字符串与正则表达式
Python 3.x完全支持中文字符,默认使用UTF8编码格式,无论是一个数字、英文字母,还是一个汉字,都按一个字符对待和处理。
>>> s = '中国山东烟台'
>>> len(s) #字符串长度,或者包含的字符个数
6
>>> s = '中国山东烟台ABCDE' #中文与英文字符同样对待,都算一个字符
>>> len(s)
11
>>> 姓名 = '张三' #使用中文作为变量名
>>> print(姓名) #输出变量的值
张三

%i和%d 没有区别。%i 是老式写法。都是整型格式。int x,y;scanf(“%i %d”,&x,&y); // 没问题printf(“%d %i”,x,y); // 没问题i % x – 整除取余运算。
>>> x = 1235
>>> so="%o" % x
>>> so
"2323"
>>> sh = "%x" % x
>>> sh
"4d3"
>>> se = "%e" % x
>>> se
"1.235000e+03"
>>> chr(ord("3")+1)
"4"
>>> "%s"%65
"65"
>>> "%s"%65333
"65333"
>>> "%d"%"555"
TypeError: %d format: a number is required, not str
Formatted String Literals
从Python 3.6.x开始支持一种新的字符串格式化方式,官方叫做Formatted String Literals,其含义与字符串对象的format()方法类似,但形式更加简洁
>>> name = 'Dong'
>>> age = 39
>>> f'My name is {name}, and I am {age} years old.'
'My name is Dong, and I am 39 years old.'
>>> width = 10
>>> precision = 4
>>> value = 11/3
>>> f'result:{value:{width}.{precision}}'
'result: 3.667'
字符串常用方法
find( )、rfind()、index()、rindex()、count()
*find()和rfind方法分别用来查找一个字符串在另一个字符串指定范围(默认是整个字符串)中首次和最后一次出现的位置,如果不存在则返回-1;
index()和rindex()方法用来返回一个字符串在另一个字符串指定范围中首次和最后一次出现的位置,如果不存在则抛出异常;
count()方法用来返回一个字符串在另一个字符串中出现的次数.*
>>> s="apple,peach,banana,peach,pear"
>>> s.find("peach")#从左边开始找字符串位置
6
>>> s.find("peach",7)
19
>>> s.find("peach",7,20)
-1
>>> s.rfind('p')#从右边开始
25
>>> s.index('p')#从左边开始
1
>>> s.index('pe')
6
>>> s.index('pear')
25
>>> s.index('ppp')
Traceback (most recent call last):
File "" , line 1, in
s.index('ppp')
ValueError: substring not found
>>> s.count('p')
5
>>> s.count('pp')
1
>>> s.count('ppp')
0
split()、rsplit()、partition()、rpartition()
split()和rsplit()方法分别用来以指定字符为分隔符,将字符串左端和右端开始将其分割成多个字符串,并返回包含分割结果的列表;partition()和rpartition()用来以指定字符串为分隔符将原字符串分割为3部分,即分隔符前的字符串、分隔符字符串、分隔符后的字符串,如果指定的分隔符不在原字符串中,则返回原字符串和两个空字符串。
>>> s = 'hello world \n\n My name is Dong '
>>> s.split()#分割多个字符串
['hello', 'world', 'My', 'name', 'is', 'Dong']
>>> s = '\n\nhello world \n\n\n My name is Dong '
>>> s.split()
['hello', 'world', 'My', 'name', 'is', 'Dong']
>>> s = '\n\nhello\t\t world \n\n\n My name\t is Dong '
>>> s.split()
['hello', 'world', 'My', 'name', 'is', 'Dong']
>>> s = '\n\nhello\t\t world \n\n\n My name is Dong '
>>> s.split(None,1)
['hello', 'world \n\n\n My name is Dong ']
>>> s.rsplit(None,1)#从右边开始分割
['\n\nhello\t\t world \n\n\n My name is', 'Dong']
>>> s.split(None,2)
['hello', 'world', 'My name is Dong ']
>>> s.rsplit(None,2)
['\n\nhello\t\t world \n\n\n My name', 'is', 'Dong']
