WIN10中文乱码修复合集
最近被中文乱码害惨了,所以做个中文修复合集吧!
WIN10中文乱码修复
- 解决中文乱码问题
- 方法一:更改区域设置解决中文乱码
- 方法二:修改注册表解决中文乱码
- 方法三:右键菜单乱码(只针对文本文件写入有效)
- UTF-8与GBK的爱恨情仇
- 各种编码详解
- ASCII
- GB2312
- GBK
- GB18030
- UTF-8
- UTF-8,GBK,ANSI之间的关系和区别
解决中文乱码问题
一个清单大概包含了CSDN中所有解决此问题的办法
无论WIN10还是WIN7
学识浅薄,如有任何意见建议欢迎各位批评指正!
本方案基本解决以下乱码问题(包括但不限于)
- TXT阅读乱码(方法1)
- WINRAR等解压缩中文文件夹乱码(方法1)
- 右键菜单乱码←请参阅
- 资源管理器中文件夹乱码(方法1或方法2)
- 关于系统DOS(CMD)的中文乱码修复←请参阅
- 英文系统中查阅中文文件出现乱码←请参阅
- 等等诸多问题
方法一:更改区域设置解决中文乱码
动图来自:win10消除乱码

下面为详细操作步骤
————————————————
环境为:WIN10_1909
设置为中国(简体,中国),且取消勾选
beta版本,使用UTF-8提供全球语言支持*
确定后进行重启
若没有解决你的问题,请参阅方法二
方法二:修改注册表解决中文乱码
方法一为最基础的设置解决办法
本章节为最广的且最有效的解决方法:
运行注册表regedit
打开键 计算机\HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\FontAssoc\Associated Charset
点击Associated Charset项,在其目录下新建字符串值,并修改名称与数据数值:
| 名称 | 类型 | 数据 |
|---|---|---|
| ANSI ( 00) | REG_SZ | YES |
| GB2312(86) | REG_SZ | YES |
| OEM(FF) | REG_SZ | YES |
| SYMBOL(02) | REG_SZ | NO |
| WEM(FF) | REG_SZ | YES |
如果没有则自己创建:(右键→新建→字符串值)
在一些版本中,此法可解决一些乱码问题,
但是仍有部分软件存在乱码,
在较新版本中,系统本身都已经把这两项设置成YES了,
但还是有乱码。要解决这些,还得做下一步工作
打开注册表键 计算机\HKEY_CURRENT_USER\Control Panel\International
将右侧:“Locale”=“00000409″ 改成 ”Locale“=”00000804″。然后再修改完确定之后重新启动电脑。
系统出现乱码现象,可能是系统病毒导致,可能是文件错乱导致,如果用户在系统下遇到同样的问题时,试试以上的步骤,把乱码赶出系统。
转自:http://www.xitongcheng.cc/xtjc/108.html
在执行了以上所有操作之后如果您还和我一样右键菜单依旧是乱码!那不妨您耐得住性子,再和我做这一步
注意方法三只适用于reg文件
例如:您想在系统的右键菜单中加入一个**在当前位置打开cmd**这个选项的话出现了乱码,
或者是使用reg进行注册导入使用:**取得管理员权限**的右键菜单项的话,那您找对了这个方法绝对适合您
方法三:右键菜单乱码(只针对文本文件写入有效)
请更改您的reg文件的保存类型
例如:以下代码是为了获取win10系统的指定文件夹管理权限的需要复制保存到本地的txt文件中并更改格式为
.reg进行使用
Windows Registry Editor Version 5.00
[HKEY_CLASSES_ROOT\*\shell\runas]
@="取得管理权限"
"Icon"="cmd.exe"
"NoWorkingDirectory"=""
[HKEY_CLASSES_ROOT\*\shell\runas\command]
@="cmd.exe /c takeown /f \"%1\" && icacls \"%1\" /grant administrators:F"
"IsolatedCommand"="cmd.exe /c takeown /f \"%1\" && icacls \"%1\" /grant administrators:F"
[HKEY_CLASSES_ROOT\exefile\shell\runas2]
@="取得管理权限"
"Icon"="cmd.exe"
"NoWorkingDirectory"=""
[HKEY_CLASSES_ROOT\exefile\shell\runas2\command]
@="cmd.exe /c takeown /f \"%1\" && icacls \"%1\" /grant administrators:F"
"IsolatedCommand"="cmd.exe /c takeown /f \"%1\" && icacls \"%1\" /grant administrators:F"
[HKEY_CLASSES_ROOT\Directory\shell\runas]
@="取得管理权限"
"Icon"="cmd.exe"
"NoWorkingDirectory"=""
[HKEY_CLASSES_ROOT\Directory\shell\runas\command]
@="cmd.exe /c takeown /f \"%1\" /r /d y && icacls \"%1\" /grant administrators:F /t"
"IsolatedCommand"="cmd.exe /c takeown /f \"%1\" /r /d y && icacls \"%1\" /grant administrators:F /t"
请注意txt进行保存的时候请先执行以下步骤!!!
