Redis集群 安装、命令、API
- Redis集群 安装、命令、API
- window 安装 redis
- java Jedis api:redis集群api JedisCluster、redis连接池api JedisPool
-
Redis 集群搭建、Spring Data Redis使用
-
redis 集群搭建
-
redis报错信息:CLUSTERDOWN Hash slot not served 和 Not all 16384 slots are covered by nodes
linux下的Redis安装
1.第一步:先安装C的编译环境:yum install gcc gcc-c++ libstdc++-devel tcl -y
因为需要使用gcc进行编译才能安装Redis,Redis是基于C语言开发的。
2.第二步:查看是否安装gcc成功,输入gcc或make是否出现以下提示。

3.第三步:可联网下载redis-4.0.10.tar.gz或其他版本的源代码包,并进行安装
1.wget http://download.redis.io/releases/redis-4.0.10.tar.gz
2.tar xzf redis-4.0.10.tar.gz(解压缩)
3.cd redis-4.0.10(进入解压后目录)
4.make(使用make命令会进行编译)
5.make install PREFIX=/usr/local/redis(安装到/usr/local/redis目录下)
4.第四步:进入/usr/local/redis/bin目录下,查看到多个redis的命令文件

Redis服务器端的启动和停止
1.第一步:进入/usr/local/redis/bin目录下,有如下多个redis的命令文件
2.第二步:
1.前台启动模式:在当前/usr/local/redis/bin目录下启动Redis服务器的命令:./redis-server
2.后台启动模式:(每次修改完redis.conf请重新启动Redis服务器并再次指定加载该新修改后的redis.conf)
1.第一步:把 /redis-3.0.0的源码安装包目录下的 redis.conf 拷贝到 /usr/local/redis/bin的安装目录下
cp /root/redis-3.0.0/redis.conf /usr/local/redis/bin
2.第二步:修改/usr/local/redis/bin/redis.conf:修改为 daemonize yes,即把原来的 no 改为 yes,设置为后台运行。
每次修改完redis.conf请重新启动Redis服务器并再次指定加载该新修改后的redis.conf
3.修改redis-server默认绑定的127.0.0.1的IP为具体的IP。
目的:如果redis-server继续使用默认绑定的127.0.0.1的话,那么外部window就无法访问linux内部的redis
vim /usr/local/redis/bin/redis.conf
把 bind 127.0.0.1 修改为 bind 192.168.xx.xxx
4.第三步:在当前/usr/local/redis/bin目录下同时指定redis.conf 启动Redis服务器的命令:./redis-server redis.conf
即Redis服务器加载并应用该redis.conf中的配置信息再进行启动。
3.第三步:查看是否启动成功 
4.第四步:
1.停止 前台模式下的redis服务器:ctrl + c
2.停止 后台模式下的redis服务器:
1.第一种方式:查看到redis-server的进程号,然后执行kill -9 进程号:ps aux|grep redis
2.第二种方式:在/usr/local/redis/bin目录下,使用redis客户端进行停止redis服务器:./redis-cli shutdown
3.第三种方式:执行了./redis-cli进入了redis客户端的输入模式下,执行shutdown命令也可停止redis服务器
Redis客户端的启动和停止
1.第一种启动方式:在/usr/local/redis/bin目录下,执行:./redis-cli
2.第二种启动方式:连接远程linux上的redis服务器,执行:./redis-cli -h 远程linux的IP -p 6379
默认连接localhost运行在6379端口的redis服务。
-h:连接的服务器的地址
-p:服务的端口号
3.第三种启动方式:
1.加上--raw的作用:
在客户端中显示查询出的中文数据时,如果以“/16进制”的形式显示中文数据的话,
那么使用“./redis-cli --raw”在进入客户端,那么查询出的中文数据便能正常以中文字符的形式显示。
2.例子:./redis-cli --raw
./redis-cli -h 远程linux的IP -p 6379 --raw
4.redis客户端下使用ping命令查看redis服务器是否正常运行:
![]()
设置Redis密码
1.测试环境忽略Redis的访问密码,生产环境必须配置Redis的访问密码
2..开启Redis的访问密码:
在/usr/local/redis/bin目录下的redis.conf配置文件中有个参数:“requirepass 密码”。
redis.conf配置文件中默认配置的访问密码被注释掉了,所以首先要取消注释,然后可以修改设置redis访问密码。
修改redis访问密码:requirepass redis访问密码
每次修改完redis.conf请重新启动Redis服务器并再次指定加载该新修改后的redis.conf
3.不重启Redis设置密码:
注意:这种方式设置密码,当redis重启,密码失效。
进入redis客户端(./redis-cli)下,执行“config set requirepass 密码”可以进行设置访问密码;
如果提示需要先输入验证已设置的访问密码的话,那么执行“auth 密码”之后,再执行“config set requirepass 密码”设置新的密码。
4.验证密码的命令:“auth 密码”
在操作Redis数据库中的数据之前,会提示必须先进行密码验证才能继续操作Redis数据库中的数据,所以执行“auth 密码”进行密码验证。
“auth 密码”命令跟其他redis命令一样,是没有加密的;阻止不了攻击者在网络上窃取你的密码;
认证层的目标是提供多一层的保护。如果防火墙或者用来保护redis的系统防御外部攻击失败的话,外部用户如果没有通过密码认证还是无法访问redis的。
Redis五种数据类型

