认识Redis高性能背后的数据结构(二)
文章目录
- 前言
- 1.集合set
- 1.1 set 的底层实现
- 1.2 整数集合 Intset
- 1.2 为什么要设计整数集合intset
- 2. 有序集合zset
- 2.1 zset的底层实现
- 2.2 跳表 skiplist
- 2.2.1 什么是跳表
- 2.2.2 跳表与哈希表、二叉平衡树的比较
- 2.2.3 Redis中skiplist的实现
- 2.2.4 Redis中对于sorted set的底层实现
- 3. redis数据存储分析
- 3.1 Redis存储结构
- 3.2 redisObject分析
- 4. Redis数据查找源码分析
- 最后
前言
前面一篇文章我们已经了解了String、List、Hash的底层数据结构实现,那接下来我们就一起看一下Set 和ZSet的底层数据结构的实现。废话不多说,直接开搞。
1.集合set
1.1 set 的底层实现
还是通过Redis的客户端来看一下set的底层数据结构:
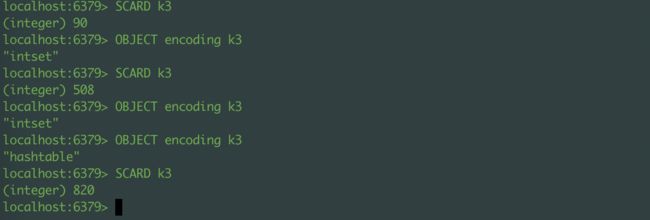
上图是我直接用Redis的客户端直接添加数据,这里我添加的value类型全都是数字,当我们key对应的集合数量较小的时候,底层数据结构是intset,当key所对应的集合数量超过了某一个值,底层数据结构变成了hashtable,我们之前也说了hashtable是字典的底层实现,所以我们用字典来代替hashtable。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6ZvE78fv-1596962075459)(https://s1.ax1x.com/2020/08/02/athkGR.png)]
上面这个图,我给key对应的value值只有10个,底层数据结构仍然是intset,但是当我再增加一个字符串,底层的数据结构也从intset转成了dict。
除此之外呢,我们可以通过数据结构的名称能够才想到,intset只能存储int类型的数字,intset能够表达的最大的整数范围为-2^64 ~ 2^64-1,如果添加的数字大小超出了这个范围,这也会导致intset转成dict。所以我们可以总结如下:
- 当集合中的key 对应的 value为一个数字(key对应的value只能是数字),且当数字范围在-264~264-1中间,且添加的集合元素个数没有超过
set-max-intset-entries配置的值的时,集合键Set底层数据结构为intset。 - 其他的情况底层数据结构为字典dict。
1.2 整数集合 Intset
我们知道了Redis的集合键Set的底层实现有两种数据结构:字典dict、整数集合intset。前面一篇的文章我们已经说过了字典dict的实现,这里我们就重点来说一下intset。
intset的数据结构定义如下(代码来自intset.h):
typedef struct intset {
uint32_t encoding;
uint32_t length;
int8_t contents[];
} intset;
-
encoding:数据编码格式,表示intset中每个元素用几个字节来存储。- INTSET_ENC_INT16表示每个元素用2个字节存储。
- INTSET_ENC_INT32表示每个元素用4个字节存储
- INTSET_ENC_INT64表示每个元素用8个字节存储
所以intset中存储的整数最多只能占用64bit。
-
length: 表示intset中的元素个数。 -
contents:这是一个动态数组,是真正存储数据的。这个数组的总长度等于encoding * length。这里我们需要注意的是,intset的编码格式会随着新增加的元素调整,根据元素的大小是否对数据编码进行升级。
intset的内存是连续的,所有的数据增删改查操作都是在内存地址偏移的基础上进行的,并且整数的保存也是有序的。
1.2 为什么要设计整数集合intset
