SQL必知必会总结10 分组数据
如何分组数据,以便汇总表内容的子集。这涉及两个新SELECT 语句子句:GROUP BY 子句和 HAVING 子句。
10.1 数据分组
使用 SQL 聚集函数可以汇总数据。这样,我们就能够对行进行计数,计算和与平均数,不检索所有数据就获得最大值和最小值。目前为止的所有计算都是在表的所有数据或匹配特定的 WHERE 子句的数据上进行的。比如下面的例子返回供应商 DLL01 提供的产品数目:
SELECT COUNT(*) AS num_prods
FROM Products
WHERE vend_id = 'DLL01';
![]()
如果要返回每个供应商提供的产品数目,该怎么办?或者返回只提供一项产品的供应商的产品,或者返回提供 10 个以上产品的供应商的产品,怎么办?
这就是分组大显身手的时候了。使用分组可以将数据分为多个逻辑组,对每个组进行聚集计算。
10.2 创建分组
分组是使用 SELECT 语句的 GROUP BY 子句建立的。
SELECT vend_id, COUNT(*) AS num_prods
FROM Products
GROUP BY vend_id;
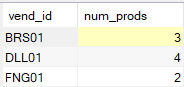
GROUP BY 子句指示DBMS 按 vend_id 排序并分组数据。
在使用 GROUP BY 子句前,需要知道一些重要的规定。
GROUP BY 子句可以包含任意数目的列,因而可以对分组进行嵌套,更细致地进行数据分组。
如果在 GROUP BY 子句中嵌套了分组,数据将在最后指定的分组上进行汇总。换句话说,在建立分组时,指定的所有列都一起计算(所以不能从个别的列取回数据)。
GROUP BY 子句中列出的每一列都必须是检索列或有效的表达式(但不能是聚集函数)。如果在 SELECT 中使用表达式,则必须在 GROUP BY子句中指定相同的表达式。不能使用别名。
大多数 SQL 实现不允许 GROUP BY 列带有长度可变的数据类型(如文本或备注型字段)。
除聚集计算语句外,SELECT 语句中的每一列都必须在 GROUP BY 子句中给出。
如果分组列中包含具有 NULL 值的行,则 NULL 将作为一个分组返回。如果列中有多行 NULL 值,它们将分为一组。
GROUP BY 子句必须出现在 WHERE 子句之后,ORDER BY 子句之前。
提示:ALL 子句
Microsoft SQL Server 等有些 SQL 实现在 GROUP BY 中支持可选的 ALL子句。这个子句可用来返回所有分组,即使是没有匹配行的分组也返回(在此情况下,聚集将返回 NULL)。具体的 DBMS 是否支持 ALL,请参阅相应的文档
注意:通过相对位置指定列
有的 SQL 实现允许根据 SELECT 列表中的位置指定 GROUP BY 的列。例如,GROUP BY 2, 1 可表示按选择的第二个列分组,然后再按第一个列分组。虽然这种速记语法很方便,但并非所有 SQL 实现都支持,并且使用它容易在编辑 SQL 语句时出错。
10.3 过滤分组
除了能用 GROUP BY 分组数据外,SQL 还允许过滤分组,规定包括哪些分组,排除哪些分组。SQL 为此提供了另一个子句,就是HAVING 子句。HAVING 非常类似于 WHERE。事实上,目前为止所学过的所有类型的 WHERE 子句都可以用 HAVING 来替代。唯一的差别是,WHERE过滤行,而 HAVING 过滤分组。
提示:HAVING 支持所有 WHERE 操作符
在第 4 课和第 5 课中,我们学习了 WHERE 子句的条件(包括通配符条件和带多个操作符的子句)。学过的这些有关 WHERE 的所有技术和选项都适用于 HAVING。它们的句法是相同的,只是关键字有差别。
SELECT cust_id, COUNT(*) AS orders
FROM Orders
GROUP BY cust_id
HAVING COUNT(*) >= 2;
![]()
这条 SELECT 语句的前三行类似于上面的语句。最后一行增加了 HAVING子句,它过滤 COUNT(*) >= 2(两个以上订单)的那些分组。
说明:HAVING 和 WHERE 的差别