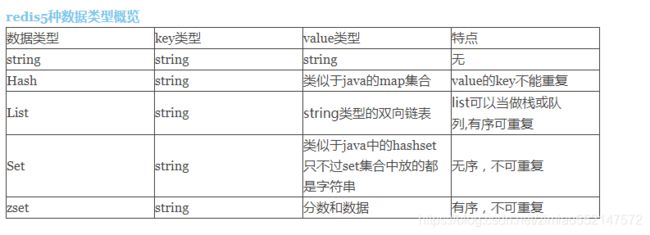
1.Redis相关知识:
Redis内部使用的是单线程:
1.优点:因此即使服务器多线程并发往redis存储数据时,都是数据安全的,因为redis内部仍然是使用单线程进行获取/存储数据的。
2.缺点:redis中不适合存储非常大的数据,因为redis内部仍然是使用单线程进行获取/存储数据的,如果存储很大的数据的话,
那么便会占用比较久的线程,只适合存储较小的数据。
2.Redis五种数据类型:
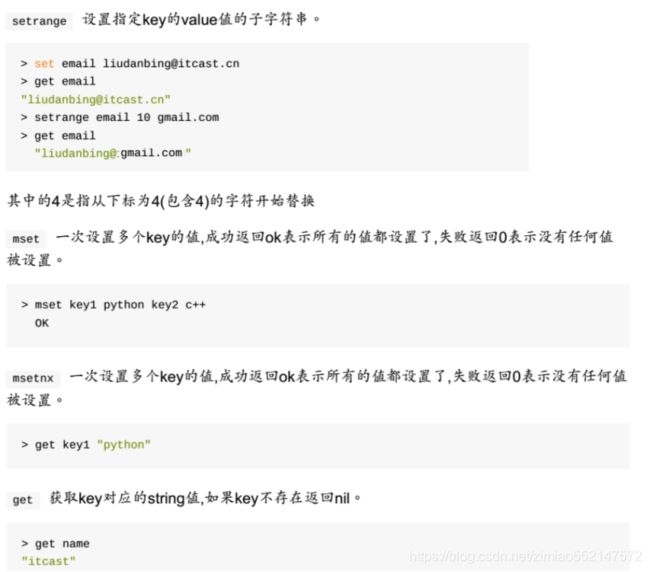
1.String:key-value(做缓存)
1.命令不区分大小写,key区分大小写。
2.存储/获取数据的命令:
1.设置键值:set key value
2.获取键值:get key
3.value加一/减一的命令:
value为字符串类型的数字自动可以进行加一/减一,可用于id自增。
1.value加一:incr key
2.value减一:decr key
2.详细用法:
1.添加数据 set key value
2.删除数据 del key
3.修改数据 set key value
4.查看数据 get key
5.incr key(加1,但是必须是数字)
6.decr key(减1,但是必须是数字)
7.注意:key区分大小写,命令不区分大小写
8.应用场景: 缓存








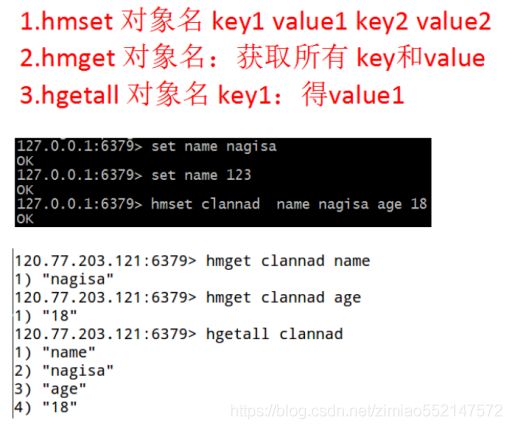
2.Hash:key-fields-values(做缓存)
1.对象名(key) 即相当于 一个key,对象名(key) 还对应一个map。内部使用hash对对象名(key)进行归类。
2.往对象名(key)对应的map中,保存一对键值对:hset 对象名(key) key1 value1
在对象名(key)对应的map中:根据key1获取value1:hget 对象名(key) key1
3.hincrby:
1.给“对象名(key)对应的map中的key1对应的”value1加数值:hincrby 对象名(key) key1 数值
2.如果value1为1,那么执行hincrby 对象名(key) key1 2,value1为3。
4.详细写法:
1.添加数据:
hset person name jack (给key为person的hash中添加一个键值对,键为name值为jack)
hset person age 18 (给key为person的hash中添加一个键值对,键为age值为18)
hset person sex 男 (给key为person的hash中添加一个键值对,键为sex值为男)
上面三个操作可以合并 hmset person name jack age 18 sex 男
2.删除数据:
hdel person name(删除hash类型的person中的某一个键为name的键值对)
del person (删除整个hash类型的person)
3.修改数据:
hset person age 30 (把值30覆盖原有的age对应的值)
4.查看数据:
hget person name (查看hash中某一个键为name的键值对)
hgetall person (查看hash类型的person中所有的数据)
hlen person (查看hash类型的person的长度)
5.应用场景:
1.hash特别适合用于存储对象,效率更高
2.当redis中key多了,为了很好的管理这些key,我们可以使用hash,比如当我们想缓存商品信息,
那我们的key-value应该是:商品id为key,商品的json对象为value,但是商品多了key就多了,
这时候我们可以将这些key-value放入hash中,再给hash取个大key比如叫product,所以我们存储的方式就如下:







3.List(相当于链表的存储方式):有顺序可重复
1.此处的List相当于链表,可快速从链表头和链表尾添加/删除内容。
lpush:往链表头插入新元素,新插入的元素作为新的链表头,往链表头追加新元素;
rpush:往链表尾插入新元素,新插入的元素作为新的链表尾,往链表尾追加新元素;
lrange:从链表头开始遍历;
lpop:获取/弹出的是链表头的元素,那么List即不存在该元素了
rpop:获取/弹出的是链表尾的元素,那么List即不存在该元素了
2.lpush 列表名 元素1 元素2:
往链表头插入新元素,新插入的元素作为新的链表头,往链表头追加新元素;
lpush把“元素1 元素2”从左到右按顺序把元素 插入到列表头(链表头),最新插入的元素作为新的链表头。
3.rpush 列表名 元素1 元素2:
往链表尾插入新元素,新插入的元素作为新的链表尾,往链表尾追加新元素;
rpush把“元素1 元素2”从左到右按顺序把元素 插入到列表尾(链表尾),最新插入的元素作为新的链表尾。
4.lrange 列表名 0 -1:
1.索引-1:表示最后一个索引位的元素,即链表尾的元素。
2.lrange从链表头开始往链表尾方向打印数据。
3.lrange 列表名 索引1 索引2:
要求索引1为链表头方向的索引,索引2为链表尾方向的索引,
即索引1要小于索引2,从链表头开始往链表尾方向移动。
5.lpop、rpop:
1.lpop:获取/弹出的是链表头的元素,那么List即不存在该元素了
2.rpop:获取/弹出的是链表尾的元素,那么List即不存在该元素了


6.常用命令:
1.两端添加:
lpush 列表名 元素1 元素2
rpush 列表名 元素1 元素2
2.两端弹出:
lpop 列表名(左边弹出,弹出的同时会删除弹出的数据)
rpop 列表名(右边弹出,弹出的同时会删除弹出的数据)
3.查看数据:
lrange 列表名 0 -1 (从左到右查看所有的元素)
llen 列表名 (查看list类型的列表的长度)
7.阻塞命令:
1.blpop 列表名 超时时间:
blpop 列表名 100
移出并获取列表的第一个元素, 如果列表没有元素会阻塞列表直到等待超时(100s)或发现可弹出元素为止
2.brpop 列表名 超时时间:
brpop 列表名 100
移出并获取列表的最后一个元素, 如果列表没有元素会阻塞列表直到等待超时(100s)或发现可弹出元素为止
8.redis阻塞原理:
redis在blpop/brpop阻塞命令处理过程时,首先会去查找key对应的list,如果存在,则pop出数据响应给客户端。
否则将对应的key push到blocking_keys数据结构当中,对应的value是被阻塞的client。
当下次push命令发出时,服务器检查blocking_keys当中是否存在对应的key,如果存在,则将key添加到ready_keys链表当中,
同时将value插入链表当中并响应客户端。
9.应用场景:记录网站最近登陆用户



4.Set:无顺序,不能重复
1.插入的元素没有顺序存储。
2.当一次性插入的数据存在多个相同的值时,只能插入一个;
当要插入的值 在集合中已存在的话,则不会插入。
3.sadd 集合名 元素1 元素2:往集合中无序地插入新元素。
srem 集合名 元素1 元素2:从集合中移除一个或多个元素。
4.还有集合的运算命令等。
5.详细用法:
1.添加数据:sadd 集合名 元素1 元素2
2.删除数据:srem 集合名 元素1 元素2
3.查看数据:smembers nums(查看集合中所有的数据)
4.查看集合长度:scard nums
5.应用场景:共同关注、共同喜好