相比于字典dict来说,使用intset来存储,主要的原因是节省内存。特别是当存储key所对应的元素个数较少的时候,相对于dict来说,dict所需要的内存开销要大得多,因为字典包含两个哈希表、链表指针以及大量的其它元数据。所以,当存储大量的小集合而且集合元素都是数字的时候,用intset能节省下一笔可观的内存空间。
可能有朋友会提问了,就算dict使用的内存开销稍微大一些,但是dict的查询的时间复杂度是O(1),相比于intset来说平均查询时间要快的,对于追求高性能的Redis来说当然还是选用dict稍微好一些。这里我想要提醒大家一点,大家不要忘记了intset是一个排序好的集合,排序好的集合我们可以利用二分法来进行数据的查找,其时间复杂度为O(logn),由于使用intset的时集合元素个数比较少,所以这个影响不大。
2. 有序集合zset
2.1 zset的底层实现
有序集合在集合的基础上扩展出来了有序集合,zset实现的底层数据结构有两种:压缩列表ziplist和跳跃表zskiplist。
当zset使用ziplist做底层实现时需要满足以下两个条件:
- 有序集合保存的元素数量小于128个
- 有序集合保存的所有元素的长度小于64字节
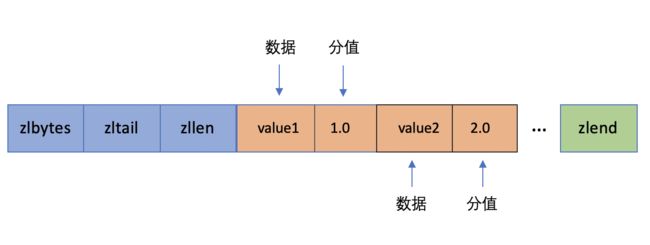
我们之前对ziplist的数据结构已经分析过了,这里我们就不重复说了,如果忘记了话,可以看上一篇文章。如果zset底层的数据结构使用的是ziplist,每个元素使用两个紧挨在一起的压缩列表节点来保存,第一个节点保存元素的成员,第二个节点保存元素的分值。并且按分值从小到大的顺序进行排列。如下图:
2.2 跳表 skiplist
2.2.1 什么是跳表
跳表全称为跳跃列表,它允许快速查询,插入和删除一个有序连续元素的数据链表。跳跃列表的平均查找和插入时间复杂度都是O(logn)。
跳表是在单链表的基础上构建的,我们知道单链表的数据结构优势在于插入和删除的时间复杂度都是O(1),但是单链表的查询效率是非常低的,时间复杂度为O(n),即使我们数据是有序的,也需要从头遍历才能拿到我们想要获取的链表节点。那有什么方法可以去改进单链表的查询效率吗?我们知道数组的查询的时间复杂度是O(1),因为数组是可以通过下标来直接访问数据的,我们也可以把下标理解为索引。那是不是也可以通过给单链表添加索引的方式,来提高数据的查询效率。
那有什么办法可以提高链表的查询效率呢?我们是不是可以借鉴数据库的那种方式,通过添加索引或者目录来提高链表的查询效率。我们可以在原始链表的基础上,每相隔两个结点提取一个结点建立索引,我们把抽取出来的结点叫做索引层或者索引
假如我们每相邻两个节点增加一个指针,让指针指向下下个节点,如图:

当我们这样建立了指针以后,当我们再访问红色节点的时候,我们中间只需要经过三个节点就可以直接访问,相比于之前我们节约了一半的时间。
利用同样的方式,我们可以在上层新产生的链表上,继续为每相邻的两个节点增加一个指针,从而产生第三层链

如果我们同样查找红色的节点,我们中间只需要访问两个节点就可以了。可以想象,当链表足够长的时候,这种多层链表的查找方式能让我们跳过很多节点,大大加快查找的速度。按照上面生成链表的方式,上面每一层链表的节点个数,是下面一层的节点个数的一半,这样查找过程就非常类似于一个二分查找,使得查找的时间复杂度可以降低到O(log n)。但是这样的方式会使得插入数据的时候会有一个很大的问题,每当新插入或删除节点都会打乱链表节点的个数比,如果要维持这种对应关系,就必须把新插入的节点后面的所有节点(也包括新插入的节点)重新进行调整,这样让时间复杂度又变成了O(n)。
跳表skiplist为了避免这一问题,它不要求上下相邻两层链表之间的节点个数有严格的对应关系。它采用随机技术决定链表中哪些节点应增加向前指针以及在该节点中应增加多少个指针,也是我们理解的层数。跳表结构的头节点需有足够的指针域(最大层数),以满足可能构造最大级数的需要,而尾节点不需要指针域。如下图:

因为个节点的层数是随机出来的,无论是增加或是删除一个节点,都不会影响其他节点的层数。所以,在插入操作只需要修改插入节点的前后指针就可以了;删除节点也是一样的,只需要调整删除节点的前后指针,这就降低了插入和删除时的操作复杂度。