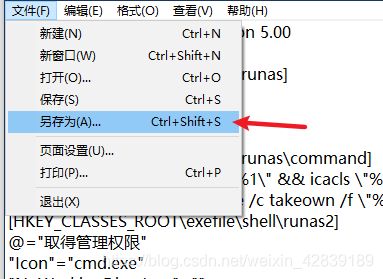
请另存为其他编码的文件如下图
保存之后再执行就会正常!
UTF-8与GBK的爱恨情仇
以上为全部的解决问题的步骤
那么为什么会出现这些问题呢?
本篇文章围绕UTF-8与GBK的差异,来具体了解系统会出现乱码的原因
学识浅薄,如有任何意见建议欢迎各位批评指正!
本节源自:UTF-8和GBK的区别——CSDN
各种编码详解
ASCII(ISO-8859-1)是鼻祖,最简单的方式,字节高位为0
GB2312、GBK、GB18030,这几个是中文编码方式,并向下兼容。
GB2312包含7000多个汉字和字符,GBK包含21000多个,GB18030更厉害,到了27000多个。
他们都是用2个字节来表示一个汉字。跟ascii是怎么区分的呢?如果高字节的高位为1(也就是高字节大于127),就表示是汉字,低字节并无明显特征。
ASCII
ASCII码是7位编码,编码范围是0x00-0x7F。ASCII字符集包括英文字母、阿拉伯数字和标点符号等字符。其中0x00-0x20和0x7F共33个控制字符。
只支持ASCII码的系统会忽略每个字节的最高位,只认为低7位是有效位。HZ字符编码就是早期为了在只支持7位ASCII系统中传输中文而设计的编码。早期很多邮件系统也只支持ASCII编码,为了传输中文邮件必须使用BASE64或者其他编码方式。
GB2312
GB2312是基于区位码设计的,区位码把编码表分为94个区,每个区对应94个位,每个字符的区号和位号组合起来就是该汉字的区位码。区位码一般 用10进制数来表示,如1601就表示16区1位,对应的字符是“啊”。在区位码的区号和位号上分别加上0xA0就得到了GB2312编码。
区位码中01-09区是符号、数字区,16-87区是汉字区,10-15和88-94是未定义的空白区。它将收录的汉字分成两级:第一级是常用汉字计3755个,置于16-55区,按汉语拼音字母/笔形顺序排列;第二级汉字是次常用汉字计3008个,置于56-87区,按部首/笔画顺序排列。一级汉字是按照拼音排序的,这个就可以得到某个拼音在一级汉字区位中的范围,很多根据汉字可以得到拼音的程序就是根据这个原理编写的。
GB2312字符集中除常用简体汉字字符外还包括希腊字母、日文平假名及片假名字母、俄语西里尔字母等字符,未收录繁体中文汉字和一些生僻字。可以用繁体汉字测试某些系统是不是只支持GB2312编码。
GB2312的编码范围是0xA1A1-0x7E7E,去掉未定义的区域之后可以理解为实际编码范围是0xA1A1-0xF7FE。
EUC-CN可以理解为GB2312的别名,和GB2312完全相同。
区位码更应该认为是字符集的定义,定义了所收录的字符和字符位置,而GB2312及EUC-CN是实际计算机环境中支持这种字符集的编码。HZ和ISO-2022-CN是对应区位码字符集的另外两种编码,都是用7位编码空间来支持汉字。区位码和GB2312编码的关系有点像 Unicode和UTF-8。
GBK
GBK编码是GB2312编码的超集,向下完全兼容GB2312,同时GBK收录了Unicode基本多文种平面中的所有CJK汉字。同 GB2312一样,GBK也支持希腊字母、日文假名字母、俄语字母等字符,但不支持韩语中的表音字符(非汉字字符)。GBK还收录了GB2312不包含的汉字部首符号、竖排标点符号等字符。
GBK的整体编码范围是为0x8140-0xFEFE,不包括低字节是0×7F的组合。高字节范围是0×81-0xFE,低字节范围是0x40-7E和0x80-0xFE。
低字节是0x40-0x7E的GBK字符有一定特殊性,因为这些字符占用了ASCII码的位置,这样会给一些系统带来麻烦。
