Hive自定义函数UDF的简单应用。
本实例简单的对json字符串使用自定义函数进行解析,方便hive的使用。
首先数据长这样:
很多几十万条:
{"movie":"2081","rate":"5","timeStamp":"977536266","uid":"106"}
{"movie":"1357","rate":"3","timeStamp":"977536364","uid":"106"}
{"movie":"902","rate":"3","timeStamp":"977536244","uid":"106"}
{"movie":"1296","rate":"4","timeStamp":"977536022","uid":"106"}
{"movie":"908","rate":"4","timeStamp":"977535797","uid":"106"}
{"movie":"838","rate":"4","timeStamp":"977536195","uid":"106"}
{"movie":"3044","rate":"4","timeStamp":"977536195","uid":"106"}
{"movie":"2243","rate":"4","timeStamp":"977536106","uid":"106"}
我们用hive分析这些数据时内置函数已经满足不了需求,需要自定义函数来实现。
需求:想要传递一个json串和index ,就能返回相应的字段,比如:
select myjson(json,1),myjson(json,2),myjson(json,3),myjson(json,4) from xx;
能够返回上面相应的:2081,5,977536266,106 hive中的json解析函数也可以,文末介绍。
需要写个java类,来进行实现。
hive自定义函数实现的步骤:
1、写 java程序实现想要的功能,传入json串和角标返回相应的值
2、打包成jar上传到hive机器
3、在hive命令中添加jar到classpath # 在hive中操作:add jar /你的路径/xx.jar
4、创建一个myjson函数关联java类 #create temporary function myjson as 'cn.thy.json.myJsonParser';
创建java类,要继承org.apache.hadoop.hive.ql.exec.UDF,重载evaluate方法,传入json串和索引index返回想要的字符串
package cn.thy.json;
import org.apache.hadoop.hive.ql.exec.UDF;
public class myJsonParser extends UDF{
//重载父类中的一个方法evaluate
public String evaluate(String json,int index) {
//{"movie":"1193","rate":"5","timeStamp":"978300760","uid":"1"}
/**
* 1 3 1*4-1
* 2 7 2*4-1
* 3 11
* 4 15
* 等差数列
*/
String[] fields = json.split("\"");
return fields[4*index-1];
}
}将类打成jar包。
添加到hive的classpath
add jar /你的路径/xx.jar

创建hive函数关联这个java类
create temporary function myjson as 'cn.thy.json.myJsonParser';
![]()
将使用自定义函数的查询结果放入到表t_rate中
create table t_rate as
select myjson(json,1) as movie,myjson(json,2) as rate,myjson(json,3) as ts,myjson(json,4) as uid
from t_ratingjson;
查看t_rate :

然后我们就可以做相应的统计分析了。
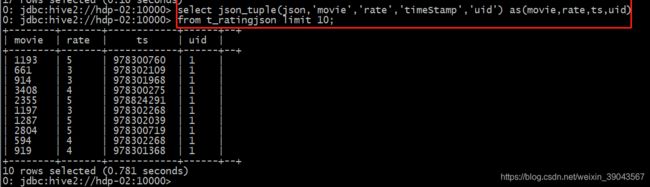
使用hive中的json解析函数进行生成表
select json_tuple(json,'movie','rate','timeStamp','uid') as(movie,rate,ts,uid)
from t_ratingjson limit 10;