这里有另一种理解方法,WHERE 在数据分组前进行过滤,HAVING 在数据分组后进行过滤。这是一个重要的区别,WHERE 排除的行不包括在分组中。这可能会改变计算值,从而影响 HAVING 子句中基于这些值过滤掉的分组。
那么,有没有在一条语句中同时使用 WHERE 和 HAVING 子句的需要呢?事实上,确实有。假如想进一步过滤上面的语句,使它返回过去 12个月内具有两个以上订单的顾客。为此,可增加一条 WHERE 子句,过滤出过去 12个月内下过的订单,然后再增加 HAVING 子句过滤出具有两个以上订单的分组。
为了更好地理解,来看下面的例子,它列出具有两个以上产品且其价格大于等于 4 的供应商:
SELECT vend_id, COUNT(*) AS num_prods
FROM Products
WHERE prod_price >= 4
GROUP BY vend_id
HAVING COUNT(*) >= 2;
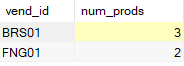
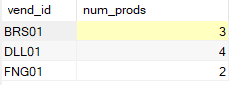
如果没有 WHERE子句,就会多检索出一行(供应商 DLL01,销售 4 个产品,价格都在 4以下):
SELECT vend_id, COUNT(*) AS num_prods
FROM Products
GROUP BY vend_id
HAVING COUNT(*) >= 2;
说明:使用 HAVING 和 WHERE
HAVING 与 WHERE 非常类似,如果不指定 GROUP BY,则大多数 DBMS会同等对待它们。不过,你自己要能区分这一点。使用 HAVING 时应该结合 GROUP BY 子句,而 WHERE 子句用于标准的行级过滤。
10.4 分组和排序
GROUP BY 和 ORDER BY 经常完成相同的工作,但它们非常不同,理解这一点很重要。表 10-1 汇总了它们之间的差别。

提示:不要忘记 ORDER BY
一般在使用 GROUP BY 子句时,应该也给出 ORDER BY 子句。这是保证数据正确排序的唯一方法。千万不要仅依赖 GROUP BY 排序数据。
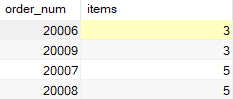
为说明GROUP BY和ORDER BY的使用方法,来看一个例子。下面的SELECT语句类似于前面那些例子。它检索包含三个或更多物品的订单号和订购物品的数目:
SELECT order_num, COUNT(*) AS items
FROM OrderItems
GROUP BY order_num
HAVING COUNT(*) >= 3;
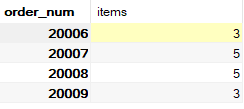
要按订购物品的数目排序输出,需要添加 ORDER BY 子句,如下所示:
SELECT order_num, COUNT(*) AS items
FROM OrderItems
GROUP BY order_num
HAVING COUNT(*) >= 3
ORDER BY items, order_num;
说明:Access 的不兼容性
Microsoft Access不允许按别名排序,因此这个例子在 Access中将失败。解决方法是用实际的计算或字段位置替换 items(在 ORDER BY 子句中), 即 ORDER BY COUNT(*), order_num 或 ORDER BY 2, order_num。
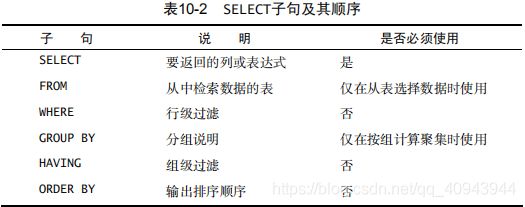
10.5 SELECT 子句顺序
下面回顾一下 SELECT 语句中子句的顺序。表 10-2 以在 SELECT 语句中使用时必须遵循的次序,列出迄今为止所学过的子句。
10.6 小结
总结9介绍了如何用 SQL 聚集函数对数据进行汇总计算。总结10阐述了如何使用 GROUP BY 子句对多组数据进行汇总计算,返回每个组的结果。我们看到了如何使用 HAVING 子句过滤特定的组,还知道了 ORDER BY和 GROUP BY 之间以及 WHERE 和 HAVING 之间的差异。