数据库优化
一、遵循范式
数据库表设计时需要遵循方式
表的范式,是首先符合1NF, 才能满足2NF , 进一步满足3NF
1NF: 即表的列的具有原子性,不可再分解,即列的信息,不能分解.只要数据库是关系型数据库(mysql/oracle/db2/sysbase/sql server),就自动的满足1NF.关系型数据库中是不允许分割列的。
2NF:表中的记录是唯一的.通常我们设计一个主键来实现
3NF:即表中不要有冗余数据, 就是说,表的信息,如果能够被推导出来,就不应该单独的设计一个字段来存放.(外键)
反3NF :没有冗余的数据库未必是最好的数据库,有时为了提高运行效率,就必须降低范式标准,适当保留冗余数据。具体做法是: 在概念数据模型设计时遵守第三范式,降低范式标准的工作放到物理数据模型设计时考虑。降低范式就是增加字段,允许冗余。 订单和订单项、相册浏览次数和照片的浏览次数
二、选择合适的存储引擎
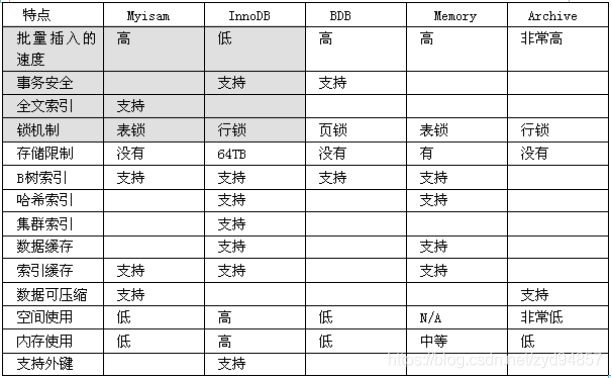
在开发中,我们经常使用的存储引擎 myisam / innodb/ memory
MyISAM存储引擎
如果表对事务要求不高,同时是以查询和添加为主的,我们考虑使用myisam存储引擎. 比如 bbs 中的 发帖表,回复表.
INNODB存储引擎:
对事务要求高,保存的数据都是重要数据,我们建议使用INNODB,比如订单表,账号表.
Memory 存储
我们数据变化频繁,不需要入库,同时又频繁的查询和修改,我们考虑使用memory, 速度极快.
问 MyISAM 和 INNODB的区别(主要)
1. 事务安全 myisam不支持事务而innodb支持
2. 查询和添加速度 myisam不用支持事务就不用考虑同步锁,查找和添加的速度快
3. 支持全文索引 myisam支持innodb不支持
4. 锁机制 myisam支持表锁而innodb支持行锁(事务)
5. 外键 MyISAM 不支持外键, INNODB支持外键. (通常不设置外键,通常是在程序中保证数据的一致)
三、创建合适的索引
索引(Index)是帮助DBMS高效获取数据的数据结构。
分类:普通索引/唯一索引/主键索引/全文索引
普通索引:允许重复的值出现
唯一索引:除了不能有重复的记录外,其它和普通索引一样(用户名、用户身份证、email,tel)
主键索引:是随着设定主键而创建的,也就是把某个列设为主键的时候,数据库就会給改列创建索引。这就是主键索引.唯一且没有null值
全文索引:用来对表中的文本域(char,varchar,text)进行索引, 全文索引针对MyIsam
explain select * from articles where match(title,body) against(‘database’);【会使用全文索引】
索引使用小技巧
索引弊端
1.占用磁盘空间。
2.对dml(插入、修改、删除)操作有影响,变慢。
使用场景:
a: 肯定在where条件经常使用,如果不做查询就没有意义
b: 该字段的内容不是唯一的几个值(sex)
c: 字段内容不是频繁变化.
具体技巧:
- 对于创建的多列索引(复合索引),不是使用的第一部分就不会使用索引。
alter table dept add index my_ind (dname,loc); // dname 左边的列,loc就是右边的列
explain select * from dept where dname='aaa'\G 会使用到索引
explain select * from dept where loc='aaa'\G 就不会使用到索引
2. 对于使用like的查询,查询如果是’%aaa’不会使用到索引而‘aaa%’会使用到索引。
explain select * from dept where dname like '%aaa'\G不能使用索引
explain select * from dept where dname like 'aaa%'\G使用索引.
所以在like查询时,‘关键字’的最前面不能使用 % 或者 _这样的字符.,如果一定要前面有变化的值,则考虑使用 全文索引sphinx.
3.如果条件中有or,有条件没有使用索引,即使其中有条件带索引也不会使用。换言之,就是要求使用的所有字段,都必须单独使用时能使用索引.
4.如果列类型是字符串,那一定要在条件中将数据使用引号引用起来。否则不使用索引。
expain select * from dept where dname=’111’;
expain select * from dept where dname=111;(数值自动转字符串)
expain select * from dept where dname=qqq;报错
也就是,如果列是字符串类型,无论是不是字符串数字就一定要用 ‘’ 把它包括起来.
