分布式系统详解--框架(Hadoop-HDFS的HA搭建及测试)
分布式系统详解 - 框架(Hadoop的HDFS的HA搭建及测试)
一,背景概述

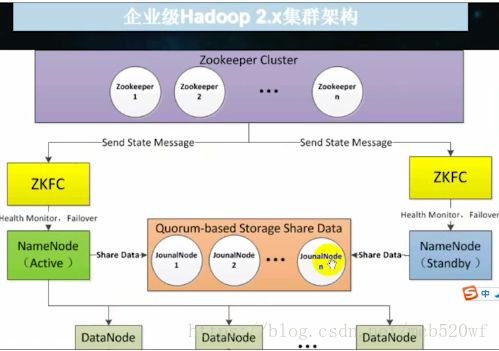
解决问题1:通过上面的图我们可以明确的看出来,如果的的Namenode坏掉了,那我们的整个集群可以说就是要瘫痪了也就是单节点故障问题。
于是现在就出现了另外一张图,我截取的〜在这儿我们看到有两个名称节点,一个是(Acticve),另外一个是待机。
该图特点:
1,他们被上面ZKFS - ZK转移控制器操控。
2,他们质检也可以进行共享元数据。
3,他们被Zookeeper Cluster进行监控协调。
在这里没有secondaryNamenode,却分为了两处。也就是说,一个是正在活跃使用的,另外一个就是随时待命的。
Hdfs ha几大重点:
(1)保证两个名称节点里面的内存中的存储文件元数据同步,名称节点启动时会读镜像文件。
(2)变化的记录信息同步。
(3)日志文件的安全性。分布式的存储日志文件(2N + 1)基数个。使用动物园管理员进行监控.zookeeper对时间同步要求比较高。
(4)客户端如何知道访问哪一个namenode.1,使用代理代理0.2,隔离机制0.3,使用sshfence.4,两个namenome之间无密码登录。
(5)名称节点是哪一个ACTIVE.1,动物园管理员通过选举选出动物园管理员。通过监控,自动排除。
Hadoop2.x官方提供两种HDFS HA解决方案,一种是NFS,另外一种是QJM(由cloudra提出,原理类似于zookeeper)。在这篇文章当中我们使用QJM来完成,主备namenode之间通过一组Journalnode同步元数据信息。一条数据只要成功写入Journalnode就被认为是写入成功。通常配置基数个Journalnode。
二,配置规划
| IP | 主机名 | 节点 |
| 192.168.71.234 | centos01 | namenode,datanode,journalnode,qurnompeerMain,ZKF |
| 192.168.71.235 | centos02 | namenode,datanode,journalnode,qurnompeerMain,ZKF |
| 192.168.71.233 | MyLinux | datanode,journalnode,qurnompeerMain |
设置免登陆
centos01 - > MyLinux,centos01,centos02
centos02 - > MyLinux,centos01,centos02
centos01 < - > centos02
三,HDFS的HA配置
3.1将普通集群进行备份
mv /opt/hadoop-2.7.5 /opt/hadoop-2.7.5_bak
3.2重新解压hadoop,这次我们将目录放在/ user / local下面
tar -zxvf /opt/hadoop-2.7.5.tar.gz -C /usr/local/
3.3修改解压后的目录中vi ./etc/hadoop/hadoop-env.sh修改器jdk目录 - 第一个文件
![]()
3.4修改解压后的目录中vi ./etc/hadoop/core-site.xml
fs.defaultFS
hdfs://qf
hadoop.tmp.dir
/home/hahadoopdata/tmp
