux" ; / "i-mingo" ; / "i-navajo" ; / "i-pwn" ; / "i-tao" ; / "i-tay" ; / "i-tsu" ; / "sgn-BE-FR" ; / "sgn-BE-NL" ; / "sgn-CH-DE" ; regular = "art-lojban" ; 「regular」标签与「langtag」相匹配,但它们的子标签不是方言或变体子标签。 / "cel-gaulish" ; 由它们的注册定义决定其含义,所有这些标签在现代子标签或子标签组合中被弃用。 / "no-bok" ; / "no-nyn" ; / "zh-guoyu" ; / "zh-hakka" ; / "zh-min" ; / "zh-min-nan" ; / "zh-xiang" ; alphanum = (ALPHA / DIGIT) ; 字母和数字 |
上面的结构我们看的出来一个标准的langtag由language, script, region, variant, extension, privateuse 组成。下面分别介绍一下这个子标签。
1.3、Android Locale对象逻辑上由下面描述的字段组成:
language
1)对于language子标签在Android的描述如下:
ISO 639 alpha-2 或者 alpha-3 语言代码,或IANA语言子标签注册表里面多达8个字母(为将来增强)。当language同时具有alpha-2和alpha-3语言代码时,必须使用alpha-2代码。您可以在IANA语言子标签注册表中找到有效语言代码的完整列表(搜索:”Type: language”)。该language字段是不区分大小写的,但Locale总是规范化为小写。如下图所示:

格式良好的language值是这样的格式[a-zA-Z]{2,8}, 请注意,这不是完整的BCP47语言生成,因为它不包括extlang。由于现代三字母语言代码取代它们,因此不需要它们。例如:“en”(英语),“ja”(日语),“kok”(Konkani)
可以看出android的language 子标签可以为单独的ISO 639 alpha-2或者ISO 629 alpha-3组成,也可以是一个IANA注册子标签。我们在看下IANA注册子标签中language子标签的描述:
简单的说language子标签它是最短 ISO 639 代码, 详细解释为:
当语言同时存在于 ISO 639-1 2字符代码和 3字符代码(由 ISO 639-2、ISO 639-3、ISO 639-5分配)时,只有ISO 639-1 2字符代码是在「IANA 注册表」中定义。
当语言没有 ISO 639-1 2字符代码,同时该语言的 ISO 639-2/T(技术用) 代码和 ISO 639-2/B(书目用) 代码不同,只有技术用代码是在「IANA 注册表」中定义。在本文档创建时,所有具有 3字符代码的语言也分配了 2字符代码,所以预计这个问题未来不会发生。
总结一句话的意思是当某一种语言同时可以用ISO 639-2等和ISO 639-1表示时,优先使用ISO 639-1,因为ISO 639-1是由2个字符组成的,而ISO 639-2等是由3个字符组成的,依照language 子标签取最短ISO 639代码的规则,它会优先取最短的两个字符的ISO 639-1的代码。
举一个实际的栗子:
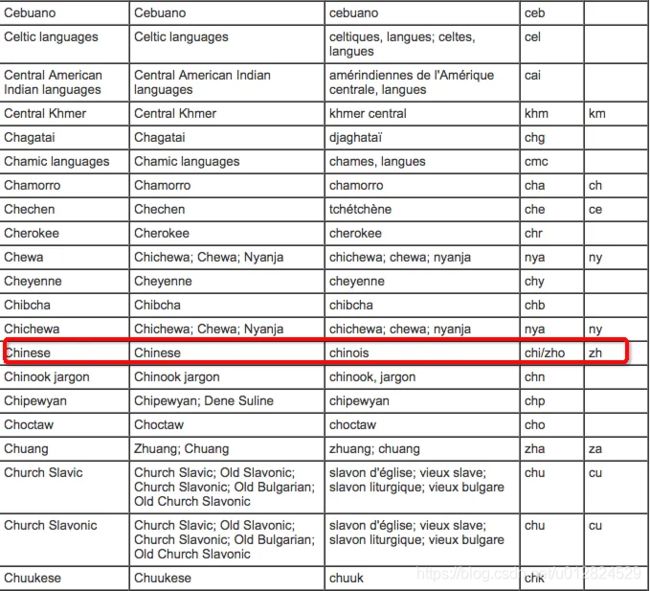
各个语言的ISO 639代码映射表:链接
上面的映射表中以中文语言为例,我们看到ISO 639-2的代码为chi或zho,而ISO 639-1的代码为zh,按照BCP 47(IANA注册子标签)的格式标准要求,此时中文语言应该取zh.
