这是7z文件格式及其源码的分析系列的第四篇. 上一篇讲到了7z文件静态结构的尾header部分.这一篇开始,将从7z实际压缩流程开始详细介绍7z文件尾header的详细结构.
一, 第一个概念: coder.
在7z的压缩过程中, 一个非常核心的概念就是coder. 一个coder代表一个算法, 通常是指一个压缩或解压算法(也包括过滤算法和加密算法等). 例如, 在7z中lzma算法就是一个coder, deflate算法也是一个coder. 7z中用于加密的AES256算法也是一个coder.
所以概念上讲, 能处理一个文件流的算法就是一个coder. 这个"处理"的概念可以是压缩/解压, 加密等等.
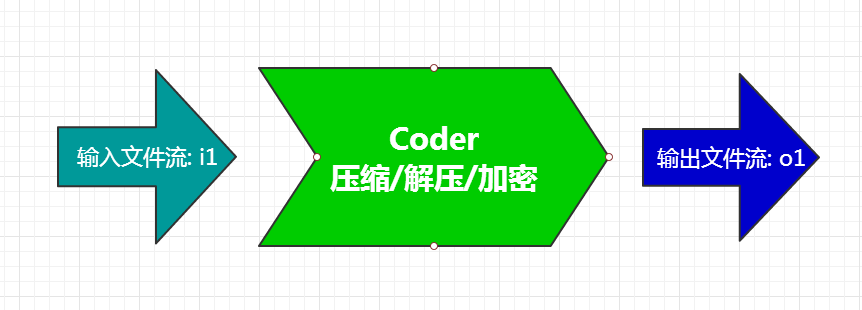
(图1)
通常来讲, 一个coder只能处理一个输入流, 并且只有一个输出流. 比如把一个文件流压缩成一个输出流. 但是, 7z中有的coder可以把一个输入流处理成多个输出流, 反过来也可以把多个流处理成一个流. 比如7z的 BCJ2 coder, 它是一个过滤coder, 可以把一个exe文件过滤成四个输出流. 这样的话, 7z的coder概念得到了扩展. 就是可能同时处理多个输入流, 并且可能输出多个流:

(图2)
这里可以先简单的体验一下压缩的过程了:
1. 简单压缩过程, 把文件流交给lzma coder压缩.
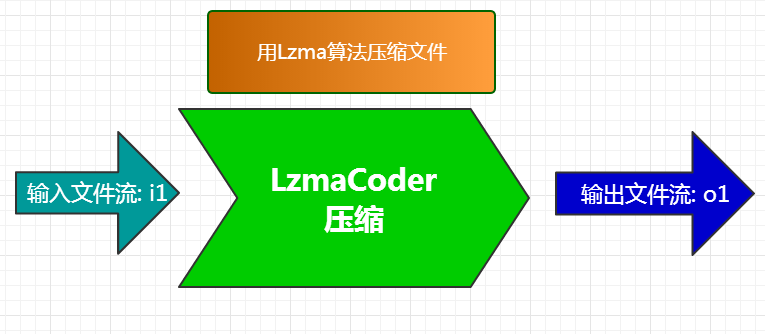
(图3)
2. 多coder串联, 理论上可以串联任何两个coder, 而且串联的级数也是没有限制的, 可以串联任意多级. 当然, 由于熵的存在, 串联过个压缩coder是没有意义的.
这里示例的是最常用的一种方式,就是压缩并且加密.
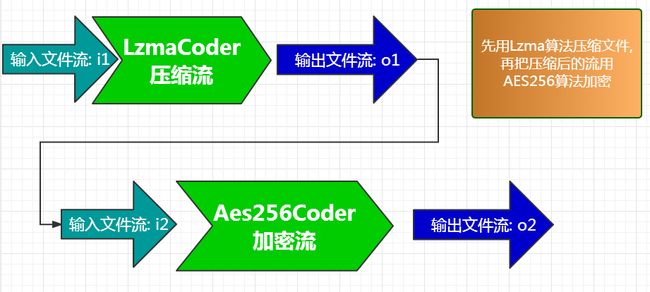
(图4)
注意上图中的o1, 和 i2. o1是第一个coder的输出流, i2是第二个coder的输入流. 在实际操作中, 这两个流其实是同一个流, 直接把第一个的输出当做第二个的输入.
解压的过程就是上面的逆过程.
上图就是比较完整的一次压缩过程了.
二, 第二个概念 Folder, 不是文件夹.
这里的Folder要特别注意, 它不是我们通常指的文件夹. 它也不是任何物理上存在的东西.
7z在开始压缩之前, 会把文件分类, 大体上是按文件类型以及文件是否需要加密来分类的. 比如说, 把所有的exe文件分成一类(一个Folder), 或者把所有需要加密的文件分在一起. 等等. 具体分类方法以后再说. 这个分类方法并不重要, 7z的实现用的方法比较简单. 实际上如果要实现7z的压缩器的话, 这个分类方法你说了算. 你可以给每个文件划分成一个Folder.
我们看一个例子:
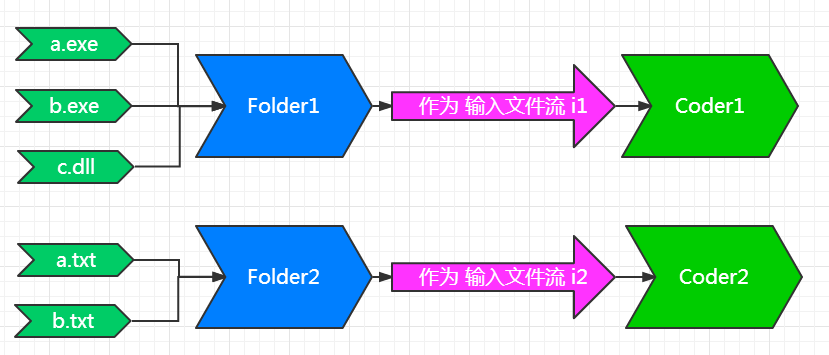
(图5)
在这个例子中, 我们共有5个文件需要压缩.