io.file.buffer.size
4096
3.5修改解压后的目录中vi ./etc/hadoop/hdfs-site.xml
dfs.block.size
134217728
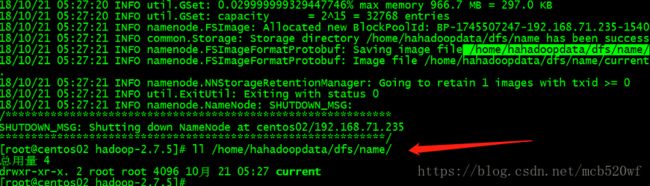
dfs.namenode.name.dir
/home/hahadoopdata/dfs/name
dfs.datanode.data.dir
/home/hahadoopdata/dfs/data
dfs.nameservices
qf
dfs.ha.namenodes.qf
nn1,nn2
dfs.namenode.rpc-address.qf.nn1
centos01:9000
dfs.namenode.rpc-address.qf.nn2
centos02:9000
dfs.namenode.http-address.qf.nn1
centos01:50070
dfs.namenode.http-address.qf.nn2
centos02:50070
dfs.namenode.shared.edits.dir
qjournal://centos01:8485;centos02:8485;MyLinux:8485/qf
dfs.client.failover.proxy.provider.qf
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
dfs.ha.automatic-failover.enabled
true
dfs.ha.fencing.methods
sshfence
dfs.ha.fencing.ssh.private-key-files
/root/.ssh/id_rsa
dfs.ha.fencing.ssh.connect-timeout
30000
dfs.journalnode.edits.dir
/home/hahadoopdata/journal/data
ha.zookeeper.quorum
centos01:2181,centos02:2181,MyLinux:2181
3.6修改解压后的目录中vi ./etc/hadoop/slaves
centos01
centos02
MyLinux3.7配置免登陆
(1)ssh-keygen -t rsa一路回车
(2)ssh-copy-id centos01
ssh-copy-id centos02
ssh-copy-id MyLinux
3.8远程发送配置好的Hadoop的到其他两台机器上去。
scp -r ../hadoop-2.7.5/ centos02:/usr/local/
scp -r ../hadoop-2.7.5/ MyLinux:/usr/local/
四,启动(预先关闭防火墙,或将所有用到的端口允许开启)
(1)启动三台 zkServer.sh start --也就是zookeeper
(2)启动 journalnode 利用 多个进程
(3)启动 namenode
(4)启动start-dfs.sh
4.1启动ZK三台
zkServer.sh start启动
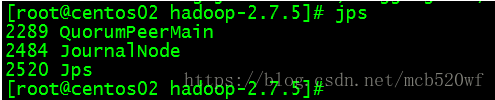
4.2进程启动
单个进程:./sbin/hadoop-daemon.sh start journalnode
