1.路由
tp5 的路由配置在 application 文件夹下的 route.php 文件中。
有两种写法,详见官方文档。
默认的写法是配置写法,有点繁琐,如下:
[
'name' => '\w+',
],
'[hello]' => [
':id' => ['index/hello', ['method' => 'get'], ['id' => '\d+']],
':name' => ['index/hello', ['method' => 'post']],
],
];
这里我们使用一下动态注册。
非常简单。
但是有一个需要注意的问题,一旦路由生效,PATH_INFO 的访问模式就会失效,即访问z.cn/sample/test/hello是无效的了。
现在我们来详细的看一下 Route::rule 的完整写法:
Route::rule('路由表达式','路由地址','请求类型','路由参数(数组)','变量规则(数组)')
我们来看一下请求类型,有以下几种:
GET, POST, DELETE, PUT, * ( *表示为任意的请求类型)
当 Route::rule 缺省该参数的时候,默认是 * 类型。(可以通过 PostMan 进行验证)
这样当然不好,因为每一种 http 请求都是有特定意义的,使用 * 号会导致语义不明确。
所以我们可以修改一下:
Route::rule("hello","sample/Test/hello","GET");
对于某些时候,我们可能希望既支持 GET 也支持 POST。写法:
Route::rule("hello","sample/Test/hello","GET|POST");
路由参数可以查看官方文档。
变量规则今后有好的示例的时候再来讲解。//TODO
补充:由于我们平时开发常用的就是前三个参数,即路由表达式,路由地址和请求类型,所以 tp5 给我们提供了简写的方式:
Route::get("hello","sample/test/hello");
Route::post();
Route::any(); // any 即对应http请求中的 *
2.获取 http 参数
先补充一下基础知识:
路由里get 传参的两种方式:
1.在 url 路径中传参:
/:自定义名字
Route::get("hello/:id","sample/Test/hello");
2.在 url 路径中加问号
?参数名=参数值
我们在路由中传递参数的目的是在控制器的操作方法里成功获取这些参数:
在操作方法中获取 http 参数的方式有三种。
第一种:
通过操作方法的参数获取:
public function hello($id,$name)
{
return "hello $id, $name";
}
然后我们在浏览器或 Postman 中输入 url:
z.cn/hello/123?name=frank
就可看到输出:

下面我们看一下 post 请求参数的获取:
我们先改一下路由:
Route::post("hello/:id","sample/test/hello");
并且在操作方法中新加一个参数:$age
public function hello($id,$name,$age)
{
return "hello $id, $name, $age";
}
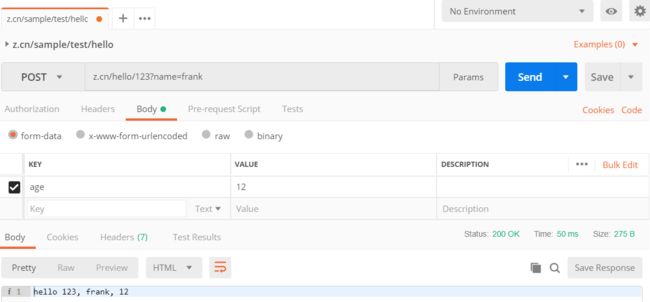
然后打开 postman:
选择 POST 方式。
在 Body 中通过键值对进行传值:(默认 form-data 即可)
KEY 输入 age,VALUE 输入相应值。
就能看到相应输出的结果。
第二种:
通过 Request 类。
Request::instanse() 拿到 Request 的实例。
->param 调用实例的 param() 方法。
use think\Request;
class Test
{
public function hello()
{
$id = Request::instance()->param("id");
$name = Request::instance()->param("name");
$age = Request::instance()->param("age");
return "hello $id, $name, $age";
}
}
param方法不管请求是从 get 还是 post 还是 delete 等里来的,它是不区分这些 http 类型的。
如果我们不想一次一次的单独获取,想一次性获取所有:
可以在 ->param() 里面不写参数。
use think\Request;
class Test
{
public function hello()
{
$all = Request::instance()->param();
var_dump($all);
}
}
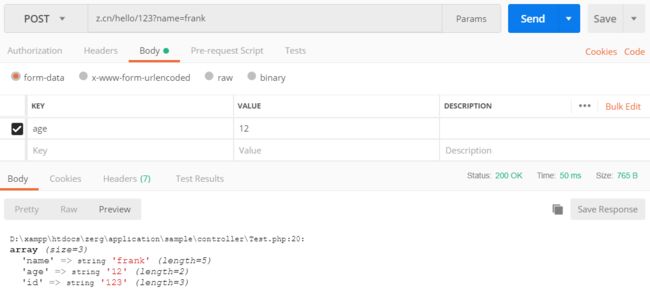
下面我们看一下获取的内容的类型,发现是一个数组。
我们现在知道了 ->param() 是获取所有的,那么我们要单独获取 ? 后面的参数该如何实现呢?实际上,tp5 不仅提供了这一个方法,例如:
我们修改一下
$all = Request::instance()->get();
发现打印的就只有 name 了:

有的人可能会有疑问,为什么只打印了 query 里的参数 name ,而没有打印 url 路径里的参数 id 呢?
tp5 提供了另一个方法:route来解决这个问题:
$all = Request::instance()->route();

同理,获取 body 里的 POST 请求的内容:
$all = Request::instance()->post();
测试结果:

上面我们只介绍了 param、get、route、post,tp5 文档里还有很多,大家有需要的时候再查即可。
第三种:
助手函数:
有的时候我们每次都要写 Request::instance()-> 太过麻烦,tp5 定义了一个叫做助手函数的东西,具体写法如下:
class Test
{
public function hello()
{
$all = input("param.");
$id = input("route.id");
$name = input("get.name");
$age = input("post.age");
}
}
助手函数的使用很简单,但要注意获取 $all 的时候参数是"param."
【补充】依赖注入的小实例:
use think\Request;
class Test
{
public function hello(Request $request)
{
$all = $request->param();
var_dump($all);
}
}
可以看到,我们在 hello 方法的参数里面写了 Request 作为参数,那么这个 $request 是谁来传入他的呢?
正是我们在使用 Request 实例的时候我们不关心是谁实例化的这个 Request 对象,这一点恰恰就是依赖注入的优势。不需要知道这个 $request 是谁传入的或是谁实例化的,只需要参数里声明,就可以在下面直接使用 $request。
3.数据库操作
在配置完 database.php 中的数据库名、用户名、密码和端口之后,就可以进行操作数据库了。
tp5 中操作数据库的方式有三种:使用原生 sql 语句操作数据库、使用查询构造器操作数据库、使用模型和关联模型操作数据库(我们重点讨论)。
原生 sql:
$result =Db::query('select * from banner where banner_id = ?',[$id]);
原生 sql 查询非常简单,$result 就是查询出来的数据。
但是原生的查询不能满足数据库环境变化的情况,缺点很明显。所以需要用到 tp5 的数据库访问层来进行跨数据库的操作。
查询构造器:
$result = Db::table('banner')->where('banner_id','=',$id);
这样返回的 result 是一个 query 对象,要想得到查询结果可以在后面使用 find 或 select 方法。
find 只能返回一条记录
$result = Db::table('banner')->where('banner_id','=',$id)->find();
select 能返回所有记录
$result = Db:table('banner')->where('banner_id','=','$id')->select();
让我们再来分析一下这个的结构:
查询构造器的辅助方法(也叫链式方法):
Db::table('banner')->where('banner_id','=','$id')
允许多层链式方法,都返回 query 对象,不会进行实际的查询操作。根据配置文件中的数据库的值(例如 'mysql' )对 connection 属性和 builder 属性进行相应实例化(例如 '[Mysql]')。不同的链式方法的顺序对最终结果没有影响,相同的链式方法最终的查询结果可能有区别。
后面的执行方法,进行数据库操作,并清空前面的链式方法的状态。例如:
增:->insert()
删:->delete()
改:->update()
查:->find() ->select()
where 链式方法的参数除了用表达式的写法,还可以用数组法和闭包。由于官方文档不推荐使用安全性不高且不够灵活的数组法,我们现在看一下闭包:
$result = Db::table('banner')
->where( function ($query) use($id){
$query -> where('banner_id','=','$id');})
->select();
闭包的写法就是在 where 的参数中传入一个匿名函数,匿名函数拿到外界的 $id 需要通过 use ($id) 来引入。
还有如果我们想看到中间 tp5 生成的 sql 语句,可以通过 fetchSql() 链式方法来实现:
$result = Db::table('banner')
->fetchSql()
->where( function ($query) use($id){
$query -> where('banner_id','=','$id');})
->select();
这样即使有 select 也不会执行,而是因为有 fetchSql() ,会返回相应的 sql 语句。
但我们有的时候不会每一条语句中都加一个 fetchSql() 方法,这时我们可以通过 tp5 生成的 sql 日志来观察。
我们可以在 index.php 中初始化日志(config.php 中的日志一般都是处于 test 的非开启模式的)
\think\Log::init([
'type' => 'File',
'path' => LOG_PATH,
'level' => ['sql']
])
建议生产模式下关闭该日志,以节约性能。
ORM 和模型:
对于中小型的项目,我们一般采取 ORM( Object Relation Mapping ) 的方式操作数据库。
在传统的操作中,我们一般把每次对数据库的操作想象成是返回一个二维或一维的结构。而在 ORM 中,我们把每次操作想象成是一个对象。我们通过对象拿到每一次的操作结果,此时表与表之间的关系也由键之间的关系变成了对象与对象之间的关系。
ORM 不是一种语言,也不是一种框架,而是一种思想。很多语言都有实现这个思想的框架。
通过继承 tp5 的内置 Model 类,我们将我们的业务层变成一个对象模型(事实上,不论是否继承,我们都应该把它想象成对象模型),一个模型相当于一个业务,里面可以包含多个数据库操作。这样,在控制器中我们可以直接调用被继承的 Model 类的 get 方法来获得结果。
$banner = BannerModel::get($id);
return $banner;
由于返回的 $banner 是一个对象,所以输出时不需要用 json() 包着。如果输出的 json 没有相应格式,可以在 config.php 将 default_return_type 改为 'json'。
下面我们总结一下 tp5 中的模型:
- 继承 Model 类
- 在简单的业务中,模型与表一一对应,复杂的业务中,一个模型关联多张表。
- 默认情况下,模型的名字与数据库表名存在映射关系,自动对应,可以通过写入
protected $table = 'banner_item'进行指定。 - 模型类相当于表,get 方法实例化得到的对象相当于记录
利用命令行快速创建模型:
在项目文件夹下,例如 zerg
D:\xampp\htdocs\zerg>php think make:model api/BannerItem
自动写入了:
(如果遇到 php 不是内部命令,需要配置环境变量,然后重启 PhpStorm,再次运行)
最后,不要弄混了get、all、find 和 select 这几个方法。
Db 查询用到 find 和 select,但是不能用 get 和 all。
而模型查询由于做了兼容,以上四种都可以。
对于关联模型我们新写一篇文章来探讨:
tp5 关联模型。