Python量化交易笔记---16.方差分析
方差分析是一种多变量之间关系的定性分析方法,通过研究多个变量之间存在的关系,我们可以提高预测的准确性。
1.概述
在股票研究中,我们经常按行业版块来进行研究,假设不同行业间收益率为相互独立的,我们想要知道化工行业与金融行业相比,收益率是高还是低。在这个问题中,行业版块我们称之为因子(Factor)变量,因子变量可以取实数值,也可以取如行业类型这样离散状态值,我们称之为水平;我们研究的收益率称之为反应变量。
采用方差分析来解决这类问题时,我们首先从反应变量的方差入手,研究诸多因子变量,哪些因子变量对反应变量有显著的影响。方差分析不能直接用于预测,但是可以识别出重要的因子。
方差分析分为单因素方差分析、多因素方差分析、析因方差分析。多因素方差分析是研究多个因子变量分别对反应变量的影响,而不是这些因素的总体对反应变量的影响。析因方差分析与多因素方差分析相似,就是增加某些因子的乘项。
2.数学原理
2.1.离差平方和
我们假设因子变量 X X X共有M个水平,每个水平下观测到的样本数为 N j , j ∈ { 1 , 2 , 3 , . . . , M } N_{j}, j \in \{1, 2, 3, ..., M\} Nj,j∈{1,2,3,...,M},令 Y i j Y_{ij} Yij代表在第 j j j个水平组别下第 i i i个反应变量的值,其中 i ∈ { 1 , 2 , 3 , . . . , N j } i \in \{1, 2, 3, ..., N_{j}\} i∈{1,2,3,...,Nj}。令 μ j \mu _{j} μj表示第 j j j个水平下反应变量的均值, μ 0 \mu _{0} μ0为所有样本的反应变量均值。
我们以研究的股票问题为例,我们要研究的行业为:化工、通信、机械、电子、金融,则M=5,我们有这些行业一年的收益率数据,则 N j = 255 N_{j}=255 Nj=255,则 Y 100 , 2 Y_{100,2} Y100,2,则代表在第100天通信行业的收益率数据。则 μ 2 \mu _{2} μ2代表电信行业收益率的均值, μ 0 \mu _{0} μ0代表这5个行总体收益率均值。
我们的假设 H 0 H_{0} H0为:
μ 1 = μ 2 = . . . = μ M = μ 0 \mu _{1}=\mu _{2}=...=\mu _{M}=\mu _{0} μ1=μ2=...=μM=μ0
假设用 y i , j , j = 1 , 2 , 3 , . . . , M , i = 1 , 2 , 3 , . . . , N j y_{i,j}, \quad j=1,2,3,...,M, \quad i=1,2,3,...,N_{j} yi,j,j=1,2,3,...,M,i=1,2,3,...,Nj,则第 j j j个水平的均值为:
y j ˉ = y 1 , j + y 2 , j + . . . + y N j , j N j = 1 N j ∑ i = 1 N j y i , j , j = 1 , 2 , 3 , . . . , M \bar{y_{j}} = \frac{y_{1,j} + y_{2,j} + ... + y_{N_{j},j}}{N_{j}}=\frac{1}{N_{j}}\sum_{i=1}^{N_{j}}y_{i,j} \quad , \quad j=1,2,3,...,M yjˉ=Njy1,j+y2,j+...+yNj,j=Nj1i=1∑Njyi,j,j=1,2,3,...,M
所有水平的反应变量均值为:
y ˉ = 1 N ∑ j = 1 M ∑ i = 1 N j y i , j = 1 N ∑ j = 1 M N j ( 1 N j ∑ i = 1 N j y i , j ) = 1 N ∑ j = 1 M N j y j ˉ \bar{y}=\frac{1}{N} \sum_{j=1}^{M} \sum_{i=1}^{N_{j}} y_{i,j}\\ =\frac{1}{N} \sum_{j=1}^{M} N_{j} \bigg( \frac{1}{N_{j}}\sum_{i=1}^{N_{j}} y_{i,j} \bigg)\\ =\frac{1}{N} \sum_{j=1}^{M} N_{j} \bar{y_{j}} yˉ=N1j=1∑Mi=1∑Njyi,j=N1j=1∑MNj(Nj1i=1∑Njyi,j)=N1j=1∑MNjyjˉ
