koa2后台步骤(5)——sequelize操作数据库
orm的方式:
数据表使用js的模型 (class或者对象) 来代替
一条或多条记录,用js的一个对象或者数组替代
sql语句用对象的方法代替。
抛开后台项目,新建文件夹sequelize-test
npm init -y
npm i mysql2 sequelize -d
查看package.json
"dependencies": {
"mysql2": "^2.0.2",
"sequelize": "^5.21.2"
}
ps: 参考https://www.npmjs.com/package/mysql2,思考在不使用orm工具时候如何连接数据库,如何操作数据库。
git config --global core.autocrlf false 可以解决一个报错
新建src文件夹下新建文件seq.js 参考getting-started
创建sequelize模型,连接数据库
const Sequelize = require('sequelize');
const conf = {
host: 'localhost',
dialect: 'mysql'
}
const seq = new Sequelize('flyingfish_db', 'root', '950210zsrtxdy', conf)
module.exports = seq
// 接下来就可以使用这个实例进行模型创建以及查询等操作
测试连接,注释掉module.exports = seq
在seq.js文件夹下方添加如下代码
seq
.authenticate()
.then(() => {
console.log('Connection has been established successfully.');
})
.catch(err => {
console.error('Unable to connect to the database:', err);
});
运行src/seq.js
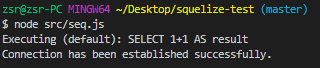
创建模型
新建model.js
const Sequelize = require('sequelize')
const seq = require('./seq.js')
// 创建 User 模型,虽然下面是user,但是数据表的名字会变成users
const User = seq.define('user', {
// id会自动创建并设为主键,并且自增
userName: {
type: Sequelize.STRING, //varchar(255)
allowNull: false //不能为空
},
password: {
type: Sequelize.STRING,
allowNull: false
},
nickName: {
type: Sequelize.STRING,
comment:'昵称'
// allowNull defaults to true
}
// 自动创建createdAt和updatedAt
}, {
// options
});
module.exports = { User }
新建sync.js
const seq = require('./seq.js')
require('./model.js')
// 3 测试连接
seq.authenticate()
.then(() => {
console.log('Connection has been established successfully.');
})
.catch(err => {
console.error('Unable to connect to the database:', err);
});
// 4 执行同步
seq.sync({force: true}).then(()=>{
console.log('sync ok')
process.exit() //不退出sequelize会一直占用进程
})

自动生成的
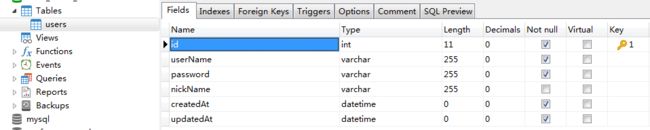
在添加comment之后。

接着创建blog
const Blog = seq.define('blog', {
title: {
type: Sequelize.STRING,
allowNull: false
},
content: {
type: Sequelize.TEXT,
allowNull: false
},
userId: {
type: Sequelize.INTEGER,
allowNull: false
},
})
输出
module.exports = { User, Blog }
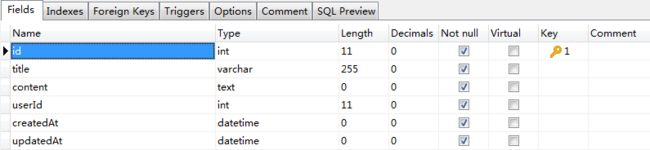
总结: 连接数据库 —— 创建数据模型 —— 测试连接 ——执行同步
创建外键的代码
在model.js里
// 外键关联
Blog.belongsTo(User,{
// 创建外键 Blog.userId -> User.id 是一个多对一的关系。
foreignKey: 'userId'
})
还有Blog.belongsTo(User)这种写法,
我们需要把之前创建Blog模型的userId这一项给去掉,其实User的id还有Blog的userId都可以自动生成的。(这种写法并不推荐,不明显)
创建外键的两种用法
// 外键关联
Blog.belongsTo(User,{
// 创建外键 Blog.userId -> User.id 是一个多对一的关系。
foreignKey: 'userId'
})
// 创建外键的另一种方式
User.hasMany(Blog,{
// 创建外键 Blog.userId -> User.id 是一个一对多的关系。
foreignKey: 'userId'
})
为什么要两个一起写呢?因为可以谁在前面谁就可以优先索引。
测试