跳表之所以叫做跳表,是因为可以通过指针跳过一些节点,而且是层数越大跳过的节点也就越多。这就使得我们在查找数据的时候能够先在高层的链表中进行查找,然后逐层降低,最终降到第1层链表来精确地确定数据位置。
2.2.2 跳表与哈希表、二叉平衡树的比较
- 哈希表不是有序的,而且哈希表只适合用来做单个数据的查找,不适合使用范围查找。
- 虽然二叉平衡树(像AVL书,红黑树等)的元素是有序排列的,但是范围查询平衡树的操作就比跳表要复杂很多。
- 平衡树的插入和删除元素,可能会引发树的重新调整,逻辑相对于跳表来说是很复杂的。而skiplist的插入和删除只需要修改相邻节点的指针,操作简单又快速。
- 从算法实现难度上来比较,skiplist比平衡树要简单得多。
2.2.3 Redis中skiplist的实现
skiplist只是zset对外暴露的一种数据结构而已,zset底层不仅仅使用了skiplist,还使用到了dict。
Redis对于skiplist的定义如下,源码出自于:redis/src/server.h
#define ZSKIPLIST_MAXLEVEL 32
#define ZSKIPLIST_P 0.25
typedef struct zskiplistNode {
sds ele;
double score;
struct zskiplistNode *backward;
struct zskiplistLevel {
struct zskiplistNode *forward;
unsigned long span;
} level[];
} zskiplistNode;
typedef struct zskiplist {
struct zskiplistNode *header, *tail;
unsigned long length;
int level;
} zskiplist;
分析一下上面的源码:
- zskiplist定义了跳表的数据结构,它包含了:
- 头指针head和尾指针tail
- length代表了链表的长度,即链表的节点数。
- level表示skiplist的总层数,即所有节点层数的最大值
- zskiplistNode定义了每个链表节点的内容。
sds ele:是真正存放数据的数据域,使用的是前面我们说过的动态字符串sds来存放数据。- double score` :分值,排序就是靠这个分值来进行排序的。
zskiplistNode *backward: 指向当前节点的前驱节点的指针,这里我们可以理解为是双向链表。zskiplistLevel: 每一个节点的层级,最大值为32,由 ZSKIPLIST_MAXLEVEL 定义zskiplistNode *forward: 某一层指向下一个节点的指针。zskiplistNode *forward:跨度,某一层距离下一个节点的跨度
下图展示了Redis中skiplist的可能结构:

2.2.4 Redis中对于sorted set的底层实现
前面我们只是说Redis对于skiplist的实现,但是Redis对于sorted set的底层实现却不是仅仅使用了skiplist一种数据结构,而是使用dict+skiplist实现的,Redis对于zset的定义如下:
typedef struct zset {
dict *dict;
zskiplist *zsl;
} zset;
Redis为什么要这样设计呢,要多出来一个dict。通过上面我们了解,可能已经知道了skiplsit的优势在哪里,skiplist做范围查询的效率是比较高的,但是对于单值的查找效率明显还是不如dict的,所以Redis使用dict数据结构来实现快速的单指查找。就像我们查找一个key中成员的分数 zscore key members,这里如果使用跳表去查,需要挨个不遍历链表中的每个成员,直到匹配到你所需要找到的成员,这样查询的效率是非常低的。