5.SortedSet(zset):有顺序,不能重复
1.因为zset是有顺序,不能重复的,所以适合做排行榜。
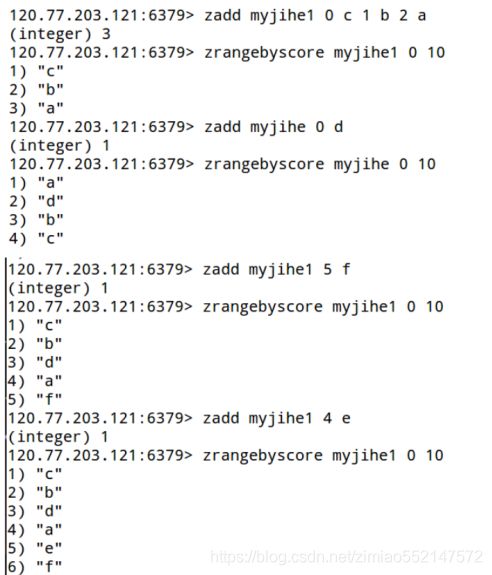
2.zadd 集合名 权重值 元素值1 权重值 元素值2:
以权重值作为排序标准,一个元素值对应一个权重值,权重值从小打到排序
![]()
3.zrem 集合名 元素值:从有序集合中移除一个元素![]()
4.zrange/zrevrange:
1.zrange 集合名 0 -1:从第一个元素开始遍历到最后一个元素
2.zrevrange 集合名 0 -1:从最后一个元素开始遍历到第一个元素
5.withscores:
1.zrange 集合名 0 -1 withscores:从第一个元素开始遍历到最后一个元素,同时显示权重值
2.zrevrange 集合名 0 -1 withscores:从最后一个元素开始遍历到第一个元素,同时显示权重值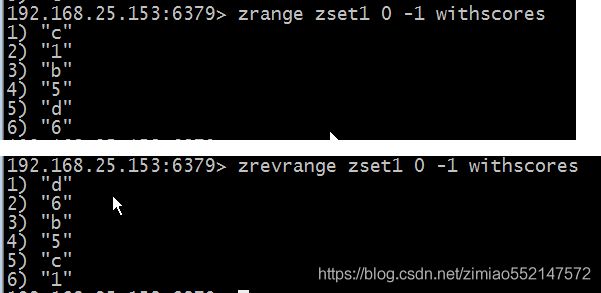
6.zset数据类型
1.添加数据:zadd 集合名 权重值 元素值1 权重值 元素值2(注意:权重值在前,元素值在后)
2.查询元素值的权重值:zscore 集合名 元素值
3.查看集合长度:zcard 集合名
4.删除元素值:zrem 集合名 元素值
5.查看集合所有内容,加withscores表示显示分数,不加withscores表示不显示分数:zrange 集合名 0 -1 [withscores]
6.应用场景:销售排行耪


key命令
1.Expire key名 秒数:设置key的过时时间/有效时间/生存时间
注意:此处的key指的是:(字符串)键值对的key、Hash中的对象名(并不是map中的key)、列表中的列表名、集合中的集合名
2.keys *:查看所有的key,然后可以给key设置过时时间
3.ttl key名:查询出的值分为3种结果
1.正数:获取出该key的过时的倒时时间
2.-1:表示该key不带有过时时间/有效时间/生存时间,即永不过期
3.-2:表示该key已被删除
4.persist key名:
移除key所带有过时时间/有效时间/生存时间,变为永不过期的key。
当key所带有过时时间/有效时间/生存时间移除成功时,返回 1。

Redis的持久化
1.Redis中存储的数据都是存储到内存中。
2.Redis的持久化方式:
1.第一种方式:rdb
1.Redis的默认支持的持久化方式:rdb,以快照方式保存到本地文件中。
2.rdb:定期自动把内存中的数据持久化到本地文件中。
3.rdb模式是默认开启的,也即默认定期持久化内存中的数据持久化到本地文件中。
4.把本地文件中持久化的数据 恢复到内存中的 Redis数据库中:
只要重新启动Redis服务器,就会自动加载用于持久化数据的本地文件,把本地文件中持久化的数据 恢复到内存中的 Redis数据库中。
2.第二种方式:aof
1.需要配置才能开启aof模式。
2.aof:把所有“对Redis数据库的增删改的”命令语句保存到文件中。
需要恢复Redis数据库中的数据时,只需要重新执行文件中记录的所有的增删改的命令语句即可。
持久化的频率是每秒一次 保存“对Redis数据库的增删改的”命令语句保存到文件中。
3.把本地文件中持久化的数据 恢复到内存中的 Redis数据库中:
只要重新启动Redis服务器,就会自动加载用于持久化数据的本地文件,把本地文件中持久化的数据 恢复到内存中的 Redis数据库中。
3.Redis进行持久化的配置文件redis.conf
1.Redis的安装目录:/usr/local/redis/bin目录下的redis.conf文件。
2.注意:
1.如果Redis的安装目录(/usr/local/redis/bin)下 不存在redis.conf的话,
请把/redis-3.0.0的源码安装包目录下的 redis.conf 拷贝到 /usr/local/redis/bin的安装目录下,
拷贝命令:cp /root/redis-3.0.0/redis.conf /usr/local/redis/bin
2.Redis的安装目录(/usr/local/redis/bin)下同时指定redis.conf 启动Redis服务器:./redis-server redis.conf
即Redis服务器加载并应用该redis.conf中的配置信息再进行启动。
3.redis.conf中默认配置的 rdb持久化方案:(每次修改完redis.conf请重新启动Redis服务器并再次指定加载该新修改后的redis.conf)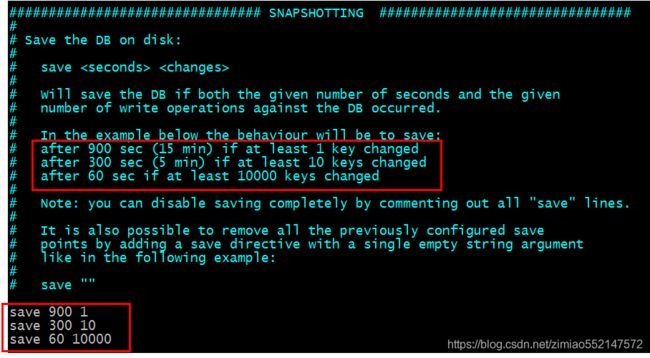

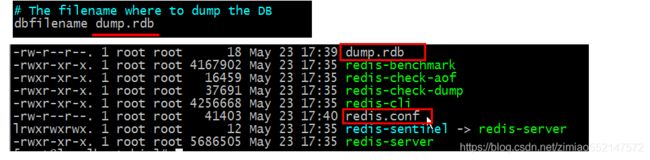
2.rdb持久化保存数据的本地文件:默认dump.rdb
dump.rdb持久化的本地文件保存在Redis的安装目录(/usr/local/redis/bin)下
可在redis.conf中修改“进行持久化的”本地文件名字。
3.把dump.rdb文件中保存的持久化数据 恢复到内存中的 Redis数据库中:
只要重新启动Redis服务器,就会自动加载用于持久化数据的dump.rdb文件,把本地文件中持久化的数据 恢复到内存中的 Redis数据库中。
4.当同时在redis.conf中配置开启了两种 rdb持久化模式 和 aof的持久化模式时,
并同时存在dump.rdb 和 appendonly.aof 两个持久化数据文件时,当重新启动Redis服务器时,
优先加载的是appendonly.aof持久化数据文件,即会把appendonly.aof文件中保存的持久化数据恢复到Redis数据库中。
4.redis.conf中可配置开启aof的持久化方式:(每次修改完redis.conf请重新启动Redis服务器并再次指定加载该新修改后的redis.conf)

1.aof持久化方式:(每次修改完redis.conf请重新启动Redis服务器并再次指定加载该新修改后的redis.conf)
1.redis.conf中默认配置是没有开启aof持久化:appendonly no
2.redis.conf中开启aof持久化:appendonly yes
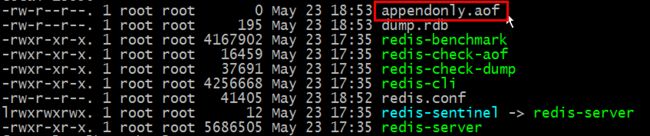
2.aof持久化保存数据的本地文件:默认appendonly.aof
appendonly.aof持久化的本地文件保存在Redis的安装目录(/usr/local/redis/bin)下
可在redis.conf中修改“进行持久化的”本地文件名字。
3.把appendonly.aof文件中保存的持久化数据 恢复到内存中的 Redis数据库中:
只要重新启动Redis服务器,就会自动加载用于持久化数据的appendonly.aof文件,把本地文件中持久化的数据 恢复到内存中的 Redis数据库中。
4.当同时在redis.conf中配置开启了两种 rdb持久化模式 和 aof的持久化模式时,
并同时存在dump.rdb 和 appendonly.aof 两个持久化数据文件时,当重新启动Redis服务器时,
优先加载的是appendonly.aof持久化数据文件,即会把appendonly.aof文件中保存的持久化数据恢复到Redis数据库中。
redis持久化方案
1.前言:redis所有的数据保存的是内存,正常关闭redis是不会丢失数据的,但是如果突然断电,redis还来不及数据保存,则会出现数据丢失的情况,
为了防止这种突发情况,redis有两种持久化方案:RDB持久化、AOF持久化。
2.RDB持久化:(redis默认的持久化方案)
在指定的时间间隔内将内存中的数据集快照写入磁盘,实际操作过程是fork一个子进程,先将数据集写入临时文件,写入成功后,再替换之前的文件,
用二进制压缩存储。 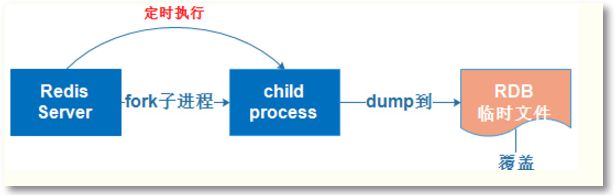
3.RDB持久化配置:
Redis会将数据集的快照dump到dump.rdb文件中。此外,我们也可以通过配置文件来修改Redis服务器dump快照的频率。
在打开redis.conf文件之后,我们搜索save,可以看到下面的配置信息:
save 900 1 #在900秒(15分钟)之后,如果至少有1个key发生变化,则dump内存快照。
save 300 10 #在300秒(5分钟)之后,如果至少有10个key发生变化,则dump内存快照。
save 60 10000 #在60秒(1分钟)之后,如果至少有10000个key发生变化,则dump内存快照。
4.RDB 优点:
1.可以最大化 Redis 的性能:父进程在保存 RDB 文件时唯一要做的就是 fork 出一个子进程,然后这个子进程就会处理接下来的所有保存工作,
父进程无须执行任何磁盘 I/O 操作
2.是一个非常紧凑的文件,这种文件非常适合用于进行备份:
比如说,你可以在最近的 24 小时内,每小时备份一次 RDB 文件,并且在每个月的每一天,也备份一个 RDB 文件。
这样的话,即使遇上问题,也可以随时将数据集还原到不同的版本。
5.RDB 缺点:
1.数据完整性不是特别的高,如果每5分钟备份一次,万一4分多的时候服务器crash,会导致丢失4分多钟的数据。
2.如果数据集特别大,并且cpu特别吃紧的情况下,会导致redis服务停顿,这种停顿可能长达1秒钟。
6.AOF持久化:
以日志的形式记录服务器所处理的每一个写、删除操作,查询操作不会记录,以文本的方式记录,可以打开文件看到详细的操作记录。

7.AOF持久化配置:
1.开启aof:
2.设置aof的同步方式
appendfsync always #每次有数据修改发生时都会写入AOF文件。
appendfsync everysec #每秒钟同步一次,该策略为AOF的缺省策略。
appendfsync no #从不同步。高效但是数据不会被持久化。
8.AOF优点:
非常耐久(much more durable):AOF 的默认策略为每秒钟 fsync 一次,在这种配置下,Redis 仍然可以保持良好的性能,并且就算发生故障停机,
也最多只会丢失一秒钟的数据
9.AOF缺点:
相对rdb恢复数据更慢,频繁磁盘io对服务器性能有影响。
10.RDB 和 AOF ,我应该用哪一个?
如果无法忍受数据的丢失,使用aof,如果可以忍受数据的丢失(比如缓存数据)使用rdb
Redis集群的搭建
1.分布式:
1.对于处理任务来说:
物理上是分开的,做的任务是不同的。每个服务器负责执行程序中的不同部分的任务,只要其中一个服务器宕机,便会影响整个程序的完整性。
2.对于存储数据来说:
每个服务器存储的数据都是不一样的
2.集群:
1.对于处理任务来说:
物理上是分开的,做的任务是相同的。每个服务器负责执行程序中的同一部分的任务,即使其中一个服务器宕机,也不影响整个程序的完整性。
2.对于存储数据来说:
1.每个服务器存储的数据都是一样的,分为两种,主服务器和从服务器。
主服务器负责提供数据库数据的增删查改,从服务器负责自动备份主服务器中的数据。主服务器和从服务器存储的都是相同的数据。
当主服务器宕机了之后,从服务器便替换作为主服务器来使用。
2.对于数据库进行集群来说,还可以配置主从读取分离。主服务器负责提供数据库数据的增删改,从服务器负责提供数据库数据的查询。
主服务器和从服务器还涉及到同步相关配置。