['hello', 'world', 'My', 'name', 'is', 'Dong']
>>> s.split(maxsplit=6)
['hello', 'world', 'My', 'name', 'is', 'Dong']
>>> s.split(maxsplit=100)
['hello', 'world', 'My', 'name', 'is', 'Dong']
调用split()方法并且不传递任何参数时,将使用任何空白字符作为分隔符,把连续多个空白字符看作一个;明确传递参数指定split()使用的分隔符时,情况略有不同。
>>> s = "apple,peach,banana,pear"
>>> s.partition(',') #从左侧使用逗号进行切分
('apple', ',', 'peach,banana,pear')
>>> s.rpartition(',') #从右侧使用逗号进行切分
('apple,peach,banana', ',', 'pear')
>>> s.rpartition('banana') #使用字符串作为分隔符
('apple,peach,', 'banana', ',pear')
>>> 'abababab'.partition('a')
('', 'a', 'bababab')
>>> 'abababab'.rpartition('a')
('ababab', 'a', 'b')
查找替换replace(),类似于“查找与替换”功能
>>> s="中国,中国"
>>> s
中国,中国
>>>s2=s.replace("中国", "中华人民共和国")
>>> s2
中华人民共和国,中华人民共和国
>>> words = ('测试', '非法', '暴力', '话')
>>> text = '这句话里含有非法内容'
>>> for word in words:
if word in text:
text = text.replace(word, '***')
>>> text
'这句***里含有***内容'
成员判断,关键字in
>>> "a" in "abcde" #测试一个字符中是否存在于另一个字符串中
True
>>> 'ab' in 'abcde'
True
>>> 'ac' in 'abcde' #关键字in左边的字符串作为一个整体对待
False
>>> "j" in "abcde"
False
可变字符串
在Python中,字符串属于不可变对象,不支持原地修改,如果需要修改其中的值,只能重新创建一个新的字符串对象。然而,如果确实需要一个支持原地修改的unicode数据对象,可以使用io.StringIO对象或array模块。
>>> import io
>>> s = "Hello, world"
>>> sio = io.StringIO(s)
>>> sio.getvalue()
'Hello, world'
>>> sio.seek(7)
7
>>> sio.write("there!")
6
>>> sio.getvalue()
'Hello, there!'
>>> import array
>>> a = array.array('u', s)
>>> print(a)
array('u', 'Hello, world')
>>> a[0] = 'y'
>>> print(a)
array('u', 'yello, world')
>>> a.tounicode()
'yello, world'
正则表达式
- 正则表达式是字符串处理的有力工具和技术。
- 正则表达式使用某种预定义的模式去匹配一类具有共同特征的字符串,主要用于处理字符串,可以快速、准确地完成复杂的查找、替换等处理要求。
- Python中,re模块提供了正则表达式操作所需要的功能。


最简单的正则表达式是普通字符串,可以匹配自身
'[pjc]ython'可以匹配'python'、'jython'、'cython'
'[a-zA-Z0-9]'可以匹配一个任意大小写字母或数字
'[^abc]'可以一个匹配任意除'a'、'b'、'c'之外的字符
'python|perl'或'p(ython|erl)'都可以匹配'python'或'perl'
子模式后面加上问号表示可选。r'(http://)?(www\.)?python\.org'只能匹配'http://www.python.org'、'http://python.org'、'www.python.org'和'python.org'
'^http'只能匹配所有以'http'开头的字符串
(pattern)*:允许模式重复0次或多次
(pattern)+:允许模式重复1次或多次
(pattern){m,n}:允许模式重复m~n次
'(a|b)*c':匹配多个(包含0个)a或b,后面紧跟一个字母c。
'ab{1,}':等价于'ab+',匹配以字母a开头后面带1个至多个字母b的字符串。
'^[a-zA-Z]{1}([a-zA-Z0-9._]){4,19}$':匹配长度为5-20的字符串,必须以字母开头、可带数字、“_”、“.”的字串。
'^(\w){6,20}$':匹配长度为6-20的字符串,可以包含字母、数字、下划线。
'^\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}$':检查给定字符串是否为合法IP地址。
'^(13[4-9]\d{8})|(15[01289]\d{8})$':检查给定字符串是否为移动手机号码。
'^[a-zA-Z]+$':检查给定字符串是否只包含英文字母大小写。
