开源纯C#工控网关+组态软件(七)数据采集与归档
一、 引子
在当前自动化、信息化、智能化的时代背景下,数据的作用日渐凸显。而工业发展到如今,科技含量和自动化水平均显著提高,但对数据的采集、利用才开始起步。
对工业企业而言,数据采集日益受到重视,主要应用场景包括:
节能降耗。投入(如车间的水电气能耗、设备工时、原料耗用)和产出(产量、批数)这些成本核算的关键数据通过传感器采集,取代人工抄表已成为趋势。
绩效考评。投入、产出、损耗、工时数据,其对管理者的决策支持、对员工的绩效评估都很重要。
批次追溯。食品安全形势日益严峻,对物料的追溯也成为国家硬指标。追溯就是追根溯源,批次生产的每个环节都需要数据跟踪。
设备管理。如设备的运行时长对于设备保养、故障频率对于设备维护、设备参数对于工艺优化。
数据既然如此重要,对于SCADA不但必须有,而且高要求:
准确性。信号不能失真,采集精度和时间戳尽可能精确;也不能带入太多干扰和噪音。
完整性。信号不能频繁丢失、丢步、跳步,万一信号断开,要快速重连,或者有冗余机制。
大容量。大数据,首先要能撑的起这个“大”。大项目动辄几万点,采集频率又高,一天下来数据量都惊人,日积月累更是天量。例如对于 1万点的系统, 1秒钟存储一次,每次单点占用 8字节,保存 10年的数据量将有 10000*8*10*365*86400=25228800000000字节,也就是 23TGB。若用 80GB硬盘存放,需 293块硬盘。如此庞大的数据量,还要求快速插入、快速查询。
要实现这些指标,非常具有挑战性。
二、 实时库与历史库
概述
工控环境特殊性在于,大量测点快速变化,需高速存取, IO密集型;数据结构简单规则,无非就是名称/ID、值、时间戳这些;数据流式存储,只需在尾部插入,不删不改。
因此常规的关系数据库不仅存取速度跟不上,也显得杀鸡用牛刀。实时库和历史库就是为工业环境准备的,测点的实时数据存储在内存,保证最快的存取速度;数据超过一定范围需要转储入历史库,我这里用了自定义格式的二进制文件,力求数据单元空间占用最小化、同时查询速度最大化。
实时库
测点数据在内存中,包含【下位机映射缓存:ICache】→【快照数据集:TagList】→【历史数据缓存:HistoryList】这样的三级结构。
ICache是下位机当前数据的缓存,随扫描过程实时更新,继承IReaderWriter接口,可读可写,可以通过Tag的Read\Write读取和更新。
对当前所有测点数据的快照查询,可以通过Tag的清单列表MetaTagList结合神器Linq实现。Linq对内存列表数据的查询能力可以说既强大又优雅,这是微软送给C#码农的礼物,不再赘述。
测点数据改变就会生成一条新的记录。这些记录如马上转储到数据库或文件,则测点数量多变化快,其IO是系统不能承担之重。但如果测点记录堆积过多不及时清理,则一方面可靠性下降,如系统崩溃、断电就会发生大量数据点丢失,同时内存占用越来越大,影响系统性能。所以测点历史数据的缓存容量应可根据测点数量和存取频率自适应