4. 执行计划 explain 详解
说明
使用 Explain 关键字可以模拟优化器执行 SQL 查询语句,从而知道 MySQL 是如何处理你的 SQL 语句的,分析你的查询语句或者表结构的性能瓶颈
查看执行计划
-- 在 sql 前增加 EXPLAIN 关键字就可以查看执行计划
EXPLAIN SELECT * FROM test
![]()
执行计划存在以下列:
id:执行优先级,数字越大,越先执行
select_type:查询类型,比如普通、联合、子查询
table:这行统计信息是哪张张表的
type:访问类型的排列
possible_keys:显示应用这种表的索引,但是不一定使用到
key:此处执行使用到的索引
key_len:索引的长度,越短越好
ref:使用到这个索引的值,可能是:const、某个表的列
rows:扫描出的行数(估算的行数)
Extra:执行情况的描述和说明
其中上面五个比较重要
每列细讲
示例SQL
CREATE TABLE teacher
(
t_id INT NOT NULL PRIMARY KEY,
t_name VARCHAR(30),
t1 INT, -- 这3个列模拟复合组件
t2 VARCHAR(30),
t3 INT
);
ALTER TABLE teacher ADD UNIQUE (t_name);
CREATE INDEX inx_student_jihe ON teacher( t1,t2,t3 );
INSERT INTO teacher VALUES ( 1, '老王', 1, '1', 1 );
INSERT INTO teacher VALUES ( 2, '老李', 2, '2', 2 );
CREATE TABLE student
(
s_id INT NOT NULL PRIMARY KEY,
s_name VARCHAR(30),
s_t_id INT
);
CREATE INDEX inx_student_s_t_id ON student( s_t_id );
INSERT INTO student VALUES ( 1, '小学生', 1 );
id
执行优先级,数字越大,越先执行
ID 相同,执行顺序由上至下
ID 不同,ID值越大优先级越高,越先被执行。
EXPLAIN
SELECT *
FROM (SELECT * FROM teacher WHERE t_id = 1 ) tmp
INNER JOIN student ON ( t_id = s_t_id )
如果执行计划如上,会先执行第3行(因为2是里面最大的),然后剩下的都是1,那就顺序执行:1行 > 2 行
select_type
查询类型,主要用于区别 普通查询、联合查询、子查询等复杂查询
1) SIMPLE:简单的 select 查询,查询中不包含子查询或者union
EXPLAIN SELECT * FROM teacher WHERE t_id = 1
![]()
2.)PRIMARY:查询中如果包含了子查询,在子查询最外面的部分就会标记为 PRIMARY
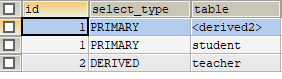
一层子查询
EXPLAIN SELECT * FROM (SELECT * FROM teacher WHERE t_id = 1 ) tmp

二层子查询
EXPLAIN
SELECT *
FROM (
SELECT * FROM teacher
WHERE t_id IN ( SELECT s_t_id FROM student )
) tmp

可以看出最外层的是 PRIMARY 类型
3)SUBQUERY
表示子查询,在 select 或 where 中包含了子查询
EXPLAIN
SELECT * FROM teacher
WHERE t_id = ( SELECT s_t_id FROM student WHERE s_id = 1 )

4)DERIVED
在 from 列表中包含了子查询,子查询会被标记为 DERIVED(衍生),MySQL 会递归执行这些子查询,把结果放在临时表
EXPLAIN
SELECT *
FROM (SELECT * FROM teacher WHERE t_id = 1 ) tmp

5)UNION
若第二个 select 出现在 union 后,则被标记为 union;若 union 包含在 from 自居的子查询中,外层将被标记为 DERIVED
普通 union
EXPLAIN
SELECT * FROM teacher WHERE t_id = 1
UNION
SELECT * FROM teacher WHERE t_id = 2

union 在子查询中
EXPLAIN
SELECT * FROM (
SELECT * FROM teacher WHERE t_id = 1
UNION
SELECT * FROM teacher WHERE t_id = 2
) tmp

6)UNION RESULT
从 union 表中获取结果的 select
EXPLAIN
SELECT * FROM teacher WHERE t_id = 1
UNION
SELECT * FROM teacher WHERE t_id = 2
id为 null 最后执行

table
现在这一行的数据是关于那一张表名称,也可以是虚拟的
type
显示使用了那种查询类型,一下从最好到最差依次是:
system > const > eq_ref > ref > range > index > all
1)system
表中只有一条数据,这个没啥意义,那会有一条数据的表,也就 mysql 配置表,不用管
EXPLAIN
SELECT * FROM (
SELECT * FROM student WHERE s_id = 1
) tmp