Redis集群:redis-cluster架构图


1.所有的redis节点是互相联通自动传输数据的,所以客户端只要连接到任意一个redis节点上即能获取redis集群下的数据库中的任意数据。
2.搭建主、从的Redis集群中:
1.所有的每个主的Redis节点负责互相自动传输数据,而每个Redis节点存储的都是不同的数据。
而每个主的Redis节点后面都可以连接一个或多个从的Redis节点,每个从的Redis节点只负责备份对应的主的Redis节点中的数据。
2.当某一个主的Redis节点失效之后,该主的Redis节点对应的从的Redis节点便充当新的主Redis节点的作用。
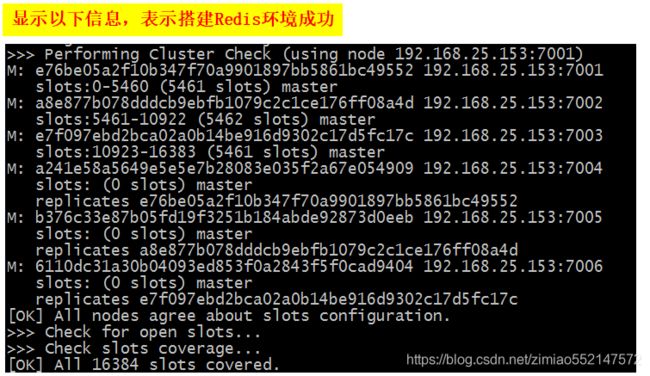
3.Redis集群中一共内置了16384个哈希槽slot,假如当前Redis集群中有3个Redis节点,
那么首先便会把 16384个哈希槽slot平均地自动分配并映射到对应的其中一个Redis节点上;当客户端要向Redis集群中存储键值对数据时,
首先会根据crc16算法计算出该键值对中的key对应的是哪个哈希槽slot,然后根据“该键值对中的key对应的”哈希槽slot所映射的是哪个Redis节点,
最终把该键值对存储到“哈希槽slot所映射到的”那个Redis节点上。
1.所有的redis节点彼此互联(PING-PONG机制),内部使用二进制协议优化传输速度和带宽 。
2.某个redis节点的失效是通过集群中超过半数的节点共同检测,认为该redis节点失效了时,就会使用该失效的redis节点的备份(从的redis服务器节点),
此时的从的redis服务器节点相当于替换作为新的主的redis节点,而从的redis服务器节点平时负责备份主的redis服务器节点中的数据。
3.client客户端与redis节点直连,不需要中间proxy层,客户端不需要连接redis集群中的所有节点,客户端只需要连接redis集群中的任何一个可用节点即可。
4.redis-cluster把所有的物理节点映射到[0-16383]slot(哈希槽)上,redis-cluster负责维护 redis节点node <---> 哈希槽slot <---> 数据值value
5.Redis集群中内置了 16384 个哈希槽slot,当需要在 Redis集群中存储一个 key-value键值对数据时,
redis 先对 key 使用 crc16 算法算出一个结果值,然后把该结果值对 16384 进行求余数,这样每个 key 都会对应一个编号在 0-16383 之间的哈希槽,
redis 会根据节点数量 大致均等地 将哈希槽映射到不同的redis节点上,然后把该键值对数据存储到“对应的哈希槽所映射到的”redis节点上。
Redis集群之搭建步骤
1.第一步:
首先需要确定Redis集群多少个Redis节点。
一般推荐至少集群3个或3个以上的Redis节点。
原因:集群中只有2个Redis节点的话,因为集群之间当有某一个Redis节点失效了的话,
是需要集群中超过半数的Redis节点进行投票判断该某个Redis节点是否失效了,所以如果只有集群中只有2个Redis节点的话,
其中一个Redis节点失效了之后,只剩下一个有效节点的话,是无法达到“超过半数的Redis节点进行投票判断”的条件的,
所以要求在搭建Redis集群中应至少集群3个或3个以上的Redis节点才符合要求。
2.第二步:
确定Redis集群中每个“主”Redis节点都应该至少拥有一个“从”Redis节点以上,那么不仅能保证“从”Redis节点随时备份“主”Redis节点中的数据,
并且能保证当“主”Redis节点失效了之后,会有对应的一个“从”Redis节点加入到Redis集群中,替代失效的“主”Redis节点,
否则整个Redis集群就会缺少部分数据库数据,而无法达到真正集群的效果和要求。
3.第三步:
因为至少需要配置 3个“主”Redis节点,而每个“主”Redis节点还需要配置 1个“从”Redis节点,所以一共需要配置 6个Redis节点,
而每个Redis节点都部署在不同的服务器上的话,则需要6台服务器,也即6台虚拟机。
模拟搭建一个伪的Redis集群
此处模拟搭建一个伪的Redis集群:
在一个服务器中的一个虚拟机上,配置开启6个不同的Redis节点服务器,每个Redis节点服务器单独使用一个端口,
一共配置7001~7006的6个端口。
1.第一步:
创建一个redis-cluster的文件夹,该redis-cluster文件夹下创建 6个分别叫做redis01~redis06的文件夹。
然后redis01~redis06的每个文件夹中,都拷贝一份“/usr/local/redis/bin”(Redis安装目录)下所有的文件。
还需要保证redis01~redis06的每个文件夹中都没有 dump.rdb 和 appendonly.aof 两个持久化数据文件,保证数据库是干净的空的。
拷贝命令:cp -r /usr/local/redis/bin redis-cluster/redis01
redis01~redis06的每个文件夹下的文件详情如下:
2.第二步:
修改redis01~redis06的每个文件夹中的redis.conf配置文件:
1.修改端口号:6379的端口号 分别修改为7001~7006
2.开启支持集群模式:cluster-enabled yes
默认是被注释掉的,取消注释,即集群模式
3.第三步:
1.批处理连续启动6个Redis节点服务器。
2.创建一个start-all.sh批处理文件,内容如下:
shell脚本:
1.第一步:shell脚本中的第一行为:#!/bin/bash
2.第二步:shell脚本如果是在window编辑创建的,那么shell脚本的格式实际为dos,执行“vi shell脚本名”,
然后执行“:set ff”查看到脚本的格式实际为dos,然后执行“:set ff=unix”,
把么shell脚本的格式修改为了unix。
3.第三步:修改脚本的执行权限,执行“chmod 777 shell脚本名”
4.第四步:执行脚本“./shell脚本名”
3.修改start-all.sh文件为有可执行权限的文件:chmod u+x start-all.sh
4.执行start-all.sh批处理文件:./start-all.sh 命令,开启了6个7001~7006端口的Redis节点服务器
4.第四步:使用ruby脚本搭建Redis集群,首先需要安装ruby的运行环境
1.第一步:安装 ruby环境
1.执行 yum install ruby
2.执行 yum install rubygems
2.第二步:ruby脚本运行redis-3.0.0.gem包
1.执行 gem install redis-3.0.0.gem 
3.第三步:进入到 redis-3.0.0的源码包目录下的src目录下
4.第四步:把 /redis-3.0.0/src目录下的 redis-trib.rb脚本文件 拷贝到 redis-cluster文件夹下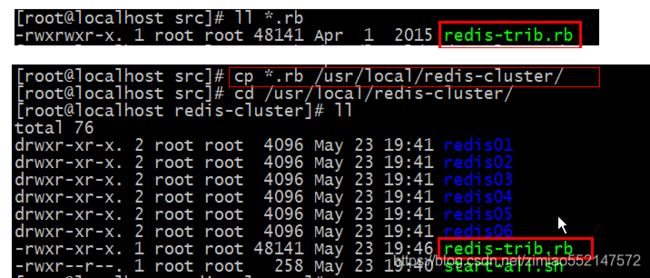
5.第五步:使用ruby执行redis-trib.rb脚本文件 进行搭建Redis集群
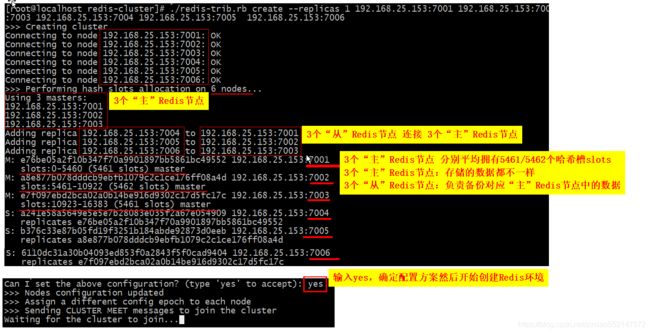
1.执行的命令:./redis-trib.rb create --replicas 1 192.168.25.153:7001 192.168.25.153:7002 192.168.25.153:7003 192.168.25.153:7004 192.168.25.153:7005 192.168.25.153:7006
2.“create --replicas 1”命令中的“1”:表示每个“主”Redis节点后面都有一个“从”Redis节点
3.“./redis-trib.rb create --replicas 从节点数”命令后面还要拼接上所有每个的Redis节点服务器的“IP:端口”,
每个“IP:端口”之间使用空格隔开。
Redis集群之使用:Redis客户端连接Redis集群的服务器,进行存储数据
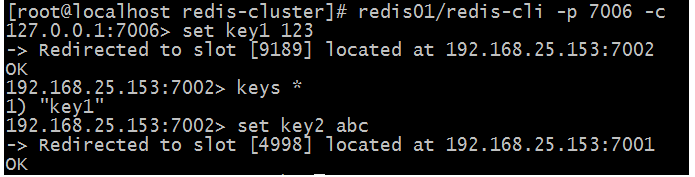
1.使用redis01~redis06任意一个文件夹下的redis-cli客户端 连接 Redis集群下的任意一个Redis节点服务器 都可以进行 正常的存储/获取数据。
2.redis-cli -p 端口 -c:
1.rendis-cli -p 7001~7006中的任意一个端口。
2.-c:表示进行集群链接。
3.redis-cli -p “主”Redis节点服务器的端口 -c:
每个“主”Redis节点服务器已分配好哈希槽slot,自动把键值对存储到“哈希槽slot所映射到的”那个“主”Redis节点服务器中。
4.redis-cli -p “从”Redis节点服务器的端口 -c:
每个“从”Redis节点服务器 都不拥有任何的哈希槽slot,所以往“从”Redis节点服务器中存储数据时,
会自动转为把键值对存储到“哈希槽slot所映射到的”那个“主”Redis节点服务器中。
Java中使用Jedis连接Redis集群服务器操作数据
1.父工程中的pom.xml配置jedis:
2.7.2
redis.clients
jedis
${jedis.version}
2.Service子工程中的pom.xml配置jedis:
redis.clients
jedis
3.Jedis下拥有“对应每种Redis数据类型的”各种获取/存储等方法:
package com.taotao.jedis;
import java.util.HashSet;
import java.util.Set;
import org.junit.Test;
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
import com.taotao.content.jedis.JedisClient;
import redis.clients.jedis.HostAndPort;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisCluster;
import redis.clients.jedis.JedisPool;
public class JedisTest
{
@Test
public void testJedisSingle() throws Exception
{
//使用Jedis(redis的IP 或“hosts文件中redis的IP所映射的”域名, redis端口6379)
Jedis jedis = new Jedis("192.168.25.153", 6379);
jedis.set("mytest", "1000");
String result = jedis.get("mytest");
System.out.println(result);
jedis.close();
}
@Test
public void testJedisPool() throws Exception
{
//创建一个连接池对象
JedisPool jedisPool = new JedisPool("192.168.25.153", 6379);
//从连接池获得连接
Jedis jedis = jedisPool.getResource();
String result = jedis.get("mytest");
System.out.println(result);
//每次jedis使用完毕后需要关闭,连接池回收资源。
jedis.close();
//系统结束前关闭连接池
jedisPool.close();
}
@Test
public void testJedisCluster() throws Exception
{
//连接集群使用JedisCluster对象
Set nodes = new HashSet<>();
nodes.add(new HostAndPort("192.168.25.153", 7001));
nodes.add(new HostAndPort("192.168.25.153", 7002));
nodes.add(new HostAndPort("192.168.25.153", 7003));
nodes.add(new HostAndPort("192.168.25.153", 7004));
nodes.add(new HostAndPort("192.168.25.153", 7005));
nodes.add(new HostAndPort("192.168.25.153", 7006));
//系统中可以是单例
JedisCluster jedisCluster = new JedisCluster(nodes);
jedisCluster.set("jediscluster", "123456");
String result = jedisCluster.get("jediscluster");
System.out.println(result);
//系统结束前关闭JedisCluster
jedisCluster.close();
}
@Test
public void testJedisClientPool() throws Exception
{
ApplicationContext applicationContext = new ClassPathXmlApplicationContext("classpath:spring/applicationContext-*.xml");
JedisClient jedisClient = applicationContext.getBean(JedisClient.class);
jedisClient.set("client", "hello");
String result = jedisClient.get("client");
System.out.println(result);
}
}
