redis的数据结构与内部编码
Redis支持5种数据结构类型,type命令实际返回的就是当前键的数据结构类型,它们分别是:string(字符串)、hash(哈希)、list(列表)、set(集合)、zset(有序集合),但这些只是Redis对外的数据结构。
而每种结构都有至少两种编码;这样做的好处在于:一方面接口与实现分离,当需要增加或改变内部编码时,用户使用不受影响,另一方面可以根据不同的应用场景切换内部编码,提高效率。
 可以看到每种数据结构都有两种以上的内部编码实现,例如string数据结构就包含了raw、int和embstr三种内部编码。
可以看到每种数据结构都有两种以上的内部编码实现,例如string数据结构就包含了raw、int和embstr三种内部编码。
同时,有些内部编码可以作为多种外部数据结构的内部实现,例如ziplist就是hash、list和zset共有的内部编码。
 1、字符串
1、字符串
(1)概况
字符串是最基础的类型,因为所有的键都是字符串类型,字符串长度不能超过512MB。
字符串类型的内部编码有3种:
int:8个字节的长整型。
embstr:小于等于44个字节的字符串。(redis 5版本为44个字符)
raw:大于44个字节的字符串。(redis 5版本为44个字符)
Redis会根据当前值的类型和长度决定使用内部编码实现。
(2)内部编码
字符串类型的内部编码有3种,它们的应用场景如下:
int:8个字节的长整型。字符串值是整型时,使用long整型表示。
embstr:<=44字节的字符串。embstr与raw都使用redisObject和sds保存数据,区别在于,embstr的使用只分配一次内存空间,
而raw需要分配两次内存空间(分别为redisObject和sds分配空间)。因此与raw相比,embstr的好处在于创建时少分配一次空间,
删除时少释放一次空间,以及对象的所有数据连在一起,寻找方便。而embstr的坏处也很明显,
如果字符串的长度增加需要重新分配内存时,整个redisObject和sds都需要重新分配空间,因此redis中的embstr实现为只读。
raw:大于44个字节的字符串。
(3)编码转换
当int数据不再是整数,或大小超过了long的范围时,自动转化为raw。
而对于embstr,由于其实现是只读的,因此在对embstr对象进行修改时,都会先转化为raw再进行修改,因此,只要是修改embstr对象,修改后的对象一定是raw的,无论是否达到了44个字节。
2、列表
列表(list)用来存储多个有序的字符串,一个列表可以存储2^32-1个元素。Redis中的列表支持两端插入和弹出,并可以获得指定位置(或范围)的元素,可以充当数组、队列、栈等。
(1)内部编码
列表的内部编码可以是压缩列表(ziplist)或双端链表(linkedlist)。
双端链表:由一个list结构和多个listNode结构组成;典型结构如下图所示:

ziplist(压缩列表):当哈希类型元素个数小于hash-max-ziplist-entries配置(默认512个),
同时所有值都小于hash-max-ziplist-value配置(默认64个字节)时,Redis会使用ziplist作为哈希的内部实现。
压缩列表是Redis为了节约内存而开发的,是由一系列特殊编码的连续内存块(而不是像双端链表一样每个节点是指针)组成的顺序型数据结构。与双端链表相比,压缩列表可以节省内存空间,但是进行修改或增删操作时,复杂度较高;因此当节点数量较少时,可以使用压缩列表;但是节点数量多时,还是使用双端链表划算。
linkedlist(双端链表):当列表类型无法满足ziplist的条件时,Redis会使用linkedlist作为列表的内部实现。
通过图中可以看出,双端链表同时保存了表头指针和表尾指针,并且每个节点都有指向前和指向后的指针;链表中保存了列表的长度;dup、free和match为节点值设置类型特定函数,所以链表可以用于保存各种不同类型的值。而链表中每个节点指向的是type为字符串的redisObject。
(2)编码转换
只有同时满足两个条件时,才会使用压缩列表:列表中元素数量小于512个;列表中所有字符串对象都不足64字节。如果有一个条件不满足,则使用双端列表;且编码只可能由压缩列表转化为双端链表,反方向则不可能。
