Python爬取URP教务系统课程表并保存到excel
Python爬取URP教务系统课程表并保存到excel
爬取URP教务系统课程表最终结果如图所示:

接下来开始操作:
首先打开教务系统->按F12->点击Network->刷新一下界面->获取headers 如图所示:

headers={
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3',
'Connection': 'Keep-Alive',
'Accept-Language': 'zh-CN,zh;q=0.9',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.87 Safari/537.36',
'Accept-Encoding': 'gzip, deflate',
'Upgrade-Insecure-Requests':'1',
'Cookie':'*******',
'X-Requested-With': 'XMLHttpRequest',
'Host': '202.207.177.39:8088'
}
接下来抓包Form表单,先输入祖传密码获取表单信息:
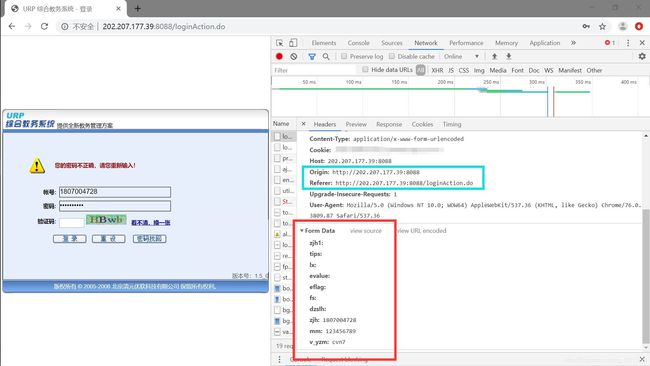
把Origin和Referer也添加到headers里面去。
可以看到最后三个分别是账号,密码,验证码(emmm…不过在这里真的想吐槽一下这URP,,,,账号=zjh(我猜是证件号),密码=mm,验证码,,,哎不说了)
写出from表单:
form = {
'zjh1': '',
'tips': '',
'lx': '',
'evalue': '',
'eflag': '',
'fs': '',
'dzslh': '',
'zjh': username,
'mm': password,
'v_yzm': code
}
此时我们就可以着手获取验证码了:
Elements 找到验证码的链接:
但是别急,我们在去Response里面看看: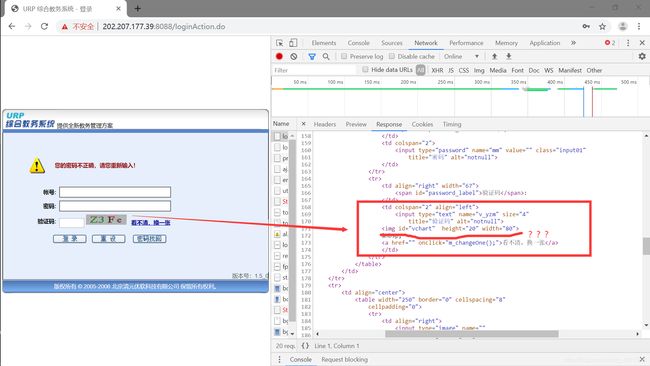
发现此处并没有验证码图片的链接。因为是js动态加载出来的。
所以我们不能用常规的获取网页源码的方式获取到验证码的链接,我在这里用了一种笨办法但也是最简单的办法:用selenium模拟登录去获取网页源码:
selenium安装:
pip install selenium
这里还需要用到ChromeDriver(因为我用的Chrome浏览器模拟登录):
打开Chrome浏览器->最右上角->帮助->关于Google Chrome->查看当前浏览器版本:

然后去这里下载对应的版本。(如果没有对应的,相近的也行)
此时这里的html就是selenium获取到网页源码:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
browser=webdriver.Chrome()
html=browser.page_source
# browser.close()
此时获取到的源码是带验证码链接的
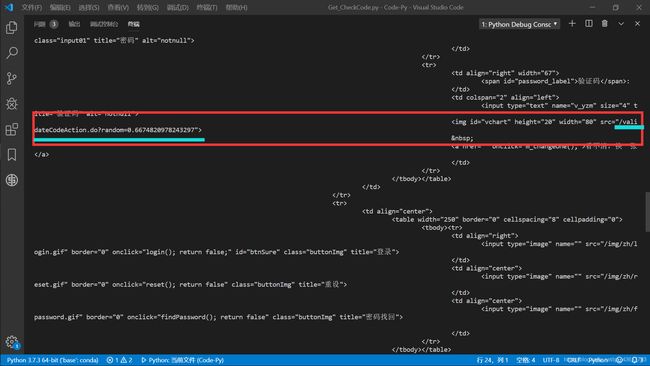
然后用正则将验证码链接提取出来和前面拼上:
def CheckCode(url):
browser.get(url)
html=browser.page_source
# browser.close()
yzm_src=re.findall(') ',html)
yzm_url=str(yzm_src)
yzm_url=''.join(yzm_src)
yzm_url='http://202.207.177.39:8088'+str(yzm_url)
return yzm_url
',html)
yzm_url=str(yzm_src)
yzm_url=''.join(yzm_src)
yzm_url='http://202.207.177.39:8088'+str(yzm_url)
return yzm_url
这样我们就获得了完整的验证码链接(即下文的img_url)
接下来就是验证码的识别了:
首先
pip install pytesseract
(这里不用tesseract是因为我一直安装不上,百度了好多教程也不行,后来搜到python和tesseract不兼容什么的…)
def get_image_text(img_url):
img_url=urllib.request.Request(url=img_url,headers=headers)
downloads=urllib.request.urlopen(img_url).read()
localtime = time.strftime("%Y%m%d%H%M%S",time.localtime())
