题目如下:





import requests as r import json url="https://edu.cnblogs.com/Homework/GetAnswers?homeworkId=2420&_=1543832146743" try: myhead = {'user-agent':'Mozilla/5.0'} wb = r.get(url,headers=myhead,timeout=100) wb.raise_for_status() #状态码不为200,引发HTttpERROR异常 wb.encoding = wb.apparent_encoding key1 = wb.text except: print ("ERROR!") #json.load返回字典类型,获取data索引后的信息,即目标json信息 json1=json.loads(key1)['data'] #现在json1是列表了,开始逐行取信息,写到文件中 #注意学号用字符串保存,否则在excel中会按数字处理,即用科学计数法表示 #提交时间中,日期和时间中有个‘T’,用replace替换掉 keydata=' ' with open('hwlist.csv','w') as keyfile: for index in json1: keyfile.write(str(index['StudentNo'])+','+index['RealName']+','+index['DateAdded'].replace('T',' ')+','+index['Title']+','+index['Url']+'\n') #有毒,明明IDE上缩进是对的
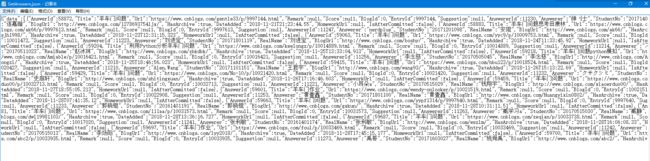
hwlist.csv打开后如下:好像是我excel设置的问题,日期无法好好显示,不过看单元格值应该是正确的

附:
其实上面的方法并不是我的本意…
我一开始看到目标文件是csv,就想到了解析大数据的神器——panda库。
panda库里的read_json可以把json字符串文件解析为panda自带的数据类型——Series或者Dataframe(直观的看上去就是一维数组与二维数组)
然后利用to_csv可以直接实现把数据转为csv文件格式。(当然也有to_txt,to_excel等等,很强大的库)
先看下我的代码:
import requests as r import json import pandas as pd url="https://edu.cnblogs.com/Homework/GetAnswers?homeworkId=2420&_=1543832146743" keyweb = r.get(url) json1= json.loads(keyweb.text)['data'] keyjson = json.dumps(json1) keytable = pd.read_json(keyjson) #keytable.to_csv('pre1.csv') keytable.to_csv('pre2.csv',columns=['StudentNo', 'RealName','Title','DateAdded','Url'],index=False,header=True)
处理源数据的手法都类似。不同的是,我们处理完json数据之后。再用json.dumps把处理好的数据转回为json字符串格式。
然后调用panda库的read_json方法,把这个json字符串转为panda库的dataframe格式。
可以type一下,一目了然。

看上去万事俱备了,我们直接to_csv一波。
keytable.to_csv('pre1.csv')
问题出现了:是解析成了一个csv表不错,但是好多列都是我们不需要的。(包括莫名其妙的索引)

还好,to_csv方法给我们提供了参数来解决这些问题。
keytable.to_csv('pre2.csv',columns=['StudentNo', 'RealName','Title','DateAdded','Url'],index=False,header=True)
columns=['1’,'2'…]:只保留某些列的内容,这里我们保存学号,姓名,标题,提交时间,网址这些列
index=False:不写默认是true,会在第一列添加一列索引。且默认从0开始,我们用excel浏览,不太需要。X掉。
header=True:保留表头,位置在全表第一行。不写默认是true.
于是处理后的pre2.csv如下:
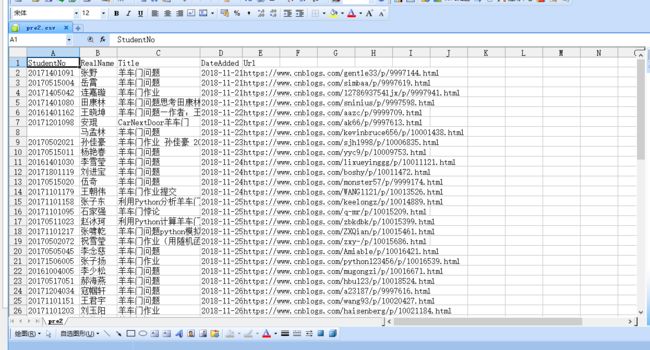
看上去问题解决了?不然:
我在其中遇到最大的问题就是:提交时间中那个“T”到底怎么处理掉?
有一位仁兄也用的panda库完成的作业,我参考了一下:是先把json数据处理好后,用panda库的DataFrame()将其转换成dataframe格式,并用colums给每个列命名,之后再用to_csv解析成csv格式。
这不失为一种很好的解决方案。
那么,可以不可以对我这种“暴力”转换的dataframe格式中的数据直接进行查值替换这类的操作呢?
研究了半天,最后也没有解决,可能是对panda库操作还是太少。希望有人能指点一下,不胜感激。
总结:
爬虫对我来说并不新鲜,但我却一直没有多加应用。
爬虫并不是get个url,直接.text这么简单的。
对于requests库的掌握都有些生疏。更不要提bs4和re这些了,对于信安专业的学生,不客气的说,这是不可原谅的。
努力弥补吧。