这里有一个问题就是为什么从users里面看不到外键,而从blogs里面可以看得到?
画一下ER图,navicat怎么画ER图?
选择report 然后点击右下角的![]()
就可以看到ER图:
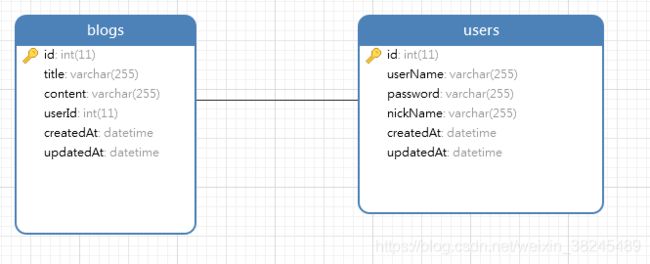
怎么导出为pdf以后再想吧。
插入数据
新建create.js文件
IO操作是异步操作,使用async和await
// insert 语句
const { Blog, User } = require('./model.js')
// ! 表示忽略之前的出现错误,隔开下面的代码,是自保的一种方法。
!(async function(){
// 创建用户,通过create的方式插入一条新的数据
const zhangsan = await User.create({
userName: 'zhangsan',
password: '123',
nickName: '张三'
})
console.log('zhangsan: ',zhangsan.dataValues)
console.log('zhangsanId: ',zhangsan.dataValues.id)
const lisi = await User.create({
userName: 'lisi',
password: '123',
nickName: '李四'
})
console.log('lisiId: ',lisi.dataValues.id)
const blog1 = await Blog.create({
title:'标题1',
content:'内容1',
userId:zhangsan.dataValues.id
})
const blog2 = await Blog.create({
title:'标题2',
content:'内容2',
userId:lisi.dataValues.id
})
const blog3 = await Blog.create({
title:'标题3',
content:'内容3',
userId:lisi.dataValues.id
})
console.log('blog1: ',blog1.dataValues)
console.log('blog2: ',blog2.dataValues)
console.log('blog3: ',blog3.dataValues)
})()
查询数据
新建一个select.js
查询单条数据
const { User, Blog } =require('./model.js')
!(async function(){
// 查询一条记录
const zhangsan = await User.findOne({
where:{
userName:'zhangsan'
}
})
console.log('zhangsan:',zhangsan.dataValues)
// 查询特定的列项
const zhangsanColumns = await User.findOne({
attributes: ['userName','nickName'],
where:{
userName:'zhangsan'
}
})
console.log('zhangsanColumns:', zhangsanColumns.dataValues)
})()
查询一个列表
const zhangsanBlogList = await Blog.findAll({
where:{
userId:2
},
order:[
['id','desc']
]
})
想想怎么输出这个zhangsanBlogList
zhangsanBlogList.forEach(item=>{
console.log(item.dataValues)
})
还有这种
console.log('zhangsanBlogList :', zhangsanBlogList.map(blog=>
blog.dataValues
))
map后面是怎么写的。
分页
const zhangsanBlogList = await Blog.findAll({
limit:2,
offset:0,
where:{
userId:2
},
order:[
['id','desc']
]
})
console.log('zhangsanBlogList :', zhangsanBlogList.map(blog=>
blog.dataValues
))
查询总数
const blogListAndCount = await Blog.findAndCountAll({
limit:2,
offset:0,
order:[
['id','desc']
]
})
console.log(blogListAndCount.count,
blogListAndCount.rows.map(blog=>blog.dataValues))
连表查询依赖于之前做的外键关联
为什么外键关联要两个一起写?
连表查询1
// 需要找出blog列表,而且每一条需要包含作者的名字和昵称
const blogListWithUser = await Blog.findAndCountAll({
order:[
['id','desc']
],
include:[{
model:User,
attributes:['userName','nickName'],
where:{
id:2
}
}]
})
console.log(blogListWithUser.count,
blogListWithUser.rows.map(blog=>{
const blogVal = blog.dataValues;
const userVal = blogVal.user.dataValues;
blogVal.user = userVal
return blogVal
}))
连表查询2