filename='C:/Code-Py/CAPTCHA/'+localtime+'.jpg' #将验证码图片保存到本地
local=open(filename,'wb')
local.write(downloads)
local.close()
# img.show()
response=filename
img=Image.open(response)
img=img.convert('L')
img=img.point(lambda x:255 if x>135 else 0) #灰度处理
text=pytesseract.image_to_string(img)
return (text)
得到结果:

还行。
但是这个东西吧…其实有的时候也不是那么准,所以我们也可以人工识别去输入验证码(就那个img.show(),我注释了)。
好,准备的差不多了,登进去看看:
嗯,主页又是啥也没。
直接打开课表再看看:(这里我以18070047班为例)

嗯,有东西,url也不一样了。
再看看url:
http://202.207.177.39:8088/bjKbInfoAction.do?oper=bjkb_xx&xzxjxjhh=2019-2020-1-1&xbjh=18070047&xbm=18070047&xzxjxjhm=2019-2020%D1%A7%C4%EA%C7%EF(%C1%BD%D1%A7%C6%DA)&
多看看几个url:
http://202.207.177.39:8088/bjKbInfoAction.do?oper=bjkb_xx&xzxjxjhh=2019-2020-1-1&xbjh=18070047&xbm=18070047&xzxjxjhm=2019-2020%D1%A7%C4%EA%C7%EF(%C1%BD%D1%A7%C6%DA)&
http://202.207.177.39:8088/bjKbInfoAction.do?oper=bjkb_xx&xzxjxjhh=2019-2020-1-1&xbjh=18070046&xbm=18070046&xzxjxjhm=2019-2020%D1%A7%C4%EA%C7%EF(%C1%BD%D1%A7%C6%DA)&
http://202.207.177.39:8088/bjKbInfoAction.do?oper=bjkb_xx&xzxjxjhh=2019-2020-1-1&xbjh=18070045&xbm=18070045&xzxjxjhm=2019-2020%D1%A7%C4%EA%C7%EF(%C1%BD%D1%A7%C6%DA)&
区别一目了然了哈。
因为你直接去上课表的url也是需要登陆的,所以我们可以直接在这里用Chrome去模拟登录这种url:(这一下子就简单了N点点 QAQ)
url_head='http://202.207.177.39:8088/bjKbInfoAction.do?oper=bjkb_xx&xzxjxjhh=2019-2020-1-1'
url_tail='&xzxjxjhm=2019-2020%D1%A7%C4%EA%C7%EF(%C1%BD%D1%A7%C6%DA)&'
number=input()
url=url_head + '&xbjh=' + str(number) + '&xbm=' + str(number) + url_tail
这里我只是输入班级号,从上面url也可以看出来,还可以弄学年春秋什么的,你们可以自己弄,方法差不多。
爬之前先检查登陆是否成功:
def download(url):
username='*******'
password='*******'
#当然账号密码也可以手动输入
code_url=CheckCode(url)#验证码链接
code=get_image_text(str(code_url))#验证码识别
form = {
'zjh1': '',
'tips': '',
'lx': '',
'evalue': '',
'eflag': '',
'fs': '',
'dzslh': '',
'zjh': username,
'mm': password,
'v_yzm': code
}
urls=url
r=requests.post(url=urls,data=form,headers=headers)
r_html=r.text
r_text=re.findall('(.*?) ',r_html)
r_text=''.join(r_text)
if r_text =='班级课表信息':
print('登陆成功')
return r_html
else:
print("登陆失败,正在重试...")
time.sleep(3)
download(urls)
#递归,前几次失败可能是验证码识别的问题,但是如果次数多了可能就是cookie的问题了...
然后就可以愉快的爬课表了:
首先
pip install xlwt
因为我要将爬到的课表下载到excel里
详情可以参考这里
然后:
查看源码->用css选择器搜标签->正则匹配内容以及一系列处理
#excel表格样式
def set_style(name,height,bold=False):
style = xlwt.XFStyle()#初始化样式
font = xlwt.Font()#为样式创建字体
font.name = name
font.bold = bold
font.color_index = 4
font.height = height
style.font = font
return style
def get_timetable(number,html):
f = xlwt.Workbook()
sheet1 = f.add_sheet('学生',cell_overwrite_ok=True)
row0 = [ " ", " 星期一 ", " 星期二 "," 星期三 "," 星期四 "," 星期五 "," 星期六 "," 星期日 "]
for i in range(0,len(row0)):
sheet1.write(0,i,row0[i],set_style('Times New Roman',220,True))
soup=BeautifulSoup(html,'lxml')
for i in range(3,16):
if i==7 or i==12:
continue
tables=[]
for j in range(1,10):
table=soup.select('#user > thead > tr:nth-child({}) > td:nth-child({})'.format(i,j))
table=str(table)
r_table='(.*?)'
r_table=''.join(r_table)
table=re.findall(r_table,table,re.S)
table=''.join(table)
table=table.replace('\r','')
table=table.replace('\n','')
table=table.replace('\t','')
table=table.replace(' ','NULL')
table=table.replace('
','')
table=table.replace(' ','')
table=table.strip()
tables.append(table)
if i==3 or i==8 or i==13:
del tables[0]
for k in range(0,len(tables)):
sheet1.write(i-2,k,tables[k],set_style('Times New Roman',220,True))
name=str(number)+'.xls'
f.save(name)
print('下载完成,请到 %s 中查看'%name)
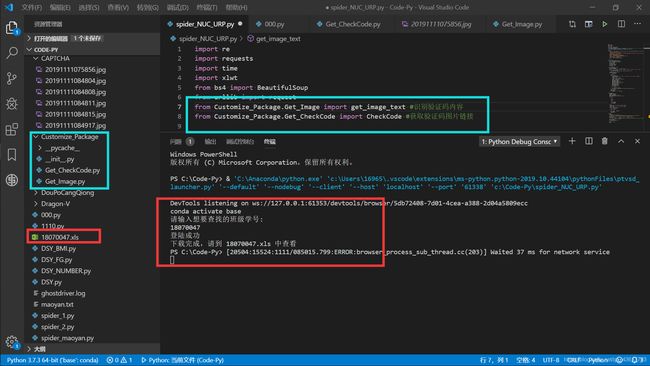
大功告成!
接下来上源码:
ps:我自定义了验证码识别和下载的模块(即上图的蓝框)(便于爬别的地方用,也便于修改维护)。
自定义模块的导入参考这里
下面是源码:
主程序:
import re
import requests
import time
import xlwt
from bs4 import BeautifulSoup
from urllib import request
from Customize_Package.Get_Image import get_image_text #识别验证码内容
from Customize_Package.Get_CheckCode import CheckCode #获取验证码图片链接
headers={
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3',
'Connection': 'Keep-Alive',
'Accept-Language': 'zh-CN,zh;q=0.9',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.87 Safari/537.36',
'Accept-Encoding': 'gzip, deflate',
'Upgrade-Insecure-Requests':'1',
'Cookie':'*******',
'Referer': 'http://202.207.177.39:8088/loginAction.do',
'X-Requested-With': 'XMLHttpRequest',
'Host': '202.207.177.39:8088',
'Origin': 'http://202.207.177.39:8088'
}
#excel表格样式
def set_style(name,height,bold=False):
style = xlwt.XFStyle()#初始化样式
font = xlwt.Font()#为样式创建字体
font.name = name
font.bold = bold
font.color_index = 4
font.height = height
style.font = font
return style
def get_timetable(number,html):
f = xlwt.Workbook()
sheet1 = f.add_sheet('学生',cell_overwrite_ok=True)
row0 = [ " ", " 星期一 ", " 星期二 "," 星期三 "," 星期四 "," 星期五 "," 星期六 "," 星期日 "]
for i in range(0,len(row0)):
sheet1.write(0,i,row0[i],set_style('Times New Roman',220,True))
soup=BeautifulSoup(html,'lxml')
for i in range(3,16):
if i==7 or i==12:
continue
tables=[]
for j in range(1,10):
table=soup.select('#user > thead > tr:nth-child({}) > td:nth-child({})'.format(i,j))
table=str(table)
r_table='(.*?)'
