mapreduce的 combiner 和groupping comparator
combiner:
问题提出:
众所周知,Hadoop框架使用Mapper将数据处理成一个
- 如果我们有10亿个数据,Mapper会生成10亿个键值对在网络间进行传输,但如果我们只是对数据求最大值,那么很明显的Mapper只需要输出它所知道的最大值即可。这样做不仅可以减轻网络压力,同样也可以大幅度提高程序效率。
- 使用专利中的国家一项来阐述数据倾斜这个定义。这样的数据远远不是一致性的或者说平衡分布的,由于大多数专利的国家都属于美国,这样不仅Mapper中的键值对、中间阶段(shuffle)的键值对等,大多数的键值对最终会聚集于一个单一的Reducer之上,压倒这个Reducer,从而大大降低程序的性能。
目标:
Mapreduce中的Combiner就是为了避免map任务和reduce任务之间的数据传输而设置的,Hadoop允许用户针对map task的输出指定一个合并函数。即为了减少传输到Reduce中的数据量。它主要是为了削减Mapper的输出从而减少网络带宽和Reducer之上的负载。
数据格式转换:
map: (K1, V1) → list(K2,V2)
combine: (K2, list(V2)) → list(K3, V3)
reduce: (K3, list(V3)) → list(K4, V4)
注意:combine的输入和reduce的完全一致,输出和map的完全一致
使用注意:
对于Combiner有几点需要说明的是:
1)有很多人认为这个combiner和map输出的数据合并是一个过程,其实不然,map输出的数据合并只会产生在有数据spill出的时候,即进行merge操作。
2)与mapper与reducer不同的是,combiner没有默认的实现,需要显式的设置在conf中才有作用。
3)并不是所有的job都适用combiner,只有操作满足结合律的才可设置combiner。combine操作类似于:opt(opt(1, 2, 3), opt(4, 5, 6))。如果opt为求和、求最大值的话,可以使用,但是如果是求中值的话,不适用。
4)一般来说,combiner和reducer它们俩进行同样的操作。
但是:特别值得注意的一点,一个combiner只是处理一个结点中的的输出,而不能享受像reduce一样的输入(经过了shuffle阶段的数据),这点非常关键。具体原因查看下面的数据流解释:
融合combiner的数据流
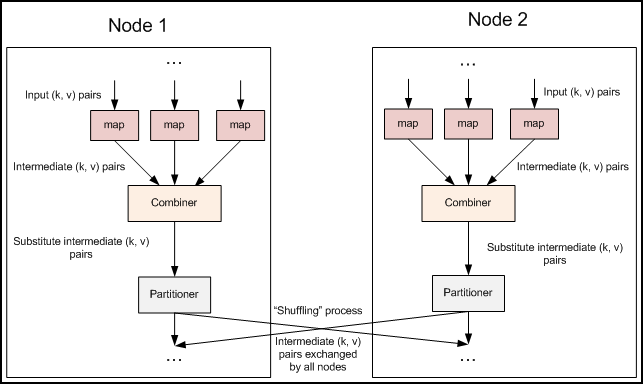
插入了Combiner的MapReduce数据流
Combiner:前面展示的流水线忽略了一个可以优化MapReduce作业所使用带宽的步骤,这个过程叫Combiner,它在Mapper之后Reducer之前运行。Combiner是可选的,如果这个过程适合于你的作业,Combiner实例会在每一个运行map任务的节点上运行。Combiner会接收特定节点上的Mapper实例的输出作为输入,接着Combiner的输出会被发送到Reducer那里,而不是发送Mapper的输出。Combiner是一个“迷你reduce”过程,它只处理单台机器生成的数据(特别重要,作者在做一个矩阵乘法的时候,没有领会到这点,把它当成一个完全的reduce的输入数据来处理,结果出错。)。
词频统计是一个可以展示Combiner的用处的基础例子,上面的词频统计程序为每一个它看到的词生成了一个(word,1)键值对。所以如果在同一个文档内“cat”出现了3次,(”cat”,1)键值对会被生成3次,这些键值对会被送到Reducer那里。通过使用Combiner,这些键值对可以被压缩为一个送往Reducer的键值对(”cat”,3)。现在每一个节点针对每一个词只会发送一个值到reducer,大大减少了shuffle过程所需要的带宽并加速了作业的执行。这里面最爽的就是我们不用写任何额外的代码就可以享用此功能!如果你的reduce是可交换及可组合的,那么它也就可以作为一个Combiner。你只要在driver中添加下面这行代码就可以在词频统计程序中启用Combiner。
grouping comparator:
问题
有如下的订单数据,想要查询出每一个订单中的最贵的商品
Order_0000001 Pdt_01 222.8
Order_0000001 Pdt_01 222.8
Order_0000002 Pdt_03 522.8
Order_0000003 Pdt_01 222.8
Order_0000004 Pdt_01 222.8
Order_0000004 Pdt_05 25.8
Order_0000005 Pdt_03 522.8
Order_0000006 Pdt_04 122.4
Order_0000007 Pdt_05 722.4
Order_0000007 Pdt_01 222.8
Order_0000001 Pdt_05 25.8
Order_0000002 Pdt_04 122.4
Order_0000002 Pdt_05 722.4- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
解决方法
第一种解决方法
在Map端读取数据,构造出相应的OrderBean对象,以Order_id为key,OrderBean为Value将数据输出
在Reduce端读取出相同的order_id的所有的OrderBean进行排序
缺点
需要自己进行排序,没有利用好Shuffle过程中的排序,效率较低
第二种解决方案
在Shuffle的过程中是会进行排序的,我们需要充分利用它
首先,排序的时候,只是会对key进行排序,所以我们需要将OrderBean作为我们的Key输出到Reduce 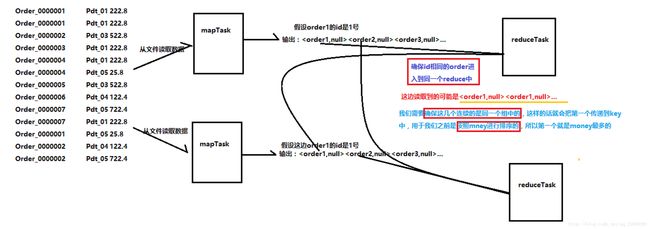
问题:
第一,不同的Order的对象可能会被分配到不同的reduce端,所以我们需要自定义分区方法,对order对象进行分区
第二,不同的Order对象是无法像一样将看成是一组的,
即使order1的order_id和order2的order_id一样的
第三,Order对象需要进行排序,按照money
解决问题:
针对第一个问题:
自己定义Partitioner类,根据order_id进行hashcode%numTasks
针对第二个问题:
自己定义一个GroupComparator类,根据order_id划分组,将order_id相同的划分到同一个组中
注意,这边进行判断的时候,当compare方法返回一个非0的时候,就会认为两个对象不是在同一个组中的
注意,它是一次判断两个连续的对象,即如果有一串对象,
即使order1和order3的order_id是一样的,那么由于order2的order_id与它们不一样,当
order1与order2的时候返回不是0,就会调用新的reduce,同理order2和order3,这就要求我们必须现根据
order_id进行排序,然后再根据money排序
针对第三个问题:
将自己定义的类继承WritableComparator,重写compare方法(必须现根据order_id进行排序,然后再根据
money排序)
java代码
public class OrderProduct implements WritableComparable{
private String order_id;
private String pdt_id;
private double money;
public String getOrder_id() {
return order_id;
}