多个进程:./sbin/hadoop-daemons.sh start journalnode
4.3选择任意一台名称节点来进行格式化(centos02)
(1)hdfs namenode -format
(2)启动名称节点。
./sbin/hadoop-daemon.sh start namenode

4.4在另外一台名称节点的机子上拉去元数据(也可以使用复制)
hdfs namenode -bootstrapStandby
或者,scp -r/home/hahadoopdata/dfs -C centos01:/home/hahadoopdata/
4.5格式化zkfc
hdfs zkfc -formatZK
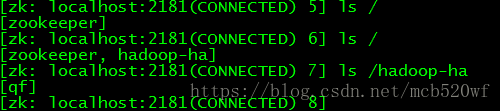
4.6登录zk zkCli.sh查看节点。
4.7启动。./sbin/start-dfs.sh
五,测试
5.1查看对应进程是否均已经启动。成功

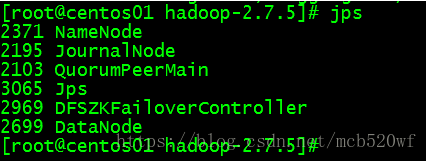
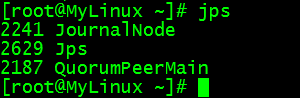
5.2查看web ui是否正常启动成功
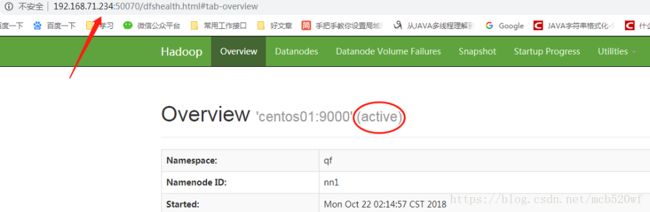
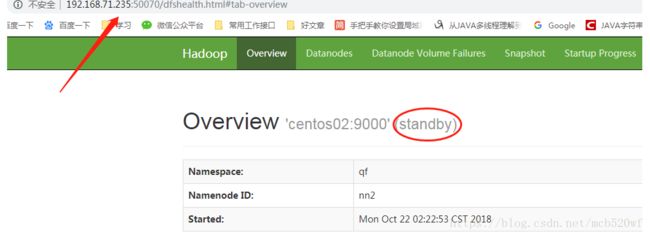
5.3在HDFS读写中文件 成功
上传将本地的文件上传到hdfs文件系统中.hdfs dfs -put /home/test/a.txt /
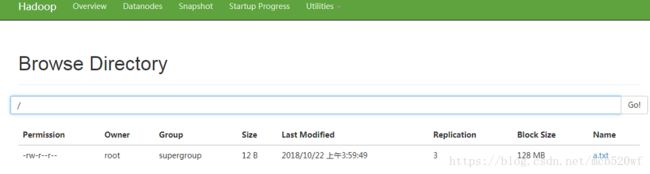
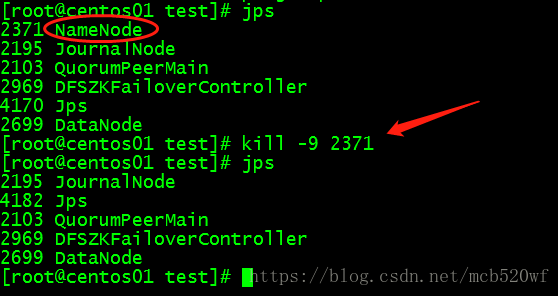
5.4一个名称节点运行停止查看另一个能否自动启动 成功
(1)关闭centos01即处于活性的进程
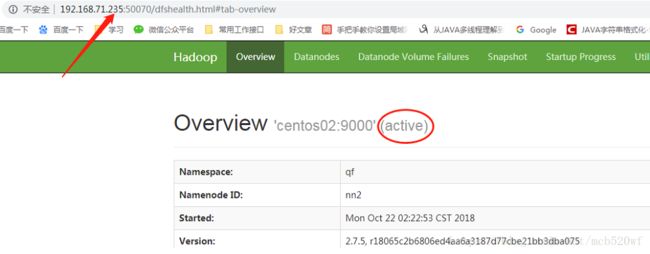
(2)查看centos02的web ui
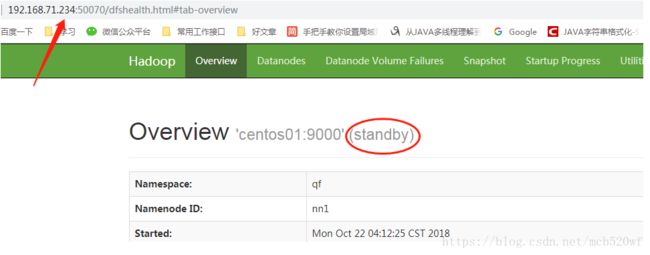
(3)重新启动centos01 ./sbin/hadoop-daemon.sh start namenode
我们发现此时的centos01已经成为待待状态
很棒很棒~~完美完美~~
欢迎订阅公众号(JAVA和人工智能)
获取更过免费书籍资源视频资料

文章超级连接:
1,分布式系统详解 - 基础知识(概论)
2,分布式系统详解 - 基础知识(线程)
3,分布式系统详解 - 基础知识(通信)
4,分布式系统详解 - 基础知识(CAP)
5,分布式系统详解 - 基础知识(安全)
6,分布式系统详解 - 基础知识(并发)
7,分布式系统详解 - 架构简介(微服务)
8,分布式系统详解--linux(权限)
9,分布式系统详解 - 框架(Hadoop-单机版搭建)
10,分布式系统详解 - 架构(Hadoop-克隆服务器)
11,分布式系统详解 - 框架(Hadoop-集群搭建)
12,分布式系统详解 - 框架(Hadoop的-SSH免密登陆配置)
13,分布式系统详解 - 框架(Hadoop的JAVA操作HDFS文件)
14,分布式系统详解 - 框架(Hadoop的RPC协议)
15,分布式系统详解 - 框架(zookeeper-简介和集群搭建)
16,分布式系统详解 - 框架(zookeeper-基本外壳命令)
17,分布式系统详解 - 框架(Hadoop的HDFS的HA搭建及测试)