Kafka Producer send原理及重试机制浅析(retries/acks如何被使用的)
我们在使用kafka时会在producer端定义这么两个变量的值:retries 和 acks
ack已经介绍过了
retries是kafka producer针对可重试异常自动发起重试的次数
我们在使用kafkaTemplate时发现:
Spring 提供了一个producerListener接口,在发送成功/失败时会调用这个接口的onSend/onError方法,我们只需要实现这个接口就可以在发送成功/失败的时候处理自己的业务逻辑。
producer.send(producerRecord, new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
try {
if (exception == null) {
future.set(new SendResult<>(producerRecord, metadata));
if (KafkaTemplate.this.producerListener != null) {
KafkaTemplate.this.producerListener.onSuccess(producerRecord, metadata);
}
if (KafkaTemplate.this.logger.isTraceEnabled()) {
KafkaTemplate.this.logger.trace("Sent ok: " + producerRecord + ", metadata: " + metadata);
}
}
else {
future.setException(new KafkaProducerException(producerRecord, "Failed to send", exception));
if (KafkaTemplate.this.producerListener != null) {
KafkaTemplate.this.producerListener.onError(producerRecord, exception);
}
但是问题来了,我们配的这个ack 和 retries干啥了呢
相关代码:org.apache.kafka.clients.producer
首先介绍一下kafkaProducer的发送流程
1、构建kafkaProducer 时会启动一个新线程Sender,默认情况下只有一个KafkaProducer,
2、将要发送数据按照topic和partition放到队列Deque中,实例化KafkaProducer会实例RecordAccumulator,RecordAccumulator维护了一个Map,key为不同的主题和partition,value为数据队列
private final ConcurrentMap<TopicPartition, Deque<ProducerBatch>> batches;
3、Sender会轮寻这个队列 进行发送
4、如果发送失败,判断是否属于可重试异常,如果可以重试,则放入队列等待再次轮寻,如果不可以重试则抛出异常,由业务方catch处理
KafkaProducer构造函数:
private final Sender sender;
private final Thread ioThread;
private KafkaProducer(ProducerConfig config, Serializer<K> keySerializer, Serializer<V> valueSerializer) {
//省略无关参数
//我们配置的重试次数
int retries = configureRetries(config, transactionManager != null, log);
//acks
short acks = configureAcks(config, transactionManager != null, log);
this.sender = new Sender(logContext,
client,
this.metadata,
this.accumulator,
maxInflightRequests == 1,
config.getInt(ProducerConfig.MAX_REQUEST_SIZE_CONFIG),
acks,
retries,
metricsRegistry.senderMetrics,
Time.SYSTEM,
this.requestTimeoutMs,
config.getLong(ProducerConfig.RETRY_BACKOFF_MS_CONFIG),
this.transactionManager,
apiVersions);
String ioThreadName = NETWORK_THREAD_PREFIX + " | " + clientId;
//将sender注册进该ioThread
this.ioThread = new KafkaThread(ioThreadName, this.sender, true);
//实际启动的是sender线程
this.ioThread.start();
}
接下来看KafkaProducer的send逻辑
这里介绍一下RecordAccumulator
RecordAccumulator是保存需要发送的消息或者重试消息的核心。发送消息之前先把消息存放在这里,异步线程KafkaThread启动后从这里取消息然后发送到broker。当发送出错且允许重试时,又会把这些需要重试的消息保存到这里再进行重试。



回到Sender,观察run方法
void run(long now) {
//...省略前面代码
//发送核心逻辑
long pollTimeout = sendProducerData(now);
//发送结果回调
client.poll(pollTimeout, now);
}
private long sendProducerData(long now) {
// get the list of partitions with data ready to send
RecordAccumulator.ReadyCheckResult result = this.accumulator.ready(cluster, now);
//从之前的Deque队列中,根据topic partition取数据
Map<Integer, List<ProducerBatch>> batches = this.accumulator.drain(cluster, result.readyNodes,
this.maxRequestSize, now);
//发送核心逻辑
sendProduceRequests(batches, now);
return pollTimeout;
}
//遍历发送
private void sendProduceRequests(Map<Integer, List<ProducerBatch>> collated, long now) {
for (Map.Entry<Integer, List<ProducerBatch>> entry : collated.entrySet())
sendProduceRequest(now, entry.getKey(), acks, requestTimeout, entry.getValue());
}
构建了一个回调函数,请求