3、哈希
哈希类型的内部编码有两种:
ziplist(压缩列表):当哈希类型元素个数小于hash-max-ziplist-entries配置(默认512个),
同时所有值都小于hash-max-ziplist-value配置(默认64个字节)时,Redis会使用ziplist作为哈希的内部实现,
ziplist使用更加紧凑的结构实现多个元素的连续存储,所以在节省内存方面比hashtable更加优秀。
hashtable(哈希表):当哈希类型无法满足ziplist的条件时,Redis会使用hashtable作为哈希的内部实现。
因为此时ziplist的读写效率会下降,而hashtable的读写时间复杂度为O(1)。
内层的哈希使用的内部编码可以是压缩列表(ziplist)和哈希表(hashtable)两种;Redis的外层的哈希则只使用了hashtable。
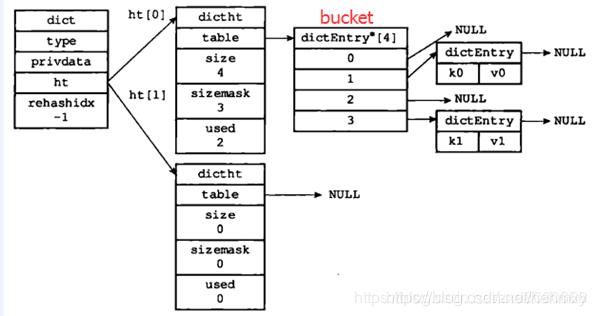
hashtable:一个hashtable由1个dict结构、2个dictht结构、1个dictEntry指针数组(称为bucket)和多个dictEntry结构组成。
正常情况下(即hashtable没有进行rehash时)各部分关系如下图所示:
 dictEntry
dictEntry
在64位系统中,一个dictEntry对象占24字节(key/val/next各占8字节)
typedef struct dictEntry{
void *key; //键值对中的键
union{
void *val; //键值对中的值
uint64_tu64;
int64_ts64;
}v;
struct dictEntry *next;//指向下一个dictEntry,用于解决哈希冲突问题
}dictEntry;
bucket
bucket是一个数组,数组的每个元素都是指向dictEntry结构的指针。
dictht
dictht结构如下:
typedef struct dictht{
dictEntry **table;//是一个指针,指向bucket
unsigned long size;//记录了哈希表的大小,即bucket的大小
unsigned long sizemask;//和哈希值一起决定一个键在table中存储的位置
unsigned long used;//记录了已使用的dictEntry的数量
}dictht;
dict
一般来说,通过使用dictht和dictEntry结构,便可以实现普通哈希表的功能;但是Redis的实现中,在dictht结构的上层,还有一个dict结构。下面说明dict结构的定义及作用。
typedef struct dict{
dictType *type;
void *privdata;
dictht ht[2];
int trehashidx;
} dict;
1、type属性和privdata属性是为了适应不同类型的键值对,用于创建多态字典。
2、ht属性和trehashidx属性则用于rehash,即当哈希表需要扩展或收缩时使用。
3、ht是一个包含两个项的数组,每项都指向一个dictht结构,这也是Redis的哈希会有1个dict、2个dictht结构的原因。通常情况下,所有的数据都是存在放dict的ht[0]中,ht[1]只在rehash的时候使用。dict进行rehash操作的时候,将ht[0]中的所有数据rehash到ht[1]中。然后将ht[1]赋值给ht[0],并清空ht[1]。
因此,Redis中的哈希之所以在dictht和dictEntry结构之外还有一个dict结构,一方面是为了适应不同类型的键值对,另一方面是为了rehash。
(3)编码转换
如前所述,Redis中内层的哈希既可能使用哈希表,也可能使用压缩列表。
只有同时满足下面两个条件时,才会使用压缩列表:哈希中元素数量小于512个;哈希中所有键值对的键和值字符串长度都小于64字节。如果有一个条件不满足,则使用哈希表;且编码只可能由压缩列表转化为哈希表,反方向则不可能。
4、集合
集合(set)与列表类似,集合中的元素是无序的不能有重复。最多可以存储2^32-1个元素。