所以Redis这里额外使用了一个字典dict来存储成员和分值。dict中的key就是成员,value就是分值。skiplist中存储的就是按照分值排序好的每个链表节点,链表节点里存储的就是分值和成员,存储结构可能是我们上面图所画出来的结构。不过这里要说一下,sorted set数据结构中只有zscore命令才使用到了dict,其余的命令均是使用zskiplist数据结构来提供操作的。
这才是zset数据结构的真面目:

3. redis数据存储分析
3.1 Redis存储结构
Redis是一个典型的高性能Key-Value数据库,而且支持丰富的数据类型,其中键只能是字符串类型,值支持的数据类型有:字符串String、列表List、散列表Hash、集合Set、有序集合Sort set,那Redis到底是如何做到支持多种数据结构的呢?从Redis内部实现的角度来看,其实Redis就相当于一个对象系统,Redis把每种数据类型都封装成了一个个redisObject对象,每一个对象至少由我们之前说到的至少一种数据结构实现。我们就通过Redis的源码,一起看一下Redis底层是如何进行数据的存储的,我们通过下图对Redis的整体概况有一个简单的了解。
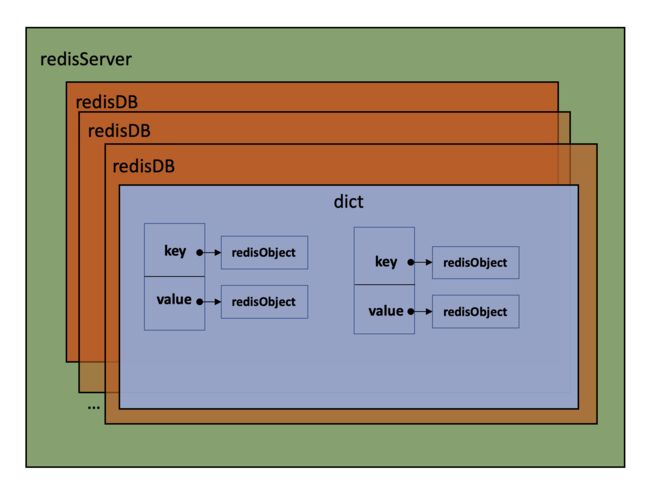
一个redisServer有多个redisDb,redisDb相当于Mysql中的库的概念,Redis默认一个server中有16个redisDb,可以通过redis配置文件修改这个参数,其中每个redisDb都是一个字典dict,每个dict里面存储了key-value这样的键值对数据,Redis中的每个key和value都是由redisObject构成的,每个redisObject对应了Redis提供的五种基本数据类型,具体细节我们下面会详细说到。
到这里相信多少对Redis的数据存储结构有了一定的了解,接下来我们通过源码具体看一下Redis的实现细节,而且也是对我们之前说过的内容的一种验证,这可不是我胡乱说的,这是redis源码里写的。
首先我们从redisDb源码看一下,以下源码来自redis/src/server.h。这里就不去说redisServer的代码了,如果感兴趣的话大家点这里自取:redisServer源码
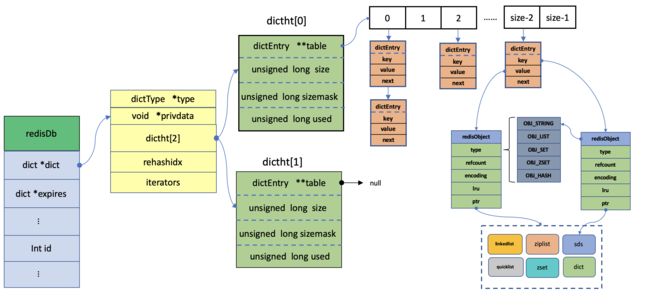
typedef struct redisDb {
// 键值对字典,保存数据库中所有的键值对
dict *dict; /* The keyspace for this DB */
// 过期字典,保存着设置过期的键和键的过期时间
dict *expires; /* Timeout of keys with a timeout set */
// 保存着 所有造成客户端阻塞的键
dict *blocking_keys; /* Keys with clients waiting for data (BLPOP)*/
// 保存着 处于阻塞状态的键,value为NULL
dict *ready_keys; /* Blocked keys that received a PUSH */
// 事物模块,用于保存被WATCH命令所监控的键
dict *watched_keys; /* WATCHED keys for MULTI/EXEC CAS */
// 数据库ID
int id; /* Database ID */
// 键的平均过期时间
long long avg_ttl; /* Average TTL, just for stats */
unsigned long expires_cursor; /* Cursor of the active expire cycle. */
list *defrag_later; /* List of key names to attempt to defrag one by one, gradually. */
} redisDb;
我们发现redisDb中有五个dict,其中和使用者密切相关的还是dict *dict和 dict *expires,第一个字典就是用来存储所有的键值对数据,第二个在字典表存储了我们设置了过期时间的键,key就是我们的键value是一个时间戳。