对照一下IOS 平台语言标签的格式要求:
IOS官方描述:链接
可以看出IOS对language语言标签的定义和android基本是一致的,它会在ISO 639-2和ISO 639-1都存在时取最短的那一个。

script
遵循ISO 15924 alpha-4规范。您可以在IANA语言子标签注册表中找到有效语言代码的完整列表(搜索:”Type: script”)。该script字段是不区分大小写的,但Locale总是规范化为标题大小写(第一个字母是大写,其它字母是小写)。如下图所示:
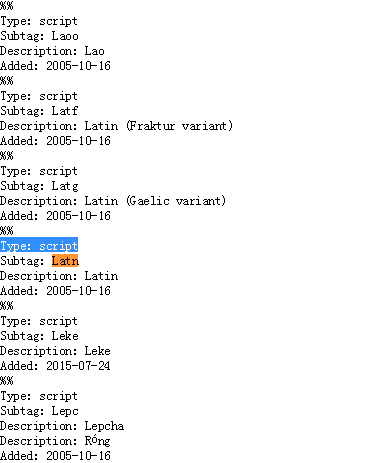
格式良好的script值是这样的格式[a-zA-Z]{4}
例如:“Latn”(拉丁文),“Cyrl”(西里尔文)
country (region)
ISO 3166 alpha-2国家代码或UN M.49数字-3区号。您可以在IANA语言子标签注册表中找到有效语言代码的完整列表(搜索:”Type: region”)。该country (region)字段是不区分大小写的,但Locale总是规范化为大写。如下图所示:
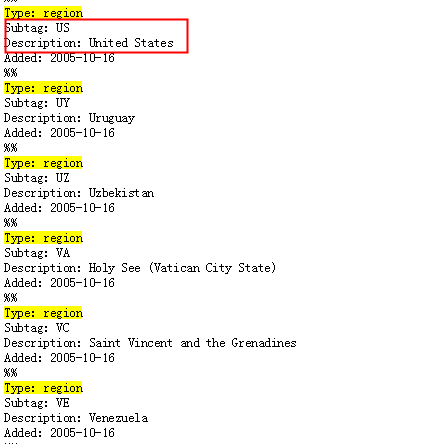
格式良好的country/region值是这样的格式[a-zA-Z]{2} | [0-9]{3}
例如:“US”(美国),“FR”(法国),“029”(加勒比)
在BCP 47中该子标签的规则要求:
- 区域子标签 必须 跟在主要、方言及书写子标签之后,必须 先于其他类型子标签之前;
- 「2 字母 区域子标签」根据「ISO 3166-1」 (Codes for the representation of names of countries and their subdivisions — Part 1: Country codes)2字母地区代码列表分配进行定义,或由 ISO 3166-1 注册机构及标准化管理机构作出的分配。此外,「注册表」也定义了「例外保留」的代码,其中除去「UK」,因其与「GB」同样对应英国;
- 区域子标签「AA」「QM-QZ」「XA-XZ」「ZZ」在语言标签中被保留为私有用途,这些子标签对应的 ISO 3166 代码也保留供私有使用(而不是使用专用的子标签系列 )。有关私有子标签的更多信息,见第 4.6 节;
- 「3 字符 区域子标签」仅由数字字符(0-9)组成,根据联合国统计局统计用国家地区代码「UN M.49」分配进行定义,或由标准化管理机构作出的分配。不是所有的 UN M.49 代码都在「IANA 注册表」进行定义,以下规则将哪些代码定义为注册表中的有效子标签:
- 联合国数字代码中,分配给「宏观地理(大陆)」或子区域的部分 必须 在注册表中注册,这些代码与 ISO 3166-1 alpha-2 代码无关,代表超国家地区——通常覆盖多个国家、州、省或领地;
- 联合国数字代码中,分配给「经济组」或「其他组」 必须不能 在注册表中注册,必须不能用于构成语言标签;
- 当 ISO 3166-1 将以前用于一个国家或地区的代码重新分配给另一个国家或地区,而代码已经存在于注册表中时,该国家或地区的联合国数字代码 必须 按第 3.4 节中所述在注册表中注册,必须 用于表示其定义的国家或地区的语言标签(而不是收回 ISO 3166-1 代码);
- 联合国数字代码中,分配给已经在注册表中注册的 ISO 3166-1 alpha-2 代码对应的区域 必须不能 在注册表中注册,必须不能 用于构成语言标签。注意注册表中的基于 ISO 3166 子标签实际上 必须 与所讨论的 UN M.49 代码相关联;