有些系统中用0x40-0x7E中的字符(如“|”)做特殊符号,在定位这些符号时又没有判断这些符号是不是属于某个 GBK字符的低字节,这样就会造成错误判断。在支持GB2312的环境下就不存在这个问题。需要注意的是支持GBK的环境中小于0x80的某个字节未必就是ASCII符号;另外就是最好选用小于0×40的ASCII符号做一些特殊符号,这样就可以快速定位,且不用担心是某个汉字的另一半。Big5编码中也存在相应问题。
CP936和GBK的有些许差别,绝大多数情况下可以把CP936当作GBK的别名。
GB18030
GB18030编码向下兼容GBK和GB2312,兼容的含义是不仅字符兼容,而且相同字符的编码也相同。GB18030收录了所有Unicode3.1中的字符,包括中国少数民族字符,GBK不支持的韩文字符等等,也可以说是世界大多民族的文字符号都被收录在内。
GBK和GB2312都是双字节等宽编码,如果算上和ASCII兼容所支持的单字节,也可以理解为是单字节和双字节混合的变长编码。GB18030编码是变长编码,有单字节、双字节和四字节三种方式。
GB18030的单字节编码范围是0x00-0x7F,完全等同与ASCII;双字节编码的范围和GBK相同,高字节是0x81-0xFE,低字节的编码范围是0x40-0x7E和0x80-FE;四字节编码中第一、三字节的编码范围是0x81-0xFE,二、四字节是0x30-0x39。
其中:
GBK就是在保存你的帖子的时候,一个汉字占用两个字节。。外国人看会出现乱码,此为我中华为自己汉字编码而形成之解决方案。
UTF8就是在保存你的帖子的时候,一个汉字占用3个字节。。但是外国人看的话不会乱码,此为西人为了解决多字节字符而形成之解决方案。
UTF-8
首先Unicode是统一编码,它建立了一个全世界统一的码表。
世界上的所有文字,在这张码表中都是唯一的。
UTF-8是Unicode的一种存储、传输方式。它将整个Unicode码表分为3部分。
0000 - 007F 这部分是最初的ascii部分,按原始的存储方式,即0xxxxxxx。
0080 - 07FF 这部分存储为110xxxxx 10xxxxxx
0800 - FFFF 这部分存储为1110xxxx 10xxxxxx 10xxxxxx
因此,一个汉字究竟被存储为什么,就需要:先查unicode码表,然后根据在码表的位置进行计算。例如:“电”字,在码表中是3575,计算成utf8就是E794B5,而在GB2312的码表中为B5E7
UTF-8的好处:
兼容ASCII,存储英文文件都是单字节,文件小。
当然,当以存中文为主时就变成了3字节编码了,比GB系列还大!
如何标明一个文件是utf-8格式呢?
这个标记是可选的:EF BB BF。
比如:用windows自带的记事本创建一个utf8格式的文件,就会加上这个标记。
但是,如果用ultraedit创建utf-8文件,并不会加上这个标记。
这个标记有个术语,叫做BOM(Byte Order Mark)。不带BOM的utf-8文件和GB2312文件怎么区分呢?我也不知道。唯一能想到的办法就是:先用一种试,如果出现乱码,就用另一种再试
至于UTF-8编码则是用以解决国际上字符的一种多字节编。码,它对英文使用8位(即一个字节),中文使用24位(三个字节)来编码。对于英文字符较多的论坛则用UTF-8节省空间。
UTF-8,GBK,ANSI之间的关系和区别
GBK应该是属于ANSI之中的,在ANSI的国际通用集,GBK是专门来解决中文编码的,是双字节的,不论中英文都是双字节,而UTF-8是才用的另外的一种编码方式,对英文是用8位,对中文使用24位,是和ANSI和GBK 的编码方式是有本质区别的。我们记事本默认的保存时方式是ANSI,并且用不同的编码方式编写的文件必须用对应的编码格式来读取,否则就会出现乱码。
原文链接:https://blog.csdn.net/weixin_42446691/article/details/89639446
版权声明:本文为CSDN博主「56734M」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。