r_table=''.join(r_table)
table=re.findall(r_table,table,re.S)
table=''.join(table)
table=table.replace('\r','')
table=table.replace('\n','')
table=table.replace('\t','')
table=table.replace(' ','NULL')
table=table.replace('
','')
table=table.replace(' ','')
table=table.strip()
tables.append(table)
if i==3 or i==8 or i==13:
del tables[0]
for k in range(0,len(tables)):
sheet1.write(i-2,k,tables[k],set_style('Times New Roman',220,True))
# print(tables)
name=str(number)+'.xls'
f.save(name)
print('下载完成,请到 %s 中查看'%name)
def download(url):
username='*******'
password='*******'
code_url=CheckCode(url)#验证码链接
code=get_image_text(str(code_url))#验证码识别
form = {
'zjh1': '',
'tips': '',
'lx': '',
'evalue': '',
'eflag': '',
'fs': '',
'dzslh': '',
'zjh': username,
'mm': password,
'v_yzm': code
}
urls=url
r=requests.post(url=urls,data=form,headers=headers)
r_html=r.text
r_text=re.findall('(.*?) ',r_html)
r_text=''.join(r_text)
if r_text =='班级课表信息':
print('登陆成功')
return r_html
else:
print("登陆失败,正在重试...")
time.sleep(3)
download(urls)
def main():
print('请输入想要查找的班级学号:')
url_head='http://202.207.177.39:8088/bjKbInfoAction.do?oper=bjkb_xx&xzxjxjhh=2019-2020-1-1'
url_tail='&xzxjxjhm=2019-2020%D1%A7%C4%EA%C7%EF(%C1%BD%D1%A7%C6%DA)&'
number=input()
url=url_head + '&xbjh=' + str(number) + '&xbm=' + str(number) + url_tail
html=download(url)
get_timetable(number,html)
if __name__=='__main__':
main()
验证码识别模块:
'''
识别验证码内容
'''
import time
import pytesseract
from PIL import Image
import urllib.response
import urllib.request
from urllib import request
headers={
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3',
'Connection': 'Keep-Alive',
'Accept-Language': 'zh-CN,zh;q=0.9',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.87 Safari/537.36',
'Accept-Encoding': 'gzip, deflate',
'Upgrade-Insecure-Requests':'1',
'Cookie':'*******',
'Referer': 'http://202.207.177.39:8088/loginAction.do',
'X-Requested-With': 'XMLHttpRequest',
'Host': '202.207.177.39:8088'
}
def get_image_text(img_url):
img_url=urllib.request.Request(url=img_url,headers=headers)
downloads=urllib.request.urlopen(img_url).read()
localtime = time.strftime("%Y%m%d%H%M%S",time.localtime())
filename='你的验证码图片要下载的地址'+localtime+'.jpg'
local=open(filename,'wb')
local.write(downloads)
local.close()
# img.show()
response=filename
img=Image.open(response)
img=img.convert('L')
img=img.point(lambda x:255 if x>135 else 0)
text=pytesseract.image_to_string(img)
return (text)
验证码链接获取模块:
'''
获取验证码链接
'''
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
import re
browser=webdriver.Chrome()
def CheckCode(url):
browser.get(url)
html=browser.page_source
# browser.close()
yzm_src=re.findall('',html)
yzm_url=str(yzm_src)
yzm_url=''.join(yzm_src)
yzm_url='http://202.207.177.39:8088'+str(yzm_url)
return yzm_url
另:
爬取之前,建议先自己打开一遍教务系统网站,获取到cookies复制粘贴到这里来(因为我尝试过各种方法去自动获取cookie,但是服务器一直返回500,所以我屈服了…)
PS:傻萌新一个,写这篇文章只做学习探讨之用
PS_2:本人用的vscode,挺爽的~
PS_3:代码没经过各种测试,也没有什么异常处理,有什么修改意见可以在评论区提出来哈~
PS_4:第一次写博客哈,逻辑什么的可能不太清晰,见谅~