爬取汽车之家所有汽车参数配置
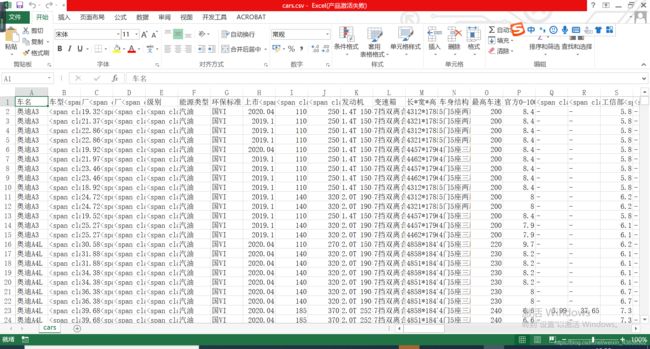
效果预览
汽车之家参数配置的页面无法右键查看网页源代码,不太好爬取,网上相关教程方法比较复杂,这里采用了两步走的爬取方法。即先获取所有车型的网页,再分别解析,逐步拆解。



代码实现
第一步,导入相关库
import bs4
import requests as req
import re
import json
import csv
第二步,下载出所有车型的网页
def mainMethod():
li = [chr(i) for i in range(ord("A"), ord("Z") + 1)]
firstSite = "https://www.autohome.com.cn/grade/carhtml/"
firstSiteSurfixe = ".html"
secondSite = "https://car.autohome.com.cn/config/series/"
secondSiteSurfixe = ".html"
for a in li:
print(a)
if a is not None:
requestUrl = firstSite + a + firstSiteSurfixe
print(requestUrl)
# 开始获取每个品牌的车型
resp = req.get(requestUrl)
# print(str(resp.content,"gbk"))
bs = bs4.BeautifulSoup(str(resp.content, "gbk"), "html.parser")
bss = bs.find_all("li")
co = 0
for b in bss:
d = b.h4
if d is not None:
her = str(d.a.attrs['href'])
her = her.split("#")[0]
her = her[her.index(".cn") + 3:].replace("/", '')
if her is not None:
secSite = secondSite + her + secondSiteSurfixe
car_name = d.a.get_text()
print(car_name)
print("secSite=" + secSite)
resp = req.get(secSite)
text = str(resp.content, encoding="utf-8")
fil = open("E:\\py_shiyan\\Pycharm备份\\搜狐汽车销量采集\\car\\" + str(her) + ".txt", "a",
encoding="utf-8")
fil.write(text)
GetParser(car_name,her)
co = (co + 1)
else:
print(con)
第三步,解析单款车型,并构建循环
def GetParser(car_name,her):
f=open("E:\\py_shiyan\\Pycharm备份\\搜狐汽车销量采集\\car\\" +str(her) + ".txt",'r',encoding='utf-8')
ts=f.read()
data=re.findall('var\sconfig\s=(.*?)time',ts,re.S)
try:
data=data[0][:-2]+"}"
json_data=json.loads(data)
limit = len(json_data['result']['paramtypeitems'][0]['paramitems'][0]['valueitems'])
print(limit)
for z in range(limit):
print(f'======================第{z+1}系列:')
list=[car_name]
for a in json_data['result']['paramtypeitems']:
for b in a['paramitems']:
list.append(b['valueitems'][z]['value'])
print(list)
writer.writerow(list)
except Exception as e:
print(f'{car_name}暂无相关数据')
if __name__ == "__main__":
f = open('cars.csv', mode='a', newline='')
writer = csv.writer(f, delimiter=',')
#title.csv文件为只含有各列标题的表头,可通过代码生成,再手工调整,具体代码见后面附录
f2 = open('title.csv', mode='r', newline='')
reader = csv.reader(f2)
for row in reader:
print(row)
writer.writerow(row)
mainMethod()
以上,即大体流程,得到的数据还需要进行清洗,仅供参考。
附录代码,附上解析推演过程:
import re
import json
import csv
f=open("E:\\py_shiyan\\Pycharm备份\\搜狐汽车销量采集\\car\\2951.txt",'r',encoding='utf-8')
ts=f.read()
# print(ts)
data=re.findall('var\sconfig\s=(.*?)time',ts,re.S)
data=data[0][:-2]+"}"
json_data=json.loads(data)
# print(json_data)
# for x in json_data['result']['paramtypeitems']:
# print(x)
# print(json_data['result']['paramtypeitems'][1])
# for x in json_data['result']['paramtypeitems'][1]['paramitems']:
# print(x)
#长宽高轴距
#长
# print(json_data['result']['paramtypeitems'][1]['paramitems'][0])
# for x in json_data['result']['paramtypeitems'][1]['paramitems'][0]['valueitems']:
# print(x['value'])
# print(json_data['result']['paramtypeitems'][0])
# for x in json_data['result']['paramtypeitems'][0]['paramitems'][0]['valueitems']:
# print(x['value'])
# for a in json_data['result']['paramtypeitems']:
# print(a['name'])
# for b in a['paramitems']:
# print(b['name'])
# print(b['valueitems'])
# print(len(b['valueitems']))
# for c in b['valueitems']:
# print(c['value'])
limit=len(json_data['result']['paramtypeitems'][0]['paramitems'][0]['valueitems'])
print(limit)
for z in range(limit):
print(f'======================第{z+1}系列:')
name=[]
list=[]
for a in json_data['result']['paramtypeitems']:
# print(a['name'])
for b in a['paramitems']:
# print(b['name'],"——",b['valueitems'][z]['value'])
name.append(b['name'])
list.append(b['valueitems'][z]['value'])
# for c in b['valueitems']:
# print(c['value'])
print(name)
print(list)
with open('cars.csv',mode='a',newline='') as f:
writer = csv.writer(f, delimiter=',')
writer.writerow(name)
writer.writerow(list)