- 由于历史原因,联合国数字代码 830(海峡群岛)在本文件通过时没有注册,在当时也没有对应的 ISO 3166-1 代码,可以 通过第 3.5 节中所述过程加入 IANA 注册表,在没有 ISO 3166-1 代码和精确含义之前注册;
- 其他联合国数字代码,分配给没有相关 ISO 3166-1 alpha-2 代码对应的区域 必须不能 在注册表中注册,必须不能 用于构成语言标签。更多代码相关信息,见第 3.4 节;
- 联合国文件附录 X 中的字母数字代码 必须不能 在注册表中注册,必须不能 用于构成语言标签(本文档创建时,这些值与 ISO 3166-1 alpha-2 代码相符合);
- 区域子标签 必须 最多只有一个。区域子标签 可以 在没有区分的必要时被省略。
例如:
- 『de-AT』代表德语,用于奥地利;
- 『sr-Latn-RS』代表塞尔维亚语,采用拉丁字母书写,用于塞尔维亚;
- 『es-419』代表西班牙语,用于联合国界定的拉丁美洲和加勒比地区。
variant
变体子标签用于指示附加的、公认的方言,定义一种不被其他子标签代表的语言。如果有两个或更多个变体值表示它们自己的语义,则这些值应按重要性排序,最重要的排第一个,用下划线(’_’)分隔。 变体字段区分大小写。
注意:IETF BCP 47将语法限制放在变体子标签上。此外,BCP 47子标签严格用于表示额外的变体,这些变体定义了语言或其方言,但不包含语言,脚本和地区子标签的任何组合。
您可以在IANA语言子标签注册表中找到有效语言代码的完整列表(搜索:”Type: variant”)。然而,Locale中的variant字段历来被用于任何类型的变体,而不仅仅是语言变体。例如,Java SE运行时环境中可用的一些受支持的变体指示替代文化行为,如日历类型或编号脚本。在BCP 47中,这种不标识语言的信息由扩展子标签或私人使用子标签支持。
格式良好的variant值的形式为SUBTAG((’_’|’ – ‘)SUBTAG)*其中SUBTAG = [0-9] [0-9a-zA-Z] {3} |[0-9A-ZA-Z]{5,8}。 (注意:BCP 47只使用连字符(’ – ‘)作为分隔符,这比较宽松)。
例如:“Polyton”(Polytonic Greek),“POSIX”
在BCP 47中该子标签的规则要求:
- 变体子标签 必须 跟在主要、方言、书写及区域子标签之后,必须 先于扩充及私有子标签之前;
- 作为集合的变体子标签,与任何特定的外部标准无关。变体子标签的含义在「注册表」根据第 3.5 节定义的登录过程进行定义。注意某些特定变体的子标签可能与某些外部标准有关,但是不需要相关联;
- 变体子标签 可以 多个使用,用于构成语言标签;
- 变体子标签 必须 在使用前通过本文档第 3.5 节规定向 IANA 进行注册。为了区分变体子标签和其他标签,注册 必须 满足以下长度和内容限制:
- 以字母「A-Z,a-z」开头的变体子标签必须至少有 5个字符长;
- 以数字「0-9」开头的变体子标签必须至少有 4个字符长;
- 同一变体子标签不得在语言标签内多次使用。如『de-DE-1901-1901』是无效的。
变体子标签在注册表中 可以 包含一个或多个「前缀」字段(见第 3.1.8 节)。每个「前缀」字段表明变体子标签(与其他子标签)构成语言标签的顺序。
共享「前缀」的变体子标签大多数是互斥的。例如,德语正写法「1996」和「1901」 不应该 用于同一个语言标签中,因为它们代表了不同时期的拼写改革方案。变体子标签可以与另一个不同「前缀」的变体子标签结合,构成有意义的语言标签。例如,假设创建一个德语变体子标签「example」,将它与「1996」一起使用,那么「example」应该有 2个「前缀」字段:『de』和『de-1996』。
例如:
- 『sl-nedis』代表斯洛文尼亚语的 Natisone/Nadiza 方言变体;
- 『de-CH-1996』代表德语,用于瑞士,1996 年拼写改革方案。
extensions
从单个字符键到字符串值的映射,表明扩展名与语言标识不同。Locale中的扩展实现了BCP 47扩展子标签和专用子标签的语义和语法。扩展名不区分大小写,但Locale将所有扩展键和值标准化为小写。 请注意,扩展名不能包含空值。
格式良好的键值是集合[0-9a-zA-Z]中的单个字符。格式良好的值具有SUBTAG(’ – ‘SUBTAG)*形式,其中对于键’x’SUBTAG = [0-9a-zA-Z] {1,8}和其他键SUBTAG = [0-9a-zA -Z] {2,8}(也就是’x’允许单字符子标签)。例如:key =“u”/ value =“ca-japanese”(日文日历),key =“x”/ value =“java-1-7”
注意:虽然BCP 47要求字段值在IANA语言子标签注册表中注册,但Locale类不提供任何验证功能。Builder仅检查单个字段是否满足语法要求(是格式良好的),但不验证该值本身。有关详细信息,请参阅Locale.Builder。
二、Unicode区域设置/语言扩展
UTS#35,“Unicode区域设置数据标记语言”定义可选属性和关键字来覆盖或优化与区域设置关联的默认行为。 关键字由一对键和类型表示。 例如,“nu-thai”表示应使用泰国本地数字(值:“thai”)来格式化数字(键:“nu”)。
使用扩展名“u”(UNICODE_LOCALE_EXTENSION)将关键字映射到BCP 47扩展值。 上面的例子“nu-thai”成为“u-nu-thai”.code的扩展名。
因此,当Locale对象包含Unicode语言环境属性和关键字时,getExtension(UNICODE_LOCALE_EXTENSION)将返回表示此信息的字符串,例如“nu-thai”。Locale类还提供getUnicodeLocaleAttributes(),getUnicodeLocaleKeys()和getUnicodeLocaleType(String),它们允许您直接访问Unicode语言环境属性和键/类型对。当以字符串表示时,Unicode区域设置扩展按字母顺序列出属性,后跟按key字母顺序列出的key/type序列(按key类型的子标签顺序在定义时是固定的)
格式良好的区域设置key的格式为[0-9a-zA-Z] {2}。 格式良好的区域设置type的格式为“”| [0-9a-zA-Z] {3,8}(’ – ‘[0-9a-zA-Z] {3,8})*(它可以是空的,或者是一系列子标签3-8中的alphanums 长度)。 格式良好的区域设置attribute 的格式为[0-9a-zA-Z] {3,8}(它是一个与区域设置类型子标签具有相同形式的单个子标签)。
Unicode区域设置扩展指定区域敏感服务中的可选行为。 虽然LDML规范定义了各种键和值,但Java运行时环境中实际的区域设置敏感的服务实现可能不支持任何特定的Unicode区域设置属性或键/类型对。
三、构建一个Locale
有几种不同的方法来创建一个Locale对象。
Builder
使用Locale.Builder,您可以构建符合BCP 47语法的Locale对象。
构造函数
Locale类提供了三个构造函数:
| 1 2 3 |
Locale(String) Locale(String, String) Locale(String, String, String) |
这些构造函数允许您使用语言,国家和变体创建Locale对象,但不能指定脚本或扩展。
工厂类方法
forLanguageTag(String)方法为格式良好的BCP 47语言标记创建Locale对象。
Locale 常量