2)const
使用常量直接搜索主键 或 唯一索引,只会获取到一条数据
EXPLAIN
SELECT * FROM student WHERE s_id = 1
![]()
3)eq_ref
使用唯一索引扫描后,只会有一条数据与之匹配。就是 A、B 联表后,使用唯一索引联合,然后只有一条数据。
(省略)
4)ref
就是一对多,使用某个索引查询时候一个值会对应多个行,首先肯定一点就是这个列不会是唯一索引
INSERT INTO student VALUES ( 2, ‘又个小学生’, 1 );
EXPLAIN
SELECT * FROM student WHERE s_t_id = 1
![]()
5)range
就是区间查询,在 where 中使用了 <、>、in、between
EXPLAIN
SELECT * FROM teacher WHERE t_id > 0
![]()
6)index
全索引扫描
EXPLAIN
SELECT t_id FROM teacher
![]()
7) all
全表扫描
EXPLAIN
SELECT * FROM teacher
![]()
possible_keys
查询时候列出设计到这个字段上的索引,但是并不一定实际用到。
key
实际使用到的索引,如果为 NULL,表示此次查询没有使用到索引。覆盖索引就是你查的列和存在你创建符合索引时候的指定的列
EXPLAIN
SELECT * FROM teacher
WHERE t1 = 1 AND t2 = '1'
![]()
key_len
表示索引中使用过的字节数,可通过该列计算查询中使用的索引长度,在不精确性的情况下,长度越短越好。显示的长度并非实际长度。
ref
显示索引被哪一个列使用了,也可以是一个常量。
常量:
EXPLAIN
SELECT * FROM teacher
WHERE t_id = 1
![]()
某个列:
这里不使用上面的示例表查询的,看出在是:数据库.表名.列名,在使用 IX_aeApplication_app_itm_id 这个索引

rows
mysql认为需要比较多少行去执行这个查询,这个值是估值并不精确。
Extra
Extra列包含有关MySQL如何解析查询的附加信息。前三个指标比较重要要理解,后面的认识下就行
1)Using filesort
在查询时候使用的执行计划中了索引,但是排序时候,出现某种原因,没有使用这个索引排序,Mysql自己给数据排序了,出现这种情况,很危险,会拖慢性能。
以下就没有使用自己定义的 t3 去使用索引排序,这是因为创建复合索引时候是:t1,t2,t3,这里查询了 t1 然后直接使用 t3 排序。中间的 t2 没用上,也就是没有按索引的顺序,中间出现了断层,所以索引排序时候失效了。下面的 Using temporary 出现也是因为这个
EXPLAIN
SELECT * FROM teacher WHERE t1 = 1 ORDER BY t3
使用以下避免
EXPLAIN
SELECT * FROM teacher WHERE t1 = 1 ORDER BY t2
或
EXPLAIN
SELECT * FROM teacher WHERE t1 = 1 ORDER BY t2, t3
![]()
2)Using temporary
在排序时候使用了临时表保存中间结果,对性能十分致命,因为临时表创建后需要将数据搬到临时表,用完再去删除。出现原因在 Using filesort 中说明了。
EXPLAIN
SELECT * FROM teacher WHERE t1 = 1 GROUP BY t3
![]()
解决
EXPLAIN
SELECT * FROM teacher WHERE t1 = 1 GROUP BY t2
或
EXPLAIN
SELECT * FROM teacher WHERE t1 = 1 GROUP BY t2, t3
3)Using index
表示响应的 select 操作中使用了覆盖索引,避免访问了表的数据行,效率不错。
如果同时出现 using where,表明索引被用来执行索引键值的朝招
如果没有同时出现using where,表明索引永爱读取数据而非执行查找动作。
覆盖索引:简单说就是查询的列在聚合索引中
使用覆盖索引查询。如果要使用覆盖索引,一定要注意 select 列表中只取出需要的列
EXPLAIN
SELECT t1 FROM teacher WHERE t2 = '1'
或
EXPLAIN
SELECT t1, t2 FROM teacher
![]()
4)Using where
在查找使用索引的情况下,需要回表去查询所需的数据
5)Using join buffer
使用了连接缓存
6)impossible where
where 子句的值总是 false,不能用来获取任何元组。说白了就是条件写的是个废话,例如:
select * from user where name = 'laowang' and name = 'laoli'
7)select tabls optimized away
在没有 Grour By 子句的情况下,基于索引优化 MIN/MAX 操作或者 对应 MyISAM 存储引擎优化 count(*) 操作,不必等到执行阶段再进行计算,查询执行计划生成的阶段即完成优化。
8)distinct
优化 distinct 操作,在找到第一匹配的元组后即停止找到同样值的动作
9)using index condition
查找使用了索引,但是需要回表查询数据