3.2 redisObject分析
上面我们说过字典中存储的键和值都是redisObject,通过源码看一下redisObject的结构定义:源码出自于redis/src/server.h 606行
typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:LRU_BITS; /* lru time (relative to server.lruclock) */
//引用计数
int refcount;
//指向底层数据实现的指针
void *ptr;
} robj;
redisObject各个参数的含义:
unsigned type:4: 对象的数据类型,占4bits,共5种类型,分别是:- OBJ_STRING:字符串对象
- OBJ_LIST:列表对象
- OBJ_SET:集合对象
- OBJ_ZSET:有序集合对象
- OBJ_HASH:哈希对象
unsigned encoding:4: 对象的编码,占4bits,共10种类型- OBJ_ENCODING_RAW:原始表示方式,字符串对象是简单动态字符串
- OBJ_ENCODING_INT: long类型的整数
- OBJ_ENCODING_HT:字典
- OBJ_ENCODING_ZIPMAP:已废弃,不使用
- OBJ_ENCODING_LINKEDLIST:双端链表
- OBJ_ENCODING_ZIPLIST:压缩列表
- OBJ_ENCODING_INTSET:整数集合
- OBJ_ENCODING_SKIPLIST:跳跃表和字典,对应的是我们之前分析过的zset。
- OBJ_ENCODING_EMBSTR:embstr编码的简单动态字符串
- OBJ_ENCODING_QUICKLIST:快速列表
unsigned lru:LRU_BITS用于LRU算法计算相对server.lruclock的LRU时间int refcount: 引用计数。void *ptr: 指向底层数据实现的指针。
写到这里我突然想到,redis中有两个命令,一个是type命令,返回的是值的数据类型,我想type返回的应该redisObject中unsigned type 字段。还有另外一个object encoding 命令,返回的是数据类型的编码,我想这里应该返回的是redisObject对象中的unsigned encoding字段。翻看源码果真和自己猜想一样。
char* getObjectTypeName(robj *o) {
char* type;
if (o == NULL) {
type = "none";
} else {
switch(o->type) {
case OBJ_STRING: type = "string"; break;
case OBJ_LIST: type = "list"; break;
case OBJ_SET: type = "set"; break;
case OBJ_ZSET: type = "zset"; break;
case OBJ_HASH: type = "hash"; break;
case OBJ_STREAM: type = "stream"; break;
case OBJ_MODULE: {
moduleValue *mv = o->ptr;
type = mv->type->name;
}; break;
default: type = "unknown"; break;
}
}
return type;
}
看到这里是不是已经对Redis的数据库有大致的了解,那我们通过下面的图再一起的巩固一下:
4. Redis数据查找源码分析
到这里我们已经把Redis中所有的数据结构都过了一遍,也对redis的整个数据存储有了一定的了解。最后的话我想通过源码,来分析一下,Redis是如何来进行数据的查找的,让我们对Redis的整个数据查找过程有一定的了解,这里我就以sorted set中的zscore命令为例。
首先Redis通过请求获取到客户端发来的命令 ,如果函数被调用时,服务器已经读入了一整套命令参数,保存在参数列表中。此时就进入到了processCommand方法。源码来源server.c中的processCommand()方法