式中 N = ∑ j = 1 M N j N=\sum_{j=1}^{M} N_{j} N=∑j=1MNj为全样本数。根据我们的假设,我们主要是想检验 y ˉ \bar{y} yˉ与 y j ˉ \bar{y_{j}} yjˉ是否相等。
任意一个样本与全样本均值之间的偏差可以表示为:
y i , j − y ˉ = y i , j − y j ˉ + y j ˉ − y ˉ y_{i,j}-\bar{y}=y_{i,j}-\bar{y_{j}}+\bar{y_{j}}-\bar{y} yi,j−yˉ=yi,j−yjˉ+yjˉ−yˉ
上式中第一项称之为组内偏差,第二项称之为组间偏差。
总离差平方合(Total Sum of Squares, TSS)定义为:
∑ j = 1 M ∑ i = 1 N j ( y i , j − y ˉ ) 2 = ∑ j = 1 M ∑ i = 1 N j ( y i , j − y j ˉ ) 2 + ∑ j = 1 M ∑ i = 1 N j ( y j ˉ − y ˉ ) 2 + 2 ∑ j = 1 M ∑ i = 1 N j ( y i , j − y j ˉ ) ( y j ˉ − y ˉ ) \sum_{j=1}^{M} \sum_{i=1}^{N_j}(y_{i,j}-\bar{y})^{2}=\sum_{j=1}^{M} \sum_{i=1}^{N_j} (y_{i,j}-\bar{y_{j}})^{2} + \sum_{j=1}^{M} \sum_{i=1}^{N_j} (\bar{y_{j}} - \bar{y})^{2} + 2\sum_{j=1}^{M} \sum_{i=1}^{N_j}(y_{i,j}-\bar{y_{j}})(\bar{y_{j}}-\bar{y}) j=1∑Mi=1∑Nj(yi,j−yˉ)2=j=1∑Mi=1∑Nj(yi,j−yjˉ)2+j=1∑Mi=1∑Nj(yjˉ−yˉ)2+2j=1∑Mi=1∑Nj(yi,j−yjˉ)(yjˉ−yˉ)
对于上式最后一项, y j ˉ − y ˉ \bar{y_{j}}-\bar{y} yjˉ−yˉ相当于常数项可以提出对 i i i的累加,又因为 ∑ i = 1 N j ( y i , j − y j ˉ ) = ∑ i = 1 N j y i , j − N j y j ˉ \sum_{i=1}^{N_{j}}(y_{i,j}-\bar{y_{j}})=\sum_{i=1}^{N_{j}}y_{i,j}-N_{j}\bar{y_{j}} ∑i=1Nj(yi,j−yjˉ)=∑i=1Njyi,j−Njyjˉ的值为0,所以最后一项的值为0,上式可以化简为:
∑ j = 1 M ∑ i = 1 N j ( y i , j − y ˉ ) 2 = ∑ j = 1 M ∑ i = 1 N j ( y i , j − y j ˉ ) 2 + ∑ j = 1 M ∑ i = 1 N j ( y j ˉ − y ˉ ) 2 = ∑ j = 1 M ∑ i = 1 N j ( y i , j − y j ˉ ) 2 + ∑ j = 1 M N j ( y j ˉ − y ˉ ) 2 \sum_{j=1}^{M} \sum_{i=1}^{N_j}(y_{i,j}-\bar{y})^{2}=\sum_{j=1}^{M} \sum_{i=1}^{N_j} (y_{i,j}-\bar{y_{j}})^{2} + \sum_{j=1}^{M} \sum_{i=1}^{N_j} (\bar{y_{j}} - \bar{y})^{2}\\ =\sum_{j=1}^{M} \sum_{i=1}^{N_j} (y_{i,j}-\bar{y_{j}})^{2} + \sum_{j=1}^{M}N_{j}(\bar{y_{j}}-\bar{y})^{2} j=1∑Mi=1∑Nj(yi,j−yˉ)2=j=1∑Mi=1∑Nj(yi,j−yjˉ)2+j=1∑Mi=1∑Nj(yjˉ−yˉ)2=j=1∑Mi=1∑Nj(yi,j−yjˉ)2+j=1∑MNj(yjˉ−yˉ)2
