本文仅为模型应用实战,而非颜值研究,所得结果仅供娱乐,仅供参考。
方法也仅供参考。
一般而言,数据量越大,结果越接近正常人审美。由于本次数据量较小,故仅为实验。
使用环境:ubuntu14.04,opencv3.2.0,dlib19.6,python2.7
一、准备工作:
1、下载dlib库,下载特征提取模型。
该模型的作用是通过卷积神经网络产生128维的特征向量,用以代表这张脸。网络输入参数为人脸landmark的68个特征点shape和整幅图像。可猜想网络特征与人脸的68特征点坐标有关,在网络中进行归一化并进一步处理,使得提出的特征具有独立、唯一性。
考虑到人脸的颜值与五官位置,拍照时的表情有关,故本网络可作为一种方案进行尝试。
Dlib下载:
http://dlib.net/
本模型原用于人脸识别,原型为CNN_ResNet。残差网络是为了减弱在训练过程中随着网络层数增加而带来的梯度弥散/爆炸的问题。该方法在LFW上进行人脸识别达到99.38%的准确率。
模型名称:dlib_face_recognition_resnet_model_v1,迭代次数为10000,训练时用了约300万的图片。输入层的图片尺寸是150。
下载地址:
提取特征的网络模型地址:
http://dlib.net/files/dlib_face_recognition_resnet_model_v1.dat.bz2
landmark 68特征点位置提取模型:
http://dlib.net/files/shape_predictor_5_face_landmarks.dat.bz2
2、数据准备:准备不同类型的脸部图像,注意选用颜值不同的照片,该部分具有一定的主观性,也是对最后评分影响最重要的一个环节,所以数据量应尽可能大,选用的图像尽可能典型。
我们设置6个分数,分别为:95,90,85,80,70,65
95分人数仅2人,其余分数在15人左右。85人最多,约20人。数据符合正态分布。
二、生成数据库。
将整理好的图片分别用文件夹包含好,每一个文件夹为一类颜值分数。在确保能够检测到脸的情况下,将每张图片送入网络提取特征,同时为其加入标签,表示颜值所属类别,为后续测试分类做好准备。
这样每张图就都已经生成了其对应的128个值和一个标签。
三、基于最邻近匹配的分数估计(类似KNN)
数据形式如下表所示:
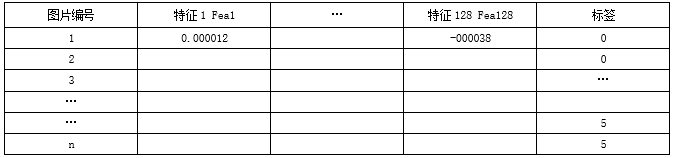
新的测试图片进入网络同样得到128个值:

定义两种衡量接近度的尺度(方式):
(1)欧氏距离:
(2)基于线性组合系数的接近度表示:
我们将表1的数据矩阵进行转置,得到如下表所示的矩阵:
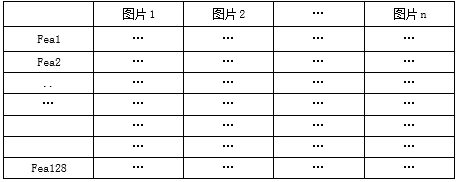
将以上矩阵设为A,测试图片所形成的特征列向量为b。
A为128*n维,x为n维,b为128维。
则求得的x为b向量在A向量中每个列向量所具有的分量。即把测试图片的特征看作原有数据集中每个图片特征的线性组合。其系数越大的,则我们认为该系数所对应的数据库中的图片越接近测试图片。
分别找到欧式距离最近的3个、线性组合中系数最大的三个,将这三个分别进行加权处理。
对欧式距离最接近的三张,我们找到对应的原数据(分数值),我们暂认为三者概率近似,以1:1:1的形式加权求和(这三张中可能有多张属于同一颜值类别)。
对于使用线性组合方法的,取到这三张对应的而后使用权重的方法。
最后将2种方法结合,我们认为第二种方案更可信,以0.6权重加权,第一种方案,以0.4权重加权。
取欧式距离的前5张,进行类别投票以检验分数,若投票结果类别对应的分数值与之前求得分数相差较大,则将本次投票结果以一定的比例折算进入总分,调整原有分数,以防误差过大。



四、拓展:加入性别识别
即准备男、女照片各约100张,应覆盖不同年龄段,在样本较少的情况下,(长得清秀的)男孩可能被误认为女生。
分别打上标签:0-女生,1-男生。
基于投票的分类,分别求测试图与数据库中特征值距离的欧式距离、余弦距离,取与特征距离最近的10张,找到对应的原图所属性别,进行投票,多于半数(即大于10张)认为其为该性别。
数据结果如下:
欧式距离最近10张图片的性别结果:[1,1,0,0,1,1,1,1,1,1]
余弦距离最近10张图片的性别结果:[1,1,1,0,0,1,1,1,1,1]
结果为:男性,置信度confidence=8*2/20=0.8
置信度表示本次结果的可信度,或根据先验知识,求预测类别的概率。
基于投票的方案准确率较高。

【注】测试和训练图片均源于网络。
还可以采用基于SVM的分类,关键代码:
clf=svm.SVC(C=1, kernel='rbf', gamma=1, decision_function_shape='ovr')
clf.fit(dataMat,np.uint8(labelMat))
face_descriptor_trans=face_descriptor_trans.reshape(1,-1)
print(clf.decision_function(dataMat))
score=clf.predict(face_descriptor_trans)
但在问题颜值计算中,分类结果始终为第三类,原因暂未知。且第三类中图片数量略多于其他类别。
二分类问题有不错的表现。
此外邻近匹配法和分类思想也可用于表情识别等分类问题中。
---------------------------------关键代码-----------------------------------
欧氏距离与余弦距离计算
def euler_dist(vector1, vector2):
X = np.vstack([vector1, vector2])
dist = pdist(X)
return dist
def cos(vector1, vector2):
dot_product = 0.0;
normA = 0.0;
normB = 0.0;
for a, b in zip(vector1, vector2):
dot_product += a * b
normA += a ** 2
normB += b ** 2
if normA == 0.0 or normB == 0.0:
return None
else:
return dot_product / ((normA * normB) ** 0.5)
矩阵转换为列表,可用index进行索引:dist1 = list(dist)
对原dist进行排序操作 找到距离最近的索引号new_dist1 = sorted(dist)
score_1[j]=labelMat[np.uint8(loca_dist1[j])]
反查出对应的标签是哪一类。
for i in range(0,num_select):
record_times[np.uint8(score_1[i])]=record_times[np.uint8(score_1[i])]+1
进行投票表决。
得分加权:
final_score=score[np.uint8(score_1[0])]0.333+score[np.uint8(score_1[1])]0.333+score[np.uint8(score_1[2])]*0.333