Python3 ---编码问题(一)
目录
1、编码样式
2、python3 字节字符串和文本字符串
2.1、字节字符串和文本字符串的定义:
2.2关于编辑器的默认编码
3、总结
3.1、encode和decode的使用
3.2、什么时候用gbk\utf-8\unicode???
3.3 如何解决乱码的问题???
3.4、utf-8、utf-32、utf-64编码的区别???
3.5、如果文件中出现:'\ufeff\nprint',怎么处理
1、编码样式
- ASCII编码:美国标准代码,将各种东西(英文字母,数字,标点,字符)换成计算机识别的二进制数,一共265个字符,不支持汉字
- Unicode:全球所有字符的编码,但是没有规定的保存方式,65----》A
- ANSI:一般跟系统语言有关系
- GBK编码:汉字编码,进行了扩展,包含生僻字,存储编码
- GB2312:汉字处理,比较少,存储编码
- UTF-8:表示把unicode编码存储的时候,把一个汉字或者其他字符,保存为3个字节
- 完全兼容ascii码的256个字符;
- UTF-32:保存为4个字节,很占内存
2、python3 字节字符串和文本字符串
2.1、字节字符串和文本字符串的定义:
字节字符串(bytes):二进制数据用bytes表示,bytes表示的是一堆的比特位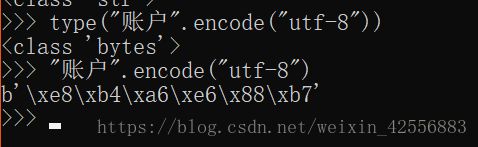
文本字符串(str):文本用unicode表示
2、文本字符串和字节字符串的转换
str(文本)-----(encode)------bytes(字节)
bytes(字节)----(decode)-----str(文本)
3、在Python3中,输入的中文,type显示是str类型,实际上默认是为unicode类型
它相当于在Python2中输入的u“中国”,因此在Python3中文本是没有decode属性
2.2关于编辑器的默认编码
1、在dos下,默认编码为“gbk”
在dos下,输入的代码如果是gbk或者是unicode编码,都能够准确的识别出来
2、在pycharm或者文本文件中,可以默认为编码为utf-8模式,如果需要将中文显示出来,可以为unicode或者utf-8模式
py2中输出中文的三部曲:
1、代码开头输入:#coding=utf-8
2、文件保存为utf-8编码格式,在文件中的中文字符串需要使用u,转换成unicode类型
3、特殊例子:raw_input("请输入一句话".decode("utf-8").encode("gbk")),因为dos环境默认是gbk环境,所以gbk下可以识别出来

py3 中输出中文2部曲:
1、代码开头:#coding=utf-8
2、文件保存为utf-8编码格式,在文件中的中文直接输入就可以

3、总结
3.1、encode和decode的使用
python3中:
s="中国", # unicode类型,可以用于计算机内存中,不用于文件存储和网络传输中
s=s.encode("utf-8") # 编程了bytes类型,可以用于文件存储和网络传输
s=s.decode("utf-8") #encode的编码是什么,就用什么编码decode
unicode(str类型)----》encode----》bytes类型
bytes类型----》decode----》unicode(str类型)
原则:用什么编码保存的,就用什么编码去解码
3.2、什么时候用gbk\utf-8\unicode???
答案:
如果传输或者存储的内容都是中文和英文,那么gbk或者utf-8都可以
如果传输或者存储的内容不全是中文和英文,还有日文、韩文等其他文件,则必须使用utf-8
bytes字符串用的地方2个地方用
1、写文件的时候(python帮你封装了,你直接设定encoding参数,自动帮你encode了)
2、在网络上,2台服务器(客户端和服务器)互相传输数据的时候
#encoding=utf-8 第一行一般都写这个
3.3 如何解决乱码的问题???
解决py文件中文乱码的问题:
1)把程序文件,都保存为utf-8编码格式
2)程序文件头不声明编码,或者是声明:#coding=utf-8
3.4、utf-8、utf-32、utf-64编码的区别???
答案:
unicode 是编码字符集,而utf-8、utf-16、utf-32是字符集编码
比如“汉字”中“汉”,在unicode值为0x6C49,因为计算器内部存储的形式都是二进制字符串,所以该汉字“汉”的unicode的编码转换
为二进制为:1101100 01001001,但是计算机怎么保存这个汉字“汉”,这取决于用到的字符集编码是那种
- utf-8:utf-8是用1-4个字节来保存unicode编码的字符,它是一个变长的。
- utf-16:utf-16只能是选2字节或者4字节来保存字符
- utf-32:所有的字符都用32bit也就是4个字节来表示,固定长度,虽然浪费了空间,但是提高了效率
3.5、如果文件中出现:'\ufeff\nprint',怎么处理
答案:
1)如果出现该现象,其实是没有什么问题的,可以在Notpaid中编码中选取:utf-8无bom编码可以
2)如果是常规的text文件,发现第一行中有\ufeff 解决的办法就是用.encode("utf-8").decode("utf-8-sig")
参考资料为:
https://blog.csdn.net/founderznd/article/details/52197078
示例:
>>> fp=open("e:\\b.txt","r",encoding="utf-8")
>>> fp.close()
>>> fp=open("e:\\b.txt","r",encoding="utf-8")
>>> s=fp.read()
>>> u=s.encode("utf-8").decode("utf-8-sig")
>>> u
'百日 \ndwe\nd332323'
>>>