HiveSQL行转列lateral view explore()以及连接concat_ws()和列转行collect_list()&collect_set()区别的使用案例
行转列:
在我们使用hive进行数据统计分析时可能有这么一个场景:
一行数据中,一个字段中有很多和数据项,我们需要对每个数据项进行一个统计分析。
例如:一个人有很多人生的重要阶段,我们有一批人,求在某个阶段的人的总数
uid,stage
1,jiehun:shengzi:maiche
2,maiche:maifang
3,maifang:jiehun
4,dushu:maiche
5,dushu:maifang:jiehun
6,shangban:maiche
7,shangban:maifang:jiehun
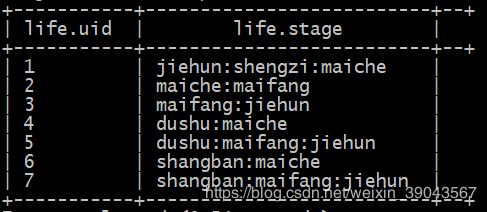
需求:分析 结婚阶段的多少人,买车阶段的多少人等等,如果我们能把数据变成下列形式的话进行分组聚合就简单了,就是把stages这一列打开,对应到每个人,这样我们直接按照stage分组,聚合一下就是结果。
uid ,stage
1,jiehun
1,shengzi
1,maiche
2,maiche
2,maifang
3,maifang
3,jiehun
4,dushu
4,maiche
5,dushu
5,maifang
5,jiehun
6,shangban
6,maiche
7,shangban
7,maifang
7,jiehun
lateral view explore()正好帮我们做了这件事,
1、建表导数据
create table life(uid int,stage string)
row format delimited
fields terminated by ',';
load data local inpath '/root/mytest/life.dat' into table life;
2、变成我们想要的形式:
select uid,ustage from life lateral view explode(split(stage,':')) temp as ustage;

3、查询
select ustage,count(distinct uid) as cnts
from life lateral view explode(split(stage,':')) lifetemp as ustage
group by ustage
order by cnts desc;

列转行:
同上,如果我们有一下这样的数据:
uid ,stage
1,jiehun
1,shengzi
1,maiche
2,maiche
2,maifang
3,maifang
3,jiehun
4,dushu
4,maiche
5,dushu
5,maifang
5,jiehun
6,shangban
6,maiche
7,shangban
7,maifang
7,jiehun
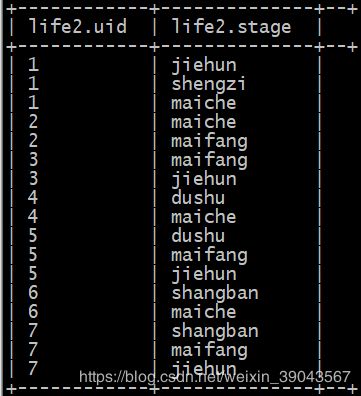
每个人对应的人生阶段都是散开的,不易于观察。我们想要把每人的人生阶段都放到一起,这样可以使用concat_ws()进行处理:
1、建表导数据
create table life2(uid int,stage string)
row format delimited
fields terminated by ',';
load data local inpath '/root/mytest/life2.dat' into table life2;
2、进行连接处理
select uid,
concat_ws(':',collect_set(stage)) as stages
from life2 group by uid;

concat_ws(':',collect_set(stage)) ':' 表示你合并后用什么分隔,collect_set(stage)表示要合并表中的那一列数据
collect_set()和collect_list()都是对列转成行,区别就是list里面可重复而set里面是去重的。