'^\w+@(\w+\.)+\w+$':检查给定字符串是否为合法电子邮件地址。
'^(\-)?\d+(\.\d{1,2})?$':检查给定字符串是否为最多带有2位小数的正数或负数。
'[\u4e00-\u9fa5]':匹配给定字符串中所有汉字。
'^\d{18}|\d{15}$':检查给定字符串是否为合法身份证格式。
'\d{4}-\d{1,2}-\d{1,2}':匹配指定格式的日期,例如2016-1-31。
'^(?=.*[a-z])(?=.*[A-Z])(?=.*\d)(?=.*[,._]).{8,}$':检查给定字符串是否为强密码,必须同时包含英语字母大写字母、英文小写字母、数字或特殊符号(如英文逗号、英文句号、下划线),并且长度必须至少8位。
"(?!.*[\'\"\/;=%?]).+":如果给定字符串中包含’、”、/、;、=、%、?则匹配失败。
'(.)\\1+':匹配任意字符的一次或多次重复出现。
'((?P\b\w+\b)\s+(?P=f))' :匹配连续出现两次的单词。
'((?P.)(?P=f)(?P.)(?P=g))' :匹配AABB形式的成语或字母组合。
re模块主要方法
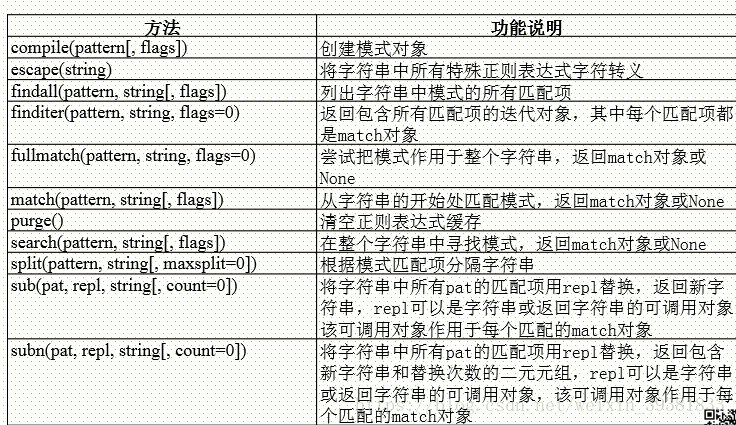
>>> import re #导入re模块
>>> text = 'alpha. beta....gamma delta' #测试用的字符串
>>> re.split('[\. ]+', text) #使用指定字符作为分隔符进行分隔
['alpha', 'beta', 'gamma', 'delta']
>>> re.split('[\. ]+', text, maxsplit=2) #最多分隔2次
['alpha', 'beta', 'gamma delta']
>>> re.split('[\. ]+', text, maxsplit=1) #最多分隔1次
['alpha', 'beta....gamma delta']
>>> pat = '[a-zA-Z]+'
>>> re.findall(pat, text) #查找所有单词
['alpha', 'beta', 'gamma', 'delta']
...
...
>>> pat = '{name}'
>>> text = 'Dear {name}...'
>>> re.sub(pat, 'Mr.Dong', text) #字符串替换
'Dear Mr.Dong...'
>>> s = 'a s d'
>>> re.sub('a|s|d', 'good', s) #字符串替换
'good good good'
>>> s = "It's a very good good idea"
>>> re.sub(r'(\b\w+) \1', r'\1', s) #处理连续的重复单词
"It's a very good idea"
>>> re.sub('a', lambda x:x.group(0).upper(), 'aaa abc abde')
#repl为可调用对象
'AAA Abc Abde'
>>> re.sub('[a-z]', lambda x:x.group(0).upper(), 'aaa abc abde')
'AAA ABC ABDE'
>>> re.sub('[a-zA-z]', lambda x:chr(ord(x.group(0))^32), 'aaa aBc abde')
#英文字母大小写互换
'AAA AbC ABDE'
>>> re.subn('a', 'dfg', 'aaa abc abde') #返回新字符串和替换次数
('dfgdfgdfg dfgbc dfgbde', 5)
>>> re.sub('a', 'dfg', 'aaa abc abde')
'dfgdfgdfg dfgbc dfgbde'
>>> re.escape('http://www.python.org') #字符串转义
'http\\:\\/\\/www\\.python\\.org'
>>> example = 'Beautiful is better than ugly.'
>>> re.findall('\\bb.+?\\b', example) #以字母b开头的完整单词
#此处问号?表示非贪心模式
['better']
>>> re.findall('\\bb.+\\b', example) #贪心模式的匹配结果
['better than ugly']
>>> re.findall('\\bb\w*\\b', example)
['better']
>>> re.findall('\\Bh.+?\\b', example) #不以h开头且含有h字母的单词剩余部分
['han']
>>> re.findall('\\b\w.+?\\b', example) #所有单词
['Beautiful', 'is', 'better', 'than', 'ugly']
>>> re.findall('\d+\.\d+\.\d+', 'Python 2.7.13')
#查找并返回x.x.x形式的数字
['2.7.13']
>>> re.findall('\d+\.\d+\.\d+', 'Python 2.7.13,Python 3.6.0')
['2.7.13', '3.6.0']
>>> s = 'This is head.This is body.'
>>> pattern = r'(.+)(.+)'
>>> result = re.search(pattern, s)
>>> result.group(1) #第一个子模式
'This is head.'