每个博客对应一个用户,一个用户对应多个博客,从用户表做索引的话
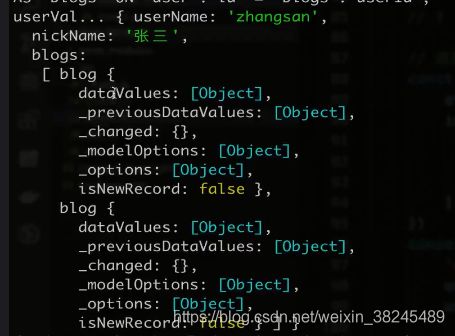
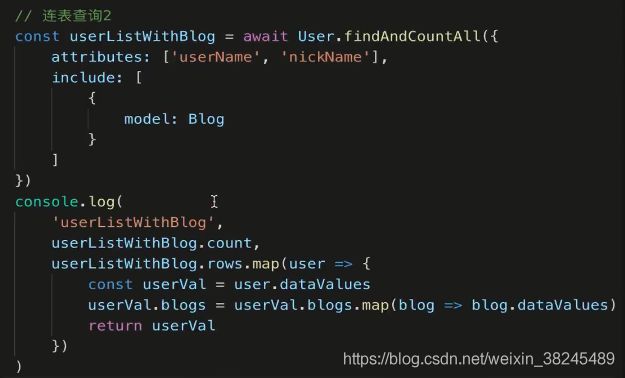

更新
更新用户昵称
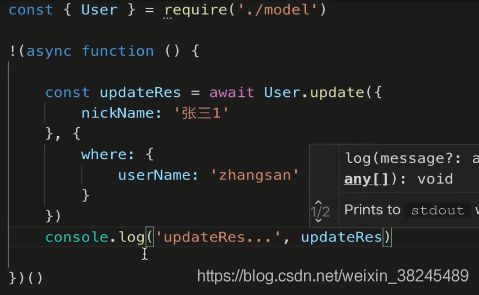
这个是返回结果
![]()
如果这个修改元素的第一个数大于0就是修改成功了。
![]()
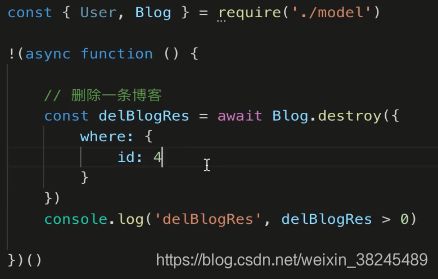
删除一个用户的话也会把他对应的文章给删除掉,因为已经做了外键关联了,他们之间有删除的关系
因为外键不是我们自己建的,它会自动的restrict模式,不一定能够删除成功
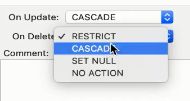
所以我们试着删一下,不成功可以再改
![]()
删除更新遇到问题如果是跟外键有关,就可以去可视化操作界面
![]()
连接池:
问:什么是连接池? 连接池是数据库本身的机制,连接池本身存在在内存或进程中提供了很多现成的连接
问:线上环境怎么实现连接池(pool),其中的max和min的参数的意义?idle参数的意思?如果一个连接池多长时间内没有被使用,被释放
conf.pool = {
max:5,
min:0,
idle:10000 //10s
}
问:怎么判断线上环境还是线下环境?