字符集和单词
“.”用于匹配出换行符之外的任何一个字符。以下正则表达式可以匹配诸如Tomandy,~omandy,$omandy等字符串。
.omandy
“[]”用于指定一个字符集,无论“[]”中有多少内容,在使用时只匹配一个字符。
[a-zA-Z] #匹配所有的字母
[a-z] #匹配所有的小写字母
[abc] #匹配a或b或c
[0-9] #匹配0-9之间的数字
“单词”指两侧由非单词字符分割的字符串。“非单词字符”指字母、数字、下划线以外的任何字符。匹配一个单词可以使用“\< \>”,举例如下:
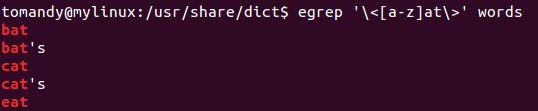
位置及字符匹配
“^”、“$”分别用于匹配行首和行尾,以下表达式用于匹配t开头,m结尾,t和m之间包含一个小写字母的行。
^t[a-z]m$
\w 匹配字母或数字或下划线或汉字 等价于 '[A-Za-z0-9]'。
\d 匹配数字。
\b 匹配单词的开始或结束。
tom(\w)?.dat #可匹配到tom.dat,toma.dat,tom1.dat等。
字符类
POSIX风格的正则表达式提供了预定义的字符类用于匹配某些特定的字符,以下正则表达式列出所有以小写字母开头,m结束的行。[[:lower:]]等同于[a-z]。
$egrep "^[[:lower:]]m$" words
常用的字符类如下所示。
| 字符类 | 描述 |
|---|---|
| [[:alnum:]] | 文字、数字字符 |
| [[:alpha:]] | 字母字符 |
| [[:lower:]] | 小写字母 |
| [[:upper:]] | 大写字母 |
| [[:digit:]] | 小数 |
| [[:xdigit:]] | 十六进制数字 |
| [[:punct:]] | 标点符号 |
| [[:blank:]] | 制表符和空格 |
| [[:space:]] | 空格 |
| [[:cntrl:]] | 所有控制符 |
| [[:print:]] | 所有可打印字符 |
| [[:graph:]] | 除空格外的所有可打印字符 |
转义字符
“\”用来表示转义字符,比如“.”在正则表达式中用于匹配换行符之外的任何一个字符,可以使用“\.”来匹配“.”。
元字符
| 元字符 | 描述 |
|---|---|
| * | 重复0次或更多次 |
| + | 重复1次或更多次 |
| ? | 重复0次或1次 |
| {n} | 重复n次 |
| {n,} | 重复n次或更多次 |
| {n,m} | 重复不少于n次,不多余m次 |
| (?:pattern) | 匹配 pattern但不获取匹配结果,也就是说这是一个非获取匹配,不进行存储供以后使用。 |
| (?=pattern) | 正向肯定预查,在任何匹配pattern的字符串开始处匹配查找字符串。该匹配不需要获取供以后使用。例如,"Windows(?=95|98|NT|2000)"能匹配"Windows2000"中的"Windows",但不能匹配"Windows3.1"中的"Windows"。 |
| (?!pattern) | 跟(?=pattern)相反,可以匹配到"Windows3.1"中的"Windows"。 |
| (?<=pattern) | 反向肯定预查,与正向肯定预查类似,只是方向相反。例如,"(?<=95|98|NT|2000)Windows"能匹配"2000Windows"中的"Windows",但不能匹配"3.1Windows"中的"Windows"。 |
| (? | 与(?<=pattern)相反。 |
| \b | 匹配一个单词边界,也就是指单词和空格间的位置。例如'er\b'可以匹配"never" 中的 'er',但不能匹配 "verb" 中的 'er'。 |
| \B | 匹配非单词边界。'er\B' 能匹配 "verb" 中的 'er',但不能匹配 "never" 中的 'er'。 |
举例说明: 例子中#用于表示注释
^t.*m$ #“.”匹配换行符外的所有字符,".*"表示匹配的字符重复0次或多次,可匹配tm,tom,tadrm等。
^t.+m$ #“.”匹配换行符外的所有字符,".*"表示匹配的字符重复1次或多次,可匹配tom,tadrm等,注意不能匹配tm。
^t.?m$ #“.”匹配换行符外的所有字符,".*"表示匹配的字符重复0次或1次,可匹配tm,tom,tam等。
^t.{2}m$ #“.”匹配换行符外的所有字符,".{2}"表示匹配的字符重复2次,可匹配toom,toam,tabm等。
^t.{2,}m$ #“.”匹配换行符外的所有字符,".*"表示匹配的字符重复2次或更多,可匹配tadm,toljsldjfm等。
^t.{2,4}m$ #“.”匹配换行符外的所有字符,".*"表示匹配的字符重复不少于2次,不多余4次,可匹配toam,taadm,t1234m等。
在 *、+ 或 ? 限定符之后放置?,该表达式从"贪心"表达式转换为"非贪心"表达式或者最小匹配。以下例子所示:
文本:
tomamdy 你是谁
<.*> #匹配到 “tomamdy 你是谁
”
<.*?> #匹配到 “” 和 “
”
<\w+?> #匹配到 “”
子表达式
子表达式也称为分组,看以下例子即可明白。
(tm){2,} #表示匹配tm重复2次或更多次的行。
tm{2,} #表示匹配m重复2次或更多次的行。
反义
"^"可用于表示行首和反义,表示反义用法的例子如下:
[^t] #表示除t以外的任何字符。
[^abcde] #表示除abcde以外的任何字符。
^[^t] #表示匹配所有不以t开头的行。
与 或操作
正则表达式对用户提交的信息简单地做“与”的操作,可以用“|”表示“或”操作。
^tm$ #所有以t开头且以m结尾的行,只能匹配tm。
^t|m$ #所有以t开头或以m结尾的行,可以匹配twerd,adfdfm,tousdwerm等。
子表达式引用
在子表达式中捕获的内容可以在正则表达式的其他地方再次使用。可使用“\”加上编号1,2,3等来指定该子表达式匹配到的内容,如以下示例:
(\<.*\>).?( )*\1
(\<.*\>)表示匹配任意长度的单词。第1个子表达式。
.?表示匹配0个或1个标点符号".",此处注意"."前面匹配的是单词,因此此处只能匹配标点符号。
( )*表示匹配0个或多个空格。第2个子表达式。
由此分析,我们不难发现上述例子,返回的其实是第1个子表达式匹配到的内容。
非打印字符
| 字符 | 描述 |
|---|---|
| \f | 匹配一个换页符 |
| \n | 匹配一个换行符 |
| \r | 匹配一个回车符 |
| \s | 匹配任何空白字符,空格、制表符、换页符等 |
| \S | 匹配任何非空白字符 |
| \t | 匹配一个制表符 |
| \v | 匹配一个垂直制表符 |
运算符优先级顺序
| 运算符 | 描述 |
|---|---|
| \ | 转义符 |
| (), (?:), (?=), [] | 括号 |
| *, +, ?, {n}, {n,}, {n,m} | 限定符 |
| ^, $, \任何元字符,任何字符 | 定位符等 |
| | | 或 |
表格从上往下标注了运算符的优先级从高到低。