上式右侧第一项为误差平方和(Error Sum of Squares, ESS),表征组内偏差平方和;第二项为因子平方和(Factor Sum of Squares, ESS),表征组间偏差平方和。
2.2.自由度
自由度是指当以样本的统计量来估计样本的总体参数时,样本中能够独立或自由变动的样本个数。假设一个样本集 x i , i = 1 , 2 , 3 , . . . , n x_{i},i=1,2,3,...,n xi,i=1,2,3,...,n,均值统计量定义为:
x ˉ = 1 n ∑ i = 1 n x i \bar{x}=\frac{1}{n} \sum_{i=1}^{n} x_{i} xˉ=n1i=1∑nxi
此时,如果我们固定 x ˉ \bar{x} xˉ,如果 x 1 , x 2 , . . . , x n − 1 x_{1},x_{2},...,x_{n-1} x1,x2,...,xn−1固定后, x n x_{n} xn可由下式计算得到:
x n = n x ˉ − x 1 − x 2 − . . . − x n − 1 x_{n}=n\bar{x}-x_{1}-x_{2}-...-x_{n-1} xn=nxˉ−x1−x2−...−xn−1
因此我们说这个样本集的自由度为 n − 1 n-1 n−1。
再来看我们的方差定义:
S = 1 自 由 度 ∑ i = 1 n ( x i − x ˉ ) 2 = 1 n − 1 ∑ i = 1 n ( x i − x ˉ ) 2 S=\frac{1}{自由度} \sum_{i=1}^{n} (x_{i}-\bar{x})^{2}=\frac{1}{n-1} \sum_{i=1}^{n} (x_{i}-\bar{x})^{2} S=自由度1i=1∑n(xi−xˉ)2=n−11i=1∑n(xi−xˉ)2
因为此时的自由度为 n − 1 n-1 n−1,所以得到我们熟悉的方差公式。
下面我们来分析上节中的TSS、ESS、FSS的自由度。
2.2.1.TSS自由度
TSS的定义为:
∑ j = 1 M ∑ i = 1 N j ( y i , j − y ˉ ) 2 \sum_{j=1}^{M} \sum_{i=1}^{N_j}(y_{i,j}-\bar{y})^{2} j=1∑Mi=1∑Nj(yi,j−yˉ)2
因为 y ˉ \bar{y} yˉ是总样本的均值,根据上面的讨论,固定 y ˉ \bar{y} yˉ,则其自由度为 N − 1 N-1 N−1,有:
∑ j = 1 M ∑ i = 1 N j ( y i , j − y ˉ ) = 0 \sum_{j=1}^{M} \sum_{i=1}^{N_j}(y_{i,j}-\bar{y})=0 j=1∑Mi=1∑Nj(yi,j−yˉ)=0
2.2.2.FSS自由度
FSS的定义:
F S S = ∑ j = 1 M N j ( y j ˉ − y ˉ ) 2 FSS=\sum_{j=1}^{M}N_{j}(\bar{y_{j}}-\bar{y})^{2} FSS=j=1∑MNj(yjˉ−yˉ)2
因为:
∑ j = 1 M ( y j ˉ − y ˉ ) = ∑ j = 1 M y j ˉ − M y ˉ = 0 \sum_{j=1}^{M} (\bar{y_{j}}-\bar{y}) = \sum_{j=1}^{M} \bar{y_{j}}-M\bar{y}=0 j=1∑M(yjˉ−yˉ)=j=1∑Myjˉ−Myˉ=0
因此其自由度为 M − 1 M-1 M−1。我们定义平均数组间均方差为:
M S F = F S S M − 1 = 1 M − 1 ∑ j = 1 M N j ( y j ˉ − y ˉ ) 2 MSF=\frac{FSS}{M-1}=\frac{1}{M-1}\sum_{j=1}^{M} N_{j}(\bar{y_{j}}-\bar{y})^{2} MSF=M−1FSS=M−11j=1∑MNj(yjˉ−yˉ)2
2.2.3.ESS自由度