进入回调逻辑
/**
* Handle a produce response
*/
private void handleProduceResponse(ClientResponse response, Map<TopicPartition, ProducerBatch> batches, long now) {
RequestHeader requestHeader = response.requestHeader();
int correlationId = requestHeader.correlationId();
if (response.wasDisconnected()) {
log.trace("Cancelled request with header {} due to node {} being disconnected",
requestHeader, response.destination());
for (ProducerBatch batch : batches.values())
completeBatch(batch, new ProduceResponse.PartitionResponse(Errors.NETWORK_EXCEPTION), correlationId, now);
} else if (response.versionMismatch() != null) {
log.warn("Cancelled request {} due to a version mismatch with node {}",
response, response.destination(), response.versionMismatch());
for (ProducerBatch batch : batches.values())
completeBatch(batch, new ProduceResponse.PartitionResponse(Errors.UNSUPPORTED_VERSION), correlationId, now);
} else {
log.trace("Received produce response from node {} with correlation id {}", response.destination(), correlationId);
// if we have a response, parse it
if (response.hasResponse()) {
ProduceResponse produceResponse = (ProduceResponse) response.responseBody();
//遍历所有response
for (Map.Entry<TopicPartition, ProduceResponse.PartitionResponse> entry : produceResponse.responses().entrySet()) {
TopicPartition tp = entry.getKey();
ProduceResponse.PartitionResponse partResp = entry.getValue();
ProducerBatch batch = batches.get(tp);
//处理response
completeBatch(batch, partResp, correlationId, now);
}
this.sensors.recordLatency(response.destination(), response.requestLatencyMs());
} else {
// this is the acks = 0 case, just complete all requests
for (ProducerBatch batch : batches.values()) {
completeBatch(batch, new ProduceResponse.PartitionResponse(Errors.NONE), correlationId, now);
}
}
}
}
进入competeBatch方法
如果不存在异常 则返回成功
如果存在异常,判断是否可以重试
可以重试 则将发送数据重新放入队列等待轮寻
private void reenqueueBatch(ProducerBatch batch, long currentTimeMs) {
this.accumulator.reenqueue(batch, currentTimeMs);
this.sensors.recordRetries(batch.topicPartition.topic(), batch.recordCount);
}
public void reenqueue(ProducerBatch batch, long now) {
batch.reenqueued(now);
Deque<ProducerBatch> deque = getOrCreateDeque(batch.topicPartition);
synchronized (deque) {
if (transactionManager != null)
insertInSequenceOrder(deque, batch);
else
deque.addFirst(batch);
}
}
如果不可重试 则返回错误信息
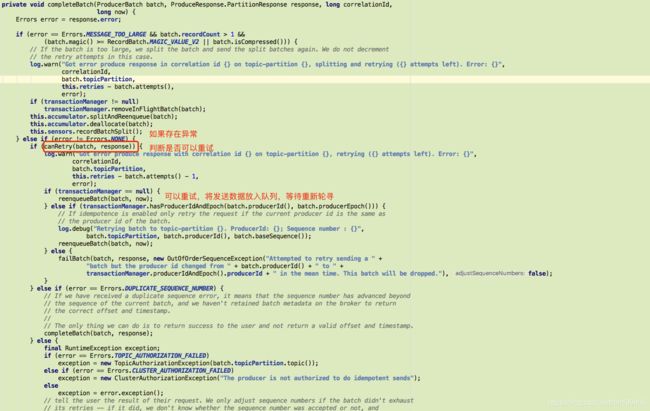
canRetry方法中,用到了retries
private boolean canRetry(ProducerBatch batch, ProduceResponse.PartitionResponse response) {
//重试次数小于配置 且 (属于可重试异常或者transactionManager判断可重试)
return batch.attempts() < this.retries &&
((response.error.exception() instanceof RetriableException) ||
(transactionManager != null && transactionManager.canRetry(response, batch)));
}
client.send逻辑中用到了acks
附:打断点跟踪send流程
断点打在Sender类的sendProduceRequest 因为发送一定会走到这个方法

构建了请求参数 及回调函数

调用回调函数的地方:

response就是前文定义的
private void completeResponses(List<ClientResponse> responses) {
for (ClientResponse response : responses) {
try {
response.onComplete();
} catch (Exception e) {
log.error("Uncaught error in request completion:", e);
}
}
}
断点打在回调函数上,定义条件 topic = 自己测试用的

附:KafkaException
来源网上

本机跑的RetriableException的子类
class org.apache.kafka.common.errors.KafkaStorageException
class org.apache.kafka.common.errors.LeaderNotAvailableException
class org.apache.kafka.common.errors.NotCoordinatorForGroupException
class org.apache.kafka.common.errors.UnknownTopicOrPartitionException
class org.apache.kafka.common.errors.DisconnectException
class org.apache.kafka.common.errors.NotEnoughReplicasException
class org.apache.kafka.common.errors.GroupLoadInProgressException
class org.apache.kafka.common.errors.NotCoordinatorException
class org.apache.kafka.common.errors.NotLeaderForPartitionException
class org.apache.kafka.common.errors.NetworkException
class org.apache.kafka.common.errors.CorruptRecordException
class org.apache.kafka.common.errors.CoordinatorLoadInProgressException
class org.apache.kafka.common.errors.TimeoutException
class org.apache.kafka.common.errors.CoordinatorNotAvailableException
class org.apache.kafka.common.errors.NotControllerException
class org.apache.kafka.common.errors.NotEnoughReplicasAfterAppendException
class org.apache.kafka.common.errors.GroupCoordinatorNotAvailableException
send轮寻待发送队列:
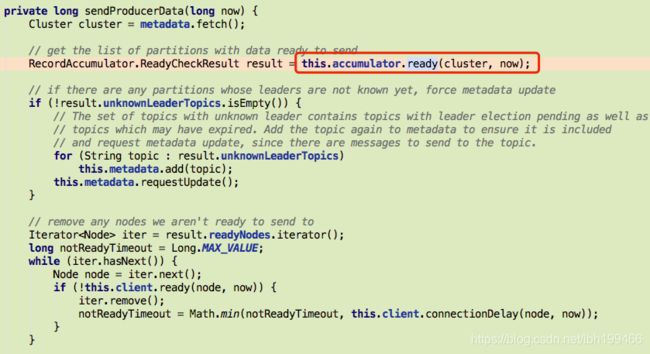

在这里插入代码片