hashSet重写-重复equals方法-实现定向去重
1.hashSet重写-重复equals方法-实现定向去重
一.出现的问题是:
想通过SET来实现对类中重复类进行去除,但是类中有些字段重复就认定该类型为重复类型
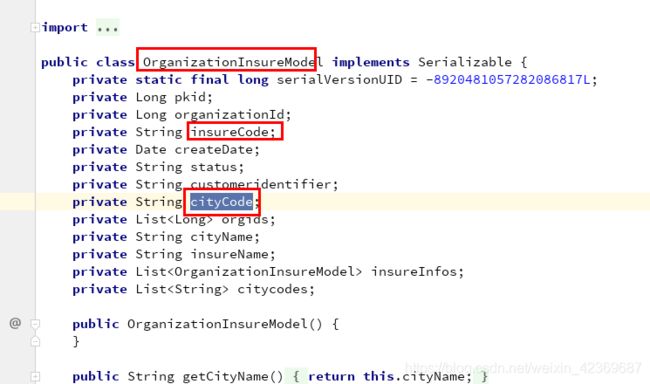
想要变成:上面两个字段重复,便认为以上类型重复
解决方案:
通过SET去除重复:
1.需要重写hashSet里的方法:
学习hashSet的方法过程:
hashSet判断两个对象是否相等,会进行比较hashCode与equals方法
1:会先调用对象的hashCode方法获得hash的值,如果set中哈希表里面没有对应的hash值,则就认定,对象不存在重复的问题。
2:如果set中hash表里面有对应的hash值,就让后面的对象调用equals方法和之前的hash值不同的对象进行比较,如果返回为true就证明存在,不在储存,入伙返回为false则视为新对象,加入到set中。
这是实现原理:
1.HashSet原理 ◦我们使用Set集合都是需要去掉重复元素的, 如果在存储的时候逐个equals()比较, 效率较低,哈希算法提高了去重复的效率, 降低了使用equals()方法的次数
当HashSet调用add()方法存储对象的时候, 先调用对象的hashCode()方法得到一个哈希值, 然后在集合中查找是否有哈希值相同的对象 ◾如果没有哈希值相同的对象就直接存入集合,如果有哈希值相同的对象, 就和哈希值相同的对象逐个进行equals()比较,比较结果为false就存入, true则不存
2.将自定义类的对象存入HashSet去重复 ◦类中必须重写hashCode()和equals()方法hashCode(): 属性相同的对象返回值必须相同, 属性不同的返回值尽量不同(提高效率)equals(): 属性相同返回true, 属性不同返回false,返回false的时候存储。
什么是hashCode?
hashCode方法的主要作用是为了配合基于散列的集合一起正常运行,这样的散列集合包括HashSet、HashMap以及HashTable。考虑一种情况,当向集合中插入对象时,如何判别在集合中是否已经存在该对象了?(注意:集合中不允许重复的元素存在)也许大多数人都会想到调用equals方法来逐个进行比较,这个方法确实可行。但是如果集合中已经存在一万条数据或者更多的数据,如果采用equals方法去逐一比较,效率必然是一个问题。此时hashCode方法的作用就体现出来了,当集合要添加新的对象时,先调用这个对象的hashCode方法,得到对应的hashcode值,实际上在HashMap的具体实现中会用一个table保存已经存进去的对象的hashcode值,如果table中没有该hashcode值,它就可以直接存进去,不用再进行任何比较了;如果存在该hashcode值, 就调用它的equals方法与新元素进行比较,相同的话就不存了,不相同就散列其它的地址,所以这里存在一个冲突解决的问题,这样一来实际调用equals方法的次数就大大降低了,说通俗一点:Java中的hashCode方法就是根据一定的规则将与对象相关的信息(比如对象的存储地址,对象的字段等)映射成一个数值,这个数值称作为散列值。即在散列集合包括HashSet、HashMap以及HashTable里,对每一个存储的桶元素都有一个唯一的"块编号",即它在集合里面的存储地址;当你调用contains方法的时候,它会根据hashcode找到块的存储地址从而定位到该桶元素。
设计hashCode()时最重要的因素就是:无论何时,对同一个对象调用hashCode()都应该产生同样的值。如果在讲一个对象用put()添加进HashMap时产生一个hashCdoe值,而用get()取出时却产生了另一个hashCode值,那么就无法获取该对象了。所以如果你的hashCode方法依赖于对象中易变的数据,用户就要当心了,因为此数据发生变化时,hashCode()方法就会生成一个不同的散列码
简单来讲:通过对象内存地址,字段等,通过hash函数生成一个哈希码,但是可能生成的重复
因此需要对equals对比,来进行确定
什么是equals方法:
Object的equals方法默认比较的是引用(对象地址)
equals方法是定义在所有类的超类object类中的比较方法,所以所有类都会自动继承这个方法,有的类对方法进行了重写,有的类没有对方法进行重写,这时候比较的东西就不一样。
自己定义的类也可以重写自己的equals方法,用比较自己定义的类的实例个体之间是否是相等的。
实现过程:
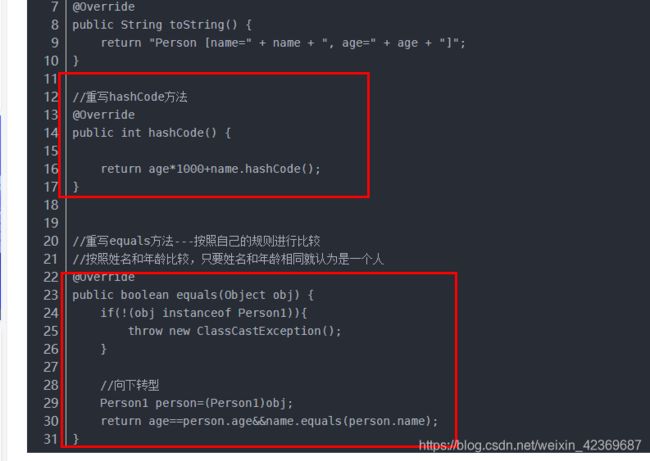
对JavaBean中重写HashCode与equals方法:

这样重写即可
运行效果如下:
运行成功!
参考资料如下
https://blog.csdn.net/ThreeCQscbRONLY1/article/details/81541510
第二种解决方案:
如下一篇所示: