Oracle函数
Oracle函数
一:函数概述
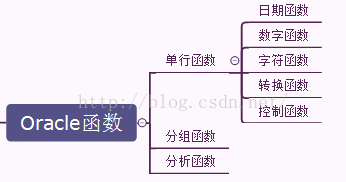
二:单行函数
(1)日期函数
A、sysdate:日期函数

B、current_timestamp:获取系统时间

C、to_char(sysdate,'yyyy-mm-dd hh24:mi:ss'):格式化日期

D、to_date('2004-05-07 13:23:44','yyyy-mm-dd hh24:mi:ss'):将字符串转换成日期

E、add_months(sysdate, 2):添加月份

F、last_day(sysdate):返回日期中指定月的最后一天

G、months_between(sysdate, add_months(sysdate, 4)):计算两个日期之前相差多少个月

H、next_day(sysdate, 2):返回下个星期一是哪一天,星期日用数字1表示,以此类推

I、extract(year from sysdate):用于返回日期/时间的单独部分,比如年、月、日、小时、分钟等等。year、month、day、hour、minute、second

(2)数字函数
A、abs(x):返回x的绝对值
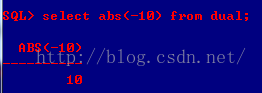
B、ceil(x) :返回大于等于x的最小整数值
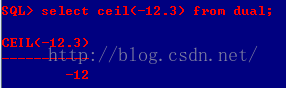
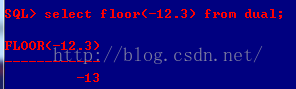
C、floor(x):返回小于等于x的最大整数值
D、power(x,y) :返回x的y次幂

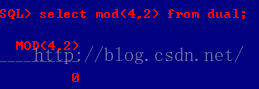
E、mod(x,y):返回x除以y的余数
F、round(x[,y]):返回四舍五入后的值

G、sqrt(x) :返回x的平方根

H、trunc(x[,y]) :返回x按精度y截取后的值,y为正,表示保留的小数位数,y为负,小数点左边y位变成0,y为0或不写取整


(3)字符函数
A、chr(x):将数字转换成字符

B、Ascii:将字符转换成数字

C、Concat:连接字符串

D、Ltrim:删除左边空格

E、Rtrim:删除右边空格

F、Trim:删除两边空格

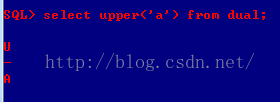
G、Upper:转换成大写
H、replace(string,search_str[,replace_str]):替换

I、translate(string,from_str,to_str):替换,和replace相同,但比replace强大。如select translate('abcbbaadef','bad','#@') from dual (b将被#替代,a将被@替代,d对应的值是空值,将被移走)

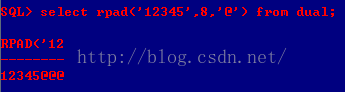
J、rpad(string1,x[,string2]):填充/截取到x个长度,不足的话右边用指定字符填充
K、lpad(string1,x[,string2]):填充/截取到x个长度,不足的话左边用指定字符填充

L、substr(string,a[,b]):截取子串
M、Length:求字符串的长度

(4)转换函数
A、TO_CHAR(SYSDATE, 'YYYY-MM-DD HH24:MI:SS'):转换为字符

B、TO_DATE('2011/03/24', 'YYYY-MM-DD'):转换为日期

C、TO_NUMBER('2008') AS Year:转换数字

D、decode():将查询结果翻译成其他值(即以其他形式表现出来),decode(条件,值1,翻译值1,值2,翻译值2,...值n,翻译值n,缺省值)

(5)空值函数
A、NVL(expr1, expr2):expr1为NULL,返回expr2;不为NULL,返回expr1。注意两者的类型要一致

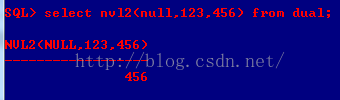
B、NVL2(expr1, expr2, expr3):expr1不为NULL,返回expr2;为NULL,返回expr3。expr2和expr3类型不同的话,expr3会转换为expr2的类型
C、NULLIF (expr1, expr2) :expr1和expr2相等返回NULL,不等则返回expr1

三:分组函数
(1)分组排序函数
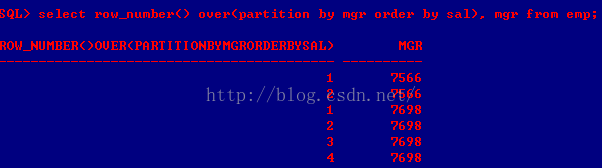
A、row_number() over(partition by col1 order by col2):根据col1分组,再根据每组的col2排序,返回排序序号
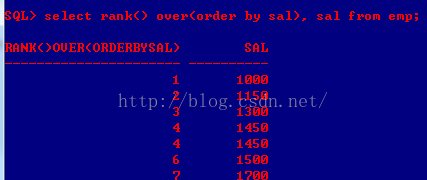
B、rank() over(partition by col1 order by col2):rank()是跳跃排序,有两个第二名时接下来就是第四名(同样是在各个分组内)
C、dense_rank() over(partition by col1 order by col2):dense_rank()也是连续排序,有两个第二名时仍然跟着第三名

四:分析函数
(1)sum函数,统计总和
select earnmonth, area, sum(personincome) from earnings group by earnmonth,area;

(2)rollup函数:按照月份,地区统计收入
select earnmonth,area, sum(personincome) from earnings group by rollup(earnmonth,area);

(3)cube函数:按照月份,地区进行收入总汇总
select earnmonth, area, sum(personincome)from earnings group by cube(earnmonth,area)
order by earnmonth,area nulls last;

(4)grouping函数:语法:grouping(column)判断当前列的值是否则由column产生,只能配合cube和rollup使用
Select decode(grouping(earnmonth),1,'所有月份',earnmonth)月份, decode(grouping(area),1,'全部地区',area)地区, sum(personincome)总金额 from earnings group by cube(earnmonth,area) order by earnmonth,area nulls last;