ESS的定义为:
∑ j = 1 M ∑ i = 1 N j ( y i , j − y j ˉ ) 2 \sum_{j=1}^{M} \sum_{i=1}^{N_j} (y_{i,j}-\bar{y_{j}})^{2} j=1∑Mi=1∑Nj(yi,j−yjˉ)2
由于:
∑ i = 1 N j ( y i , j − y j ˉ ) = ∑ i = 1 N j y i , j − N j y j ˉ = 0 , j = 1 , 2 , . . . , M \sum_{i=1}^{N_{j}} (y_{i,j}-\bar{y_{j}})=\sum_{i=1}^{N_{j}} y_{i,j}-N_{j}\bar{y_{j}}=0, \quad j=1,2,...,M i=1∑Nj(yi,j−yjˉ)=i=1∑Njyi,j−Njyjˉ=0,j=1,2,...,M
总共减少了 M M M个自由度,所以ESS的自由度为 N − M N-M N−M。我们定义平均数组内均方差为:
M S E = 1 N − M ∑ j = 1 M ∑ i = 1 N j ( y i , j − y j ˉ ) 2 MSE=\frac{1}{N-M}\sum_{j=1}^{M} \sum_{i=1}^{N_{j}}(y_{i,j}-\bar{y_{j}})^{2} MSE=N−M1j=1∑Mi=1∑Nj(yi,j−yjˉ)2
2.2.4.关系
TSS、ESS、FSS之间自由度的关系为: N − 1 = ( M − 1 ) + ( N − M ) N-1=(M-1)+(N-M) N−1=(M−1)+(N−M)。
2.3.显著性检验
假设第 j j j个水平的样本满足: Y i , j ∼ N ( μ j , σ 0 2 ) Y_{i,j} \sim N(\mu _{j}, \sigma _{0}^{2}) Yi,j∼N(μj,σ02),组间均方差期望为:
E ( M S F ) = σ 0 2 + 1 M − 1 ∑ j = 1 M N j ( μ j − μ 0 ) 2 E(MSF)=\sigma _{0}^{2} + \frac{1}{M-1} \sum_{j=1}^{M} N_{j} (\mu _{j}-\mu _{0})^{2} E(MSF)=σ02+M−11j=1∑MNj(μj−μ0)2
组内均方差期望值:
E ( M S E ) = σ 0 2 E(MSE)=\sigma _{0}^{2} E(MSE)=σ02
我们的假设 H 0 H_{0} H0为: μ 1 = μ 2 = . . . = μ M = μ 0 \mu _{1}=\mu _{2}=...=\mu _{M}=\mu _{0} μ1=μ2=...=μM=μ0,则 E ( M S F ) = E ( M S E ) = σ 0 2 E(MSF)=E(MSE)=\sigma _{0}^{2} E(MSF)=E(MSE)=σ02,我们定义检验的统计量为:
ϕ = M S F M S E = F S S M − 1 E S S N − M \phi = \frac{MSF}{MSE}=\frac{ \frac{FSS}{M-1} }{ \frac{ESS}{N-M} } ϕ=MSEMSF=N−MESSM−1FSS
2.4.方差分析步聚
2.4.1.识别因子变量水平
识别出因子变量及其水平,例如对股票收益率按行业进行研究时,就是找出所有的行业。
2.4.2.提出假设
通常我们的假设 H 0 H_{0} H0为: μ 1 = μ 2 = . . . = μ M = μ 0 \mu _{1}=\mu _{2}=...=\mu _{M}=\mu _{0} μ1=μ2=...=μM=μ0。
2.4.3.计算统计量
计算MSF和MSE,构造统计量:
ϕ = M S F M S E = F S S M − 1 E S S N − M \phi = \frac{MSF}{MSE}=\frac{ \frac{FSS}{M-1} }{ \frac{ESS}{N-M} } ϕ=MSEMSF=N−MESSM−1FSS
2.4.4.检验
计算p值,p值大于0.05时接受,否则拒绝原假设。
3.单因素方差分析
行业收益率数据如下所示:
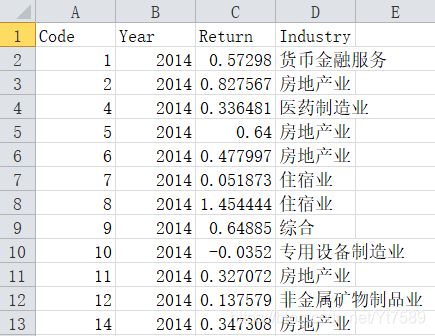
对其进行方差分析的程序如下所示:
import numpy as np
import pandas as pd
from scipy import stats
import statsmodels.stats.anova as anova
from statsmodels.formula.api import ols
import matplotlib.pyplot as plt
def startup():
datas = pd.read_csv('../datas/TRD_Year.csv', encoding='gbk')
model = ols('Return ~ C(Industry)', data=datas.dropna()).fit()
rst = anova.anova_lm(model)
print(rst)
if '__main__' == __name__:
startup()
其中在第10行中,我们定义因子变量列为C(Industry),反应变量列为Return。运行结果如下所示:

其p值为4.382045e-28<0.05,因此我们的假设是错误的,即我们认为股票收益率与行业无关的假设是错误的,这与我们的直觉是一致的。
4.多因素方差分析
我们来看1993年美国个人收入数据,如下所示:
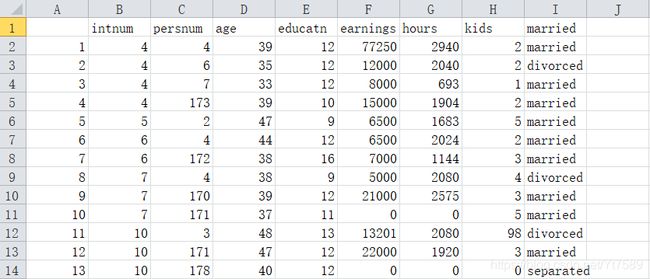
我们要研究的因子变量为E列的教育程度和I列的婚姻状态,而反应变量为F列的收入。
程序如下所示:
import numpy as np
import pandas as pd
from scipy import stats
import statsmodels.stats.anova as anova
from statsmodels.formula.api import ols
import matplotlib.pyplot as plt
def startup():
psid = pd.read_csv('../datas/PSID.csv')
model = ols('earnings ~ C(educatn)+C(married)', data=psid.dropna()).fit()
rst = anova.anova_lm(model)
print(rst)
if '__main__' == __name__:
startup()
在第10行我们选择了教育程度和婚姻状况作为因子变量。运行结果如下所示:

由上图可以看出,教育程度对应的p值为6.198294e-190,婚姻状况对应的p值为3.795366e-06,二者均小于0.05,因此可以认为二者均对收入有显著的影响。
5.析因方差分析
还以上一节的例子为例,我们要研究教育程度和婚姻状况联合起来对收入的影响,我们就用到了析因方差分析,如下所示:
import numpy as np
import pandas as pd
from scipy import stats
import statsmodels.stats.anova as anova
from statsmodels.formula.api import ols
import matplotlib.pyplot as plt
def startup():
psid = pd.read_csv('../datas/PSID.csv')
model = ols('earnings ~ C(educatn)*C(married)', data=psid.dropna()).fit()
rst = anova.anova_lm(model)
print(rst)
if '__main__' == __name__:
startup()
这里与多因素方差分析的唯一区别就是第10行,将因子变量由相加变为相乘,运行结果为:

上图中最后一列是p值,我们可以看出,教育程度和婚姻状况单独的p值都远小于0.05,所以其对收入的影响是非常显著的。而教育程度与婚姻状况联合起来,p值为0.6999要大于0.05,所以其对收入不会产生显著的影响。