Linux内核工程导论——数据结构:链表与哈希
1 链表与哈希表
1.1 双向链表
1.2 hlist
双向链表有个显而易见的坏处,就是如果有很多链表,但可能大部分链表都很短的时候(很可能只有一个节点),此时双向链表的next和prev的作用都可以用一个域来替代。典型的是哈希表,我们知道哈希表使用哈希函数计算得到一个地址,然后直接访问该地址的机制实现快速访问的,但是哈希算法不可避免的会有哈希冲突(多个输入产生了同一个地址输出),此时解决冲突的方法就是哈希桶,一般在同一个计算地址的位置实现一个链表,该链表链出所有哈希结果为本地址的值。
此时,一方面,哈希结果一般只是一个整数,你用两个整数大小的双向链表节点就会无法放得下一个哈希结果。即使你人为的规定哈希得到的是两个整数大小的值,虽然双向链表也可用了,但浪费了整整一倍的空间。好的算法设计是不会让这种事情发生的。所以重新设计了hlist,专门用于放哈希桶链表。
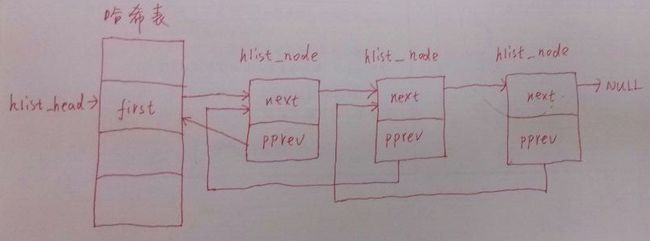
- //hash桶的头结点
- struct hlist_head {
- struct hlist_node *first;//指向每一个hash桶的第一个结点的指针
- };
- //hash桶的普通结点
- struct hlist_node {
- struct hlist_node *next;//指向下一个结点的指针
- struct hlist_node **pprev;//指向上一个结点的next指针的地址
- };
1.3 ScatterList
1.3.1 scatterlist的存储结构
该数据结构存在的原因是系统运行会产生内存碎片,为了利用内存碎片传送大数据,在DMA支持分离的多块内存同时的传输下,对应的产生的软件结构。其表示的是多块分离的内存。
scatterlist的主要结构体是:
struct scatterlist {
unsignedlong page_link; //指向下个scatterlist节点的地址
unsignedint offset; //偏移
unsignedint length; //长度
};
这里的数据结构的命名与设计非常不易懂,但是很高效,核心在page_link。
你可以在任何内存位置定义一个scatterlist的数组,scatterlist连续的存放于内存中。结构体内部的page_link指向数据的存储页,offset表示其指向的内存在本page的偏移,length表示其指向的内存空间的大小(可以大于一个页)。scatterlist的数组称为scatterlist table。
然而,linux允许两个scatterlist被连接起来,构成一个更大的scatterlist。(如果多次调用,就可以连接起很多个scatterlist),这里级联的方法使用的仍旧是该结构体的page_link域。如果区分两种功能呢?由于page_link不论是指向一个page页地址,还是指向一个scatterlist结构体,其最后的两位都是0(不止两位,但只用了两位)。所以就可以使用最后的两位来区别解释前面的地址到底是页地址还是scatterlist地址:
01标示地址指向的是scatterlist(级联情况),10标示后面没有级联的节点了,00表示page_link指向的是存储的页地址。
当一个scatterlist结构体用作级联的情况下,该结构体内的其他域都为0,表示该节点不指向任何可用的存储空间,而是只是用来连接下一个scatterlist table的桥梁。
struct sg_table {
structscatterlist *sgl; /* the list */
unsignedint nents; /* number of mappedentries */
unsignedint orig_nents; /* original size of list*/
};
sg_table是对scatter_list的总体概括,内含了scaterlist和一个map之前的块数目,和一个map之后的块数目。这里的map的意义是,各个分离的内存有可能恰好相邻,可以合并。
1.3.2 scatterlist的遍历
scatterlist table由于可以被拼接(chain),不同的scatterlist如果所指向的内存是相邻的还可以被合并,所以其遍历格外复杂。
1.4 llist
llist全称是Lock-less NULL terminated single linked list,意思是不需要加锁的list。在生产者消费者模型下,如果有多个生产者和多个消费者,生产者意味者链表添加,消费者意味着链表删除操作。但多个一起操作时就需要加锁,加锁毕竟是高耗费的操作,内核现在流行无锁操作,为这个需求诞生的专门的list就是llist。
典型的情形就是中断。我们都知道中断有上半部分和下半部分。上半部分是会关闭所有中断,使系统失去响应,为了减小这个时间,上班部分不能休眠,复杂的操作也得放到下半部分执行。也就是意味着上班部分的代码不能使用加锁操作,而中断重入是很容易发生的,这就又诞生了加锁的需求。最好的提供上半部分使用list数据结构能力的方式就是使用无锁list。
内核实现的方法是使用cmpxchg宏。这本来是一个intel平台的汇编指令,linux喜欢这个指令,但其他平台不一定有,所以就封装了一个宏,在其他平台重新实现,而intel平台就可以直接调用cmpxchg指令即可。这个指令是原子的,有3个参数,对比第一个和第二个参数,如果相等就写入第三个参数到第一个参数指向的地址。如果不相等就返回第三个参数。本意是将第三个参数写入第一个参数指向的地址。但是加上了对比,对比之后写入之前第一个参数指向的内存就不会被其他任何指令修改,这就确保了在写入操作之前和之后的一致性。具体到llist就是在添加链表节点到头部时,需要确保修改head->first指针时,没有其他的并行操作也在修改。如此就会造成同时进行的两个操作有一个丢失。所以cmpxchg先读出head->next,然后head->first作为第一个参数,刚读出的head->first作为第二个,要添加的作为第三个。
作者是intel公司的 Huang Ying。
LRU
List-lru
在mm下有定义,主要用在内存管理。在 Linux 中,操作系统对 LRU 的实现主要是基于一对双向链表:active链表和 inactive 链表,这两个链表是 Linux操作系统进行页面回收所依赖的关键数据结构,每个内存区域都存在一对这样的链表。顾名思义,那些经常被访问的处于活跃状态的页面会被放在active链表上,而那些虽然可能关联到一个或者多个进程,但是并不经常使用的页面则会被放到 inactive链表上。页面会在这两个双向链表中移动,操作系统会根据页面的活跃程度来判断应该把页面放到哪个链表上。页面可能会从 active 链表上被转移到 inactive链表上,也可能从 inactive 链表上被转移到 active链表上,但是,这种转移并不是每次页面访问都会发生,页面的这种转移发生的间隔有可能比较长。那些最近最少使用的页面会被逐个放到inactive 链表的尾部。进行页面回收的时候,Linux操作系统会从 inactive链表的尾部开始进行回收。
LIRS
这个算法是LRU的改进算法。LRU在遍历时会导致被全部刷新,失去意义,反而会带来效率的损失。但是LIRS使用两层列表,一个是cold,一个是hot。利用两层数据保证经常使用的数据不被遍历操作刷掉。但是这个算法在内核中还没有实现,估计日后有人会做。