>>> result.group(2) #第二个子模式
'This is body.'
match()、search()、findall()
match(string[, pos[, endpos]])方法在字符串开头或指定位置进行搜索,模式必须出现在字符串开头或指定位置;
search(string[, pos[, endpos]])方法在整个字符串或指定范围中进行搜索;
findall(string[, pos[, endpos]])方法字符串中查找所有符合正则表达式的字符串并以列表形式返回。
>>> import re
>>> example = 'ShanDong Institute of Business and Technology'
>>> pattern = re.compile(r'\bB\w+\b') #查找以B开头的单词
>>> pattern.findall(example) #使用正则表达式对象的findall()方法
['Business']
>>> pattern = re.compile(r'\w+g\b') #查找以字母g结尾的单词
>>> pattern.findall(example)
['ShanDong']
>>> pattern = re.compile(r'\b[a-zA-Z]{3}\b') #查找3个字母长的单词
>>> pattern.findall(example)
['and']
>>> pattern.match(example) #从字符串开头开始匹配,失败返回空值
>>> pattern.search(example) #在整个字符串中搜索,成功
<_sre.SRE_Match object; span=(31, 34), match='and'>
>>> pattern = re.compile(r'\b\w*a\w*\b') #查找所有含有字母a的单词
>>> pattern.findall(example)
['ShanDong', 'and']
>>> text = "He was carefully disguised but captured quickly by police."
>>> re.findall(r"\w+ly", text) #查找所有以字母组合ly结尾的单词
['carefully', 'quickly']
sub()、subn()
正则表达式对象的sub(repl, string[, count = 0])和subn(repl, string[, count = 0])方法用来实现字符串替换功能,其中参数repl可以为字符串或返回字符串的可调用对象。
>>> example = '''Beautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex.
Complex is better than complicated.
Flat is better than nested.
Sparse is better than dense.
Readability counts.'''
>>> pattern = re.compile(r'\bb\w*\b', re.I) #匹配以b或B开头的单词
>>> print(pattern.sub('*', example)) #将符合条件的单词替换为*
* is * than ugly.
Explicit is * than implicit.
Simple is * than complex.
Complex is * than complicated.
Flat is * than nested.
Sparse is * than dense.
Readability counts.
>>> pattern = re.compile(r'\bb\w*\b', re.I) #匹配以b或B开头的单词
>>> print(pattern.sub('*', example)) #将符合条件的单词替换为*
* is * than ugly.
Explicit is * than implicit.
Simple is * than complex.
Complex is * than complicated.
Flat is * than nested.
Sparse is * than dense.
Readability counts.
>>> print(pattern.sub(lambda x: x.group(0).upper(), example))
#把所有匹配项都改为大写
BEAUTIFUL is BETTER than ugly.
Explicit is BETTER than implicit.
Simple is BETTER than complex.
Complex is BETTER than complicated.
Flat is BETTER than nested.
Sparse is BETTER than dense.
Readability counts.
正则表达式对象的split(string[, maxsplit = 0])方法用来实现字符串分隔。
>>> example = r'one,two,three.four/five\six?seven[eight]nine|ten'
>>> pattern = re.compile(r'[,./\\?[\]\|]') #指定多个可能的分隔符
>>> pattern.split(example)
['one', 'two', 'three', 'four', 'five', 'six', 'seven', 'eight', 'nine', 'ten']
>>> example = r'one1two2three3four4five5six6seven7eight8nine9ten'
>>> pattern = re.compile(r'\d+') #使用数字作为分隔符
>>> pattern.split(example)
['one', 'two', 'three', 'four', 'five', 'six', 'seven', 'eight', 'nine', 'ten']
>>> example = r'one two three four,five.six.seven,eight,nine9ten'
>>> pattern = re.compile(r'[\s,.\d]+') #允许分隔符重复
>>> pattern.split(example)
['one', 'two', 'three', 'four', 'five', 'six', 'seven', 'eight', 'nine', 'ten']
使用()表示一个子模式,即()内的内容作为一个整体出现,例如’(red)+’可以匹配’redred’、’redredred‘等多个重复’red’的情况。
>>> telNumber = '''Suppose my Phone No. is 0535-1234567,
yours is 010-12345678, his is 025-87654321.'''
>>> pattern = re.compile(r'(\d{3,4})-(\d{7,8})')
>>> pattern.findall(telNumber)
[('0535', '1234567'), ('010', '12345678'), ('025', '87654321')]
正则表达式对象的match方法和search方法匹配成功后返回match对象。match对象的主要方法有:
group():返回匹配的一个或多个子模式内容
groups():返回一个包含匹配的所有子模式内容的元组
groupdict():返回包含匹配的所有命名子模式内容的字典
start():返回指定子模式内容的起始位置
end():返回指定子模式内容的结束位置的前一个位置
span():返回一个包含指定子模式内容起始位置和结束位置前一个位置的元组。