Zookeeper(二) zookeeper集群搭建 与使用
一、zookeeper集群搭建
鉴于 zookeeper 本身的特点,服务器集群的节点数推荐设置为奇数台。我这里我规划为三台, 为别为 hadoop01,hadoop02,hadoop03
1、下载地址: http://mirrors.hust.edu.cn/apache/zookeeper/
版本号: zookeeper-3.4.7.tar.gz
2、解压安装到自己的目录
tar -zxvf zookeeper-3.4.7.tar.gz -C apps/
3、修改配置文件
cd conf/
mv zoo_sample.cfg zoo.cfg
vi zoo.cfg



二、启动软件,并验证安装是否成功

三、zookeeper集群使用
1、cli使用
首先,我们可以是用命令 bin/zkCli.sh 进入 zookeeper 的命令行客户端,这种是直接连接本机 的 zookeeper 服务器,还有一种方式,可以连接其他的 zookeeper 服务器,只需要我们在命 令后面接一个参数-server 就可以了。 例如: zkCli.sh –server hadoop01:2181
进入命令行之后,键入 help 可以查看简易的命令帮助文档,

znode 数据信息字段解释



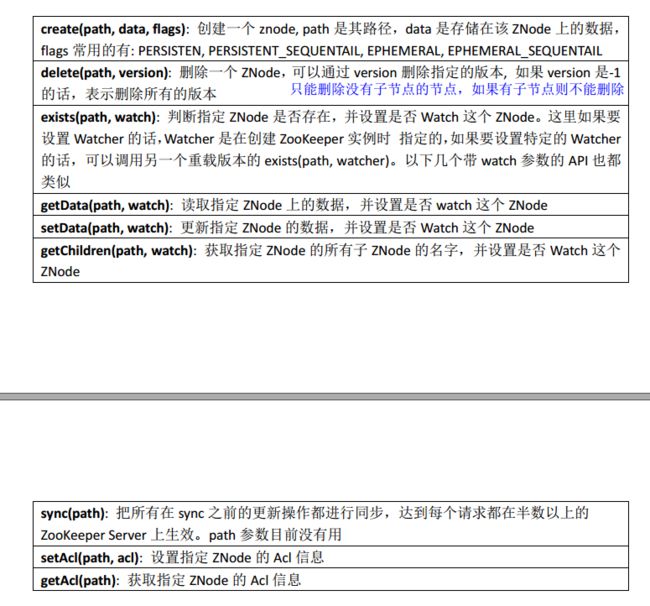
2、zookeeper Java API 使用
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
|
package
com.ghgj.zkapi;
import
java.text.SimpleDateFormat;
import
java.util.Date;
import
java.util.List;
import
org.apache.zookeeper.CreateMode;
import
org.apache.zookeeper.KeeperException;
import
org.apache.zookeeper.ZooDefs.Ids;
import
org.apache.zookeeper.ZooKeeper;
import
org.apache.zookeeper.data.Stat;
public
class
ZKAPIDEMO {
// 获取zookeeper连接时所需要的服务器连接信息,格式为主机名:端口号
private
static
final
String ConnectString =
"hadoop02:2181"
;
// 请求了解的会话超时时长
private
static
final
int
SessionTimeout =
5000
;
public
static
void
main(String[] args)
throws
Exception {
/**
* 获取zookeeper链接, 要求的连接参数至少有三个: ConnectString:服务器的连接信息
* SessionTimeout:请求连接的超时时长 Watch:添加监听器
*/
ZooKeeper zk =
new
ZooKeeper(ConnectString, SessionTimeout,
null
);
// 根据拿到的zk连接去做相应的操作
// 查看节点数据
// byte[] data = zk.getData("/ghgj/hadoop", false, null);
// System.out.println(new String(data));
// 查看子节点的信息
// String parentNodePath = "/ghgj";
// List
// for(String child : childrens){
// System.out.println(parentNodePath+"/"+child);
// }
// 修改节点的数据
// Stat setData = zk.setData("/ghgj/hadoop",
// "hadoopsprakjsdlfkj".getBytes(), -1);
// long mtime = setData.getMtime();
// SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd hh:mm:ss");
// System.out.println(sdf.format(new Date(mtime)));
// 添加持久节点znode
String addPathnode =
"/spark/node"
;
String path = zk.create(addPathnode,
"node"
.getBytes(),
Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT_SEQUENTIAL);
System.out.println(path);
// 添加短暂型节点
// String addPathnode1 = "/ghgj/hive1";
// String path1 = zk.create(addPathnode1, "hive1".getBytes(),
// Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL);
// System.out.println(path1);
// Thread.sleep(5000);
// 删除一个带有多级子节点的znode
// boolean rmr = rmr("/zk", zk);
// System.out.println(rmr?"删除成功":"删除失败");
zk.close();
}
public
static
Stat exists(String path, ZooKeeper zk)
throws
Exception {
Stat exists = zk.exists(
"/ghgj/hadoop"
,
false
);
if
(
null
!= exists) {
System.out.println(
"该节点/ghgj/hadoop还存在"
);
return
exists;
}
else
{
System.out.println(
"该节点/ghgj/hadoop不存在"
);
return
null
;
}
}
public
static
boolean
rmr(String path, ZooKeeper zk)
throws
Exception {
// 判断节点存在不存在
Stat stat = exists(path, zk);
// if (stat.getNumChildren() == 0) {
List
false
);
if
(children.size() ==
0
) {
// 删除节点
zk.delete(path, -
1
);
}
else
{
// 要删除这个有子节点的父节点,那么就需要先删除所有子节点,然后再删除该父节点,完成对该节点的级联删除
// 删除有子节点的父节点下的所有子节点
for
(String nodeName : children) {
System.out.println(path);
rmr(path +
"/"
+ nodeName, zk);
}
// 删除该父节点
rmr(path, zk);
}
return
true
;
}
}
|