1. 首先, 通过一定的分组方法, 我们分成了两个Folder, 第一个Folder包括: a.exe, b.exe 和 c.dll 三个文件. 第二个Folder包括:a.txt 和 b.txt.
2. 对Folder1来说, 它包含三个文件, Folder1就简单的把三个文件串联起来,当做一个大文件, 作为输入流 i1 给Coder1 用. 后面的过程就就是上面的 图4 的内容了.
在7z源码的: \CPP\7zip\Archive\7z\ 这个目录下,有 7zFolderInStream.h 和7zFolderInStream.cpp 专门处理把多个文件串联伪装成一个文件的任务. 从Coder1 的角度看, 它只知道有个文件流 i1, 并不知道这个i1 是一个真实的文件 还是由一个Folder伪装的.
实际上, 7z概念上最小的压缩单位不是文件, 而是Folder, 它会先把所有的文件都归到一个相应的Folder中, 然后 让这个Folder作为文件流, 流过若干个Coder. 我们再抽象一下上面的压缩过程:

(图 6)
上图中的字母 'i' 表示输入的意思, 'o' 表示输出. 后面的数字表示序号. 简单解释一下, 这个Folder流最初是作为Coder1 的输入流i1. Coder1 的输出流是o1. 这个o1又作为 i2 输入给Coder2用, 然后又是Coder3.
值得注意的是最后一个coder的输出流 o3. 它就是压缩的最终输出结果了. 它在7z中叫做一个PackedStream. 就是打包的流. 我们叫做p1吧. 如果有多个Folder, 那每个Folder就会有一个或多个PackedStream. 所以所有文件压缩之后就会有 pn. 这n个packedStream会被按顺序存储在 7z的文件主体, 就是上一篇文章中介绍的第二部分.
每个Folder 包含了哪些文件, 每个文件大小等等这些详细信息都存贮在7z的尾文件头中了. 在7zformat.txt中有这一段:
NumFolders
Folders[NumFolders]
{
NumCoders
CodersInfo[NumCoders]
{
ID
NumInStreams; //表示这个coder 所接受的输入流的个数, 一般是1个
NumOutStreams; //表示这个coder的输出流的个数, 一般是1个.
PropertiesSize //一个int值, 表示后面Properties的字节长度
Properties[PropertiesSize] // 字节数组, 表示这个coder的一些设置信息, 比如压缩级别, 或者AES加密的IV等等.
}
NumBindPairs // 表示bindpair 的个数. bindpair表示输入流和输出流的绑定关系. 例如上面的图6中, o1和i2是绑定的, o2和i3是绑定的.
BindPairsInfo[NumBindPairs] //bindpair的数组, 记录每一个bindpair.
{
InIndex; //这个绑定的输入index, 就是上图中对应的 i后面的序号. (不好意思, 画图的时候没注意,图上下表是从1开始的,但是实际上,你懂的, 都是从0开始的.所有上面图中的下标都要减一.)
OutIndex; //绑定对应的输出index, 就是对应上图中o后面的序号. 同上.
}
PackedIndices //这表示这个folder最终输出的packstream在所有packstream中的序号.
}
UnPackSize[Folders][Folders.NumOutstreams] // 这是一个二位数组, 记录每个Folder对应的输出流的个数.
CRCs[NumFolders] //这是一个Crc的数组, 没个folder 流的crc, 7z目前没有使用这一个字段.
稍微解释一下上面的结构:
1. NumFolders, 显示一个int32值, 它记录了7z文件中共有多少个Folder.
2. 后面那是folder数组, 一次排布每个Folder. 每个Folder结构如下:
3. NumCoders, int32值, 记录了这个Folder总共进过了几个coder.
4. 后面就是它的所有Coder的数组, 每个coder的结构: 显示一个coder 的id. 就是coder的唯一标示符. 这个id的定义在: DOC/目录下的 methods.txt.
5. 更详细的信息, 请看上面代码后面的注释吧.
6. 我再强调一点,我画图的时候没有注意,所以图中的i和o后面的序号都是从1开始的, 实际上,你懂的, 每个存储的序号都是从0开始的, 没有例外. 如果你发现哪里的序号和我说的不一样, 请检查这个. 没有例外, 所有的序号都是从0开始的. 包括以后我可能会画的图. 记住都是从0开始的.
7, 再有一点就是, 比如上图中的folder经过了 coder1, coder2 和coder3 这三个coder. 实际才存储这三个coder的时候, 是按逆序存储的, 就是先存Coder3, 然后是coder2, 最后是coder1. 这是为了方便解压.
上面的图6就是一次比较完整的压缩流程, 解压的流程就是反过来, 先分别构建coder1, coder2 和coder3, 然后逆向流动就最终解压了.
每个Folder都会经过一次完整的压缩过程.
好了, 主要的压缩过程和结构已经介绍完了. 下一篇将给大家介绍剩下的文件详细信息的存储方式, 以及最终的Header的生成方式.
最后还是欢迎大家访问我的独立博客: http://byNeil.com
写这么多字, 画图都不容易, 帮顶一下吧, 小伙伴们.