5.如果mysql估计使用全表扫描要比使用索引快,则不使用索引。
表里面只有一条记录
四、分表
分表分为水平(按行)分表和垂直(按列)分表
根据经验,Mysql表数据一般达到百万级别,查询效率会很低,容易造成表锁,甚至堆积很多连接,直接挂掉;水平分表能够很大程度较少这些压力。
按行数据进行分表。
如果一张表中某个字段值非常多(长文本、二进制等),而且只有在很少的情况下会查询。这时候就可以把字段多个单独放到一个表,通过外键关联起来。
考试详情,一般我们只关注分数,不关注详情。
水平分表策略:
1.按时间分表
这种分表方式有一定的局限性,当数据有较强的实效性,如微博发送记录、微信消息记录等,这种数据很少有用户会查询几个月前的数据,如就可以按月分表。
2.按区间范围分表
一般在有严格的自增id需求上,如按照user_id水平分表:
table_1 user_id从1~100w
table_2 user_id从101~200w
table_3 user_id从201~300w
3.hash分表*****
通过一个原始目标的ID或者名称通过一定的hash算法计算出数据存储表的表名,然后访问相应的表。
五、读写分离
一台数据库支持的最大并发连接数是有限的,如果用户并发访问太多。一台服务器满足不要要求是就可以集群处理。Mysql的集群处理技术最常用的就是读写分离。
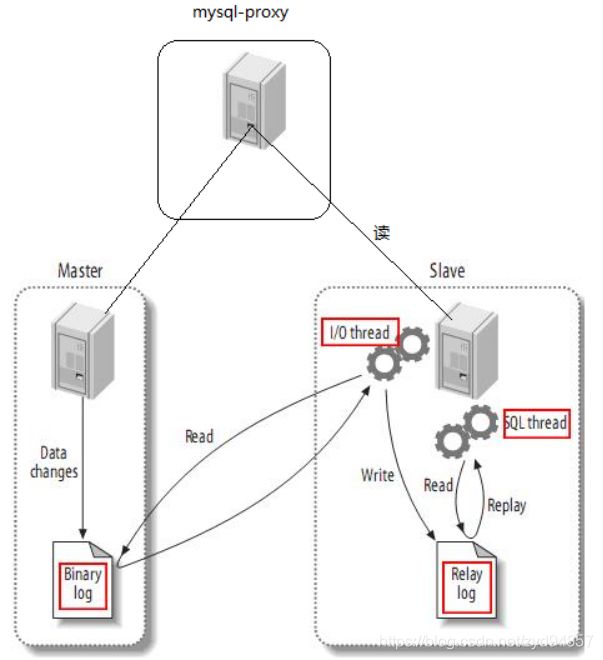
主从同步
数据库最终会把数据持久化到磁盘,如果集群必须确保每个数据库服务器的数据是一直的。能改变数据库数据的操作都往主数据库去写,而其他的数据库从主数据库上同步数据。
读写分离
使用负载均衡来实现写的操作都往主数据去,而读的操作往从服务器去。
六、缓存
在持久层(dao)和数据库(db)之间添加一个缓存层,如果用户访问的数据已经缓存起来时,在用户访问时直接从缓存中获取,不用访问数据库。而缓存是在操作内存级,访问速度快。
作用:减少数据库服务器压力,减少访问时间。
Java中常用的缓存有,
1、hibernate的二级缓存。该缓存不能完成分布式缓存。

2、可以使用redis(memcahe等)来作为中央缓存。
对缓存的数据进行集中处理
七、语句优化
DDL优化:
1 、通过禁用索引来提供导入数据性能 。 这个操作主要针对有数据库的表,追加数据
//去除键
alter table test3 DISABLE keys;
//批量插入数据
insert into test3 select * from test;
//恢复键
alter table test3 ENABLE keys;
2、 关闭唯一校验
set unique_checks=0 关闭
set unique_checks=1 开启
3、修改事务提交方式(导入)(变多次提交为一次)
set autocommit=0 关闭
//批量插入
set autocommit=1 开启
DML优化(变多次提交为一次)
insert into test values(1,2);
insert into test values(1,3);
insert into test values(1,4);
//合并多条为一条
insert into test values(1,2),(1,3),(1,4)
DQL优化
Order by优化
1、多用索引排序
2、普通结果排序(非索引排序)Filesort
group by优化
是使用order by null,取消默认排序
子查询优化
在客户列表找到不在支付列表的客户
#在客户列表找到不在“支付列表”的客户 , 查询没买过东西的客户
explain
select * from customer where customer_id not in (select DISTINCT customer_id from payment); #子查询 -- 这种是基于func外链
explain
select * from customer c left join payment p on(c.customer_id=p.customer_id) where p.customer_id is null -- 这种是基于“索引”外链
Or优化
在两个独立索引上使用or的性能优于
1、 or两边都是用索引字段做判断,性能好!!
2、 or两边,有一边不用,性能差
3、 如果employee表的name和email这两列是一个复合索引,但是如果是 :name='A' OR email='B' 这种方式,不会用到索引!
limit优化
select film_id,description from film order by title limit 50,5;
select a.film_id,a.description from film a inner join (select film_id from film order by title limit 50,5)b on a.film_id=b.film_id