Locale类提供了许多便利的常量,您可以使用它们为常用语言环境创建Locale对象。 例如,以下内容为美国创建一个Locale对象:
| 1 |
Locale.US |
获取Locale信息
Android提供了多种方式获取当前的语言代码,以下为在Android4.1.2手机上面各方法的输出结果:
| 1 2 3 4 5 6 7 8 |
Locale.getDefault().getLanguage() ---> en Locale.getDefault().getISO3Language() ---> eng Locale.getDefault().getCountry() ---> US Locale.getDefault().getISO3Country() ---> USA Locale.getDefault().getDisplayCountry() ---> United States Locale.getDefault().getDisplayName() ---> English (United States) Locale.getDefault().toString() ---> en_US Locale.getDefault().getDisplayLanguage()---> English |
四、Locale匹配
如果应用程序或系统国际化并为多个Locale提供本地化资源,则有时需要查找符合每个用户特定偏好的一个或多个Locale(或语言标记)。 请注意,此语言环境匹配文档中的术语“language tag”可与“locale”互换使用。
为了将用户的首选语言环境与一组语言标签进行匹配,RFC 4647匹配语言标签定义了两种机制:过滤和查找。 过滤用于获取所有匹配的语言环境,而查找则是选择最匹配的语言环境。 匹配是不区分大小写的。 这些匹配机制在下面的章节中描述。
用户的偏好被称为语言优先级列表,并表示为语言范围列表。 语法上有两种语言范围:基本和扩展。 有关详细信息,请参阅Locale.LanguageRange。
过滤
过滤操作返回所有匹配的语言标记。它在RFC 4647中定义如下:“在过滤中,每种语言范围表示最小指定的语言标记(即具有最少数量的子标记的语言标记),这是可接受的匹配。匹配的标签集中的所有语言标签都将具有与语言范围相同或更多的子标签。语言范围中的每个非通配符子标签都会出现在每个匹配的语言标签中。“
有两种类型的过滤:对基本语言范围(称为“基本过滤”)进行过滤,对扩展语言范围进行过滤(称为“扩展过滤”)。根据给定的语言优先级列表中包含的语言范围,它们可能会返回不同的结果。 Locale.FilteringMode是一个参数,用于指定如何完成过滤。
查找
查找操作返回最匹配的语言标记。 它在RFC 4647中定义如下:“与过滤相比,每种语言范围代表最接近匹配的特定标签。根据用户的优先级找到的第一个匹配标签被认为是最接近的匹配项,这就是我们需要找到的那一项。”
例如,如果一个语言优先级列表按照优先顺序由两个语言范围“zh-Hant-TW”和“en-US”组成,则查找方法将逐步搜索下面的语言标记以找到最佳匹配语言标记。
| 1 2 3 4 5 |
1. zh-Hant-TW 2. zh-Hant 3. zh 4. en-US 5. en |
如果语言标记与上述语言范围完全匹配,则返回语言标记。
“*”是特殊的语言范围,查找时忽略它。
如果由于语言范围中包含的子标签’*’而导致多个语言标签匹配,则Iterator通过语言标签集合返回的第一个匹配语言标签将被视为最匹配的语言标签。
Android res Values 文件夹按照区域命名映射表:
链接
本文转载自http://www.huahuaxie.com/android-internationalization-locale/