int processCommand(client *c) {
if (!strcasecmp(c->argv[0]->ptr,"quit")) {
addReply(c,shared.ok);
c->flags |= CLIENT_CLOSE_AFTER_REPLY;
return C_ERR;
}
// 这里封装了客户端发送的命令。c->argv[0]->ptr 这里返回的是我们输入的命令第一个参数。
//比如说我们输入的是 zscore fruits apple. c->argv[0]->ptr 是fruits。
c->cmd = c->lastcmd = lookupCommand(c->argv[0]->ptr);
/** 根据name查找返回对应的命令。源码位置server.c 第3103行
struct redisCommand *lookupCommand(sds name) {
return dictFetchValue(server.commands, name);
}
*/
/**redisCommand里面记录了命令对应的函数。源码位置server.c 第150行
struct redisCommand redisCommandTable[] = {
{"zscore",zscoreCommand,3,"rF",0,NULL,1,1,1,0,0}
}
*/
...
/** 此处省略了一些代码,需要的自行翻看源码*/
....
//做了很多的校验,判断命令
// 执行普通的命令
call(c,CMD_CALL_FULL);
}
c->cmd->proc©这里是执行命令,这里最终调用的方法是zscoreCommand()。源码来自t_zset.c 第3074行
void zscoreCommand(client *c) {
robj *key = c->argv[1];//这里存储的是c->argv[1] 返回的是我们输入的命令中第二个参数fruits.
robj *zobj;
double score;
// 以读操作取出有序集合对象
if ((zobj = lookupKeyReadOrReply(c,key,shared.nullbulk)) == NULL ||
checkType(c,zobj,OBJ_ZSET)) return;
/** 以读操作取出key的值对象,如果key不存在,则发送reply信息,并返回NULL
这段代码来自于db.c
robj *lookupKeyReadOrReply(client *c, robj *key, robj *reply) {
robj *o = lookupKeyRead(c->db, key);//取出key对应的value
if (!o) addReply(c,reply);
return o;
}
*/
// zsetScore方法通过我们获取到的ob对象以及成员,返回对应的分数。
if (zsetScore(zobj,c->argv[2],&score) == C_ERR) {
//如果失败,返回null
addReply(c,shared.nullbulk);
} else {
addReplyDouble(c,score); //发送分值
}
}
到地里我们把Redis整个查找过程大致过了一遍,如果想深入了解的同学,自己去点开源码看看,基本上流程是这样的。
最后
从上次写Redis数据结构分析上半部分的文章到现在已经快一个月了,本来我也想快点写完,但是中间工作原因和个人原因拖到了现在,其实写这篇文章特别的费劲,本身Redis底层就是C语言写的,而我C语言又不是很好,看起来多少有些费劲,再加上画图,有时候一张图需要还一个小时。不过磕磕绊绊的总算给搞完了,希望来的不算太晚,希望我的这篇文章可以给你带来一点点收获,让你有欲望去深入了解Redis的底层数据结构和实现。
每次感觉自己写东西都很用心,但是每次点赞的人都不是很多,能不能也让我的文章上一次推荐呢┭┮﹏┭┮。如果有帮助到你,希望素质三连一下,谢谢各位老铁!