public void setOrder_id(String order_id) {
this.order_id = order_id;
}
public String getPdt_id() {
return pdt_id;
}
public void setPdt_id(String pdt_id) {
this.pdt_id = pdt_id;
}
public double getMoney() {
return money;
}
public void setMoney(double money) {
this.money = money;
}
public int compareTo(OrderProduct o) {
//不能直接这样写,因为这样的话,那么价格相同的也会被当成同一组了
//相当于是先根据order_id进行排序,再根据money进行排序
//必须先根据order_id排序,使得相同的order_id的对象在发送到reduce端的时候是连在一起的
//因为之后的groupComparator的时候,是一个一个的跟后面的比较的,返回0,就认为是在同一个组中的
//返回不为0就不是同一个组
if(this.getOrder_id().compareTo(o.getOrder_id())==0){
return Double.valueOf(money).compareTo(o.getMoney());
}
else return this.getOrder_id().compareTo(o.getOrder_id());
/*return Double.valueOf(money).compareTo(o.getMoney());*/
}
public void write(DataOutput out) throws IOException {
out.writeUTF(order_id);
out.writeUTF(pdt_id);
out.writeDouble(money);
}
public void readFields(DataInput in) throws IOException {
order_id = in.readUTF();
pdt_id = in.readUTF();
money = in.readDouble();
}
@Override
public String toString() {
return "OrderProduct{" +
"order_id='" + order_id + '\'' +
", pdt_id='" + pdt_id + '\'' +
", money=" + money +
'}';
}
} public class FindCostMaxProduct {
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration);
job.setJarByClass(FindCostMaxProduct.class);
job.setMapperClass(FindCostMaxProductMapper.class);
job.setMapOutputKeyClass(OrderProduct.class);
job.setMapOutputValueClass(NullWritable.class);
//job.setNumReduceTasks(7);
job.setGroupingComparatorClass(OrderGroupComparator.class);
//
job.setPartitionerClass(OrderPartitioner.class);
job.setReducerClass(FindCostMaxProductReducer.class);
job.setOutputKeyClass(OrderProduct.class);
job.setOutputValueClass(NullWritable.class);
FileInputFormat.setInputPaths(job,new Path("F:\\hdp\\order\\input"));
FileOutputFormat.setOutputPath(job,new Path("F:\\hdp\\order\\output"));
job.waitForCompletion(true);
}
}
class FindCostMaxProductMapper extends Mapper{
List list = new ArrayList();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] split = value.toString().split("\t");
OrderProduct orderProduct = new OrderProduct();
orderProduct.setOrder_id(split[0]);
orderProduct.setPdt_id(split[1]);
orderProduct.setMoney(Double.valueOf(split[2]));
context.write(orderProduct,NullWritable.get());
list.add(orderProduct);
}
@Override
protected void cleanup(Context context) throws IOException, InterruptedException {
Collections.sort(list);
System.out.println("1");
}
}
class FindCostMaxProductReducer extends Reducer{
@Override
protected void reduce(OrderProduct key, Iterable values, Context context) throws IOException, InterruptedException {
context.write(key,NullWritable.get());
}
}
class OrderPartitioner extends Partitioner{
public int getPartition(OrderProduct orderProduct, NullWritable nullWritable, int numPartitions) {
return orderProduct.getOrder_id().hashCode() % numPartitions;
}
}
/*
默认情况下,即使将order_id相同的订单分配到了同一个reduce中,但是作为key的他们却不会是在同一个组中
不想这样三个是在同一个组中的
*/
class OrderGroupComparator extends WritableComparator{
public OrderGroupComparator(){
super(OrderProduct.class,true);
}
//注意重写的需要是参数为WritableComparable类型的方法,因为其还有一个重载的参数类型为Object的方法
@Override
public int compare(WritableComparable a, WritableComparable b) {
OrderProduct o1 = (OrderProduct) a;
OrderProduct o2 = (OrderProduct) b;
return o1.getOrder_id().compareTo(o2.getOrder_id());
}
}