(1)内部编码
集合的内部编码可以是整数集合(intset)或哈希表(hashtable)。
intset(整数集合):当集合中的元素都是整数且元素个数小于set-max-intset-entries配置(默认512个)时,
Redis会选用intset来作为集合内部实现,从而减少内存的使用。
hashtable(哈希表):当集合类型无法满足intset的条件时,Redis会使用hashtable作为集合的内部实现。
typedef struct intset{
uint32_t encoding;
uint32_t length;
int8_t contents[];
} intset;
际上其存储的值是int16_t、int32_t或int64_t,具体的类型便是由encoding决定的;length表示元素个数。
整数集合适用于集合所有元素都是整数且集合元素数量较小的时候,与哈希表相比,整数集合的优势在于集中存储,节省空间;同时,虽然对于元素的操作复杂度也由O(1)变为了O(n),但由于集合数量较少,因此操作的时间并没有明显劣势。
(2)编码转换
只有同时满足下面两个条件时,集合才会使用整数集合:集合中元素数量小于512个;集合中所有元素都是整数值。如果有一个条件不满足,则使用哈希表;且编码只可能由整数集合转化为哈希表,反方向则不可能。
5、有序集合
集合元素不能重复,有序。有序集合为每个元素设置一个分数(score)作为排序依据。
(1)内部编码
有序集合的内部编码可以是压缩列表(ziplist)或跳跃表(skiplist)。
ziplist(压缩列表):当有序集合的元素个数小于zset-max-ziplist-entries配置(默认128个)
同时每个元素的值小于zset-max-ziplist-value配置(默认64个字节)时,Redis会用ziplist来作为有序集合的内部实
现,ziplist可以有效减少内存使用。
skiplist(跳跃表):当ziplist条件不满足时,有序集合会使用skiplist作为内部实现,因为此时zip的读写效率会下降。
跳跃表是一种有序数据结构,通过在每个节点中维持多个指向其他节点的指针,从而达到快速访问节点的目的。除了跳跃表,实现有序数据结构的另一种典型实现是平衡树;大多数情况下,跳跃表的效率可以和平衡树媲美,且跳跃表实现比平衡树简单很多,因此redis中选用跳跃表代替平衡树。
(2)编码转换
只有同时满足下面两个条件时,才会使用压缩列表:有序集合中元素数量小于128个;有序集合中所有成员长度都不足64字节。如果有一个条件不满足,则使用跳跃表;且编码只可能由压缩列表转化为跳跃表。
我们可以通过object encoding命令查询内部编码:
127.0.0.1:6379> set str 1234567
OK
127.0.0.1:6379> object encoding str
“int”
127.0.0.1:6379> set str “hello world”
OK
127.0.0.1:6379> object encoding str
“embstr”
127.0.0.1:6379> set str “Tranquil,unbeatable to the outside. – yangming” #“凝聚于内,无敌于外。–王阳明”
OK
127.0.0.1:6379> object encoding str
“raw”
127.0.0.1:6379> hmset user:2 name kebi age 26
OK
127.0.0.1:6379> object encoding user:2
“ziplist”
127.0.0.1:6379> hmset user:1 info “沐春风,惹一身红尘;望秋月,化半缕轻烟。顾盼间乾坤倒转,一霎时沧海桑田。方晓,弹指红颜老,刹那芳华逝。”
127.0.0.1:6379> object encoding user:1
“hashtable”
127.0.0.1:6379>lpush setkey 1 2 3 … 513
OK
127.0.0.1:6379> object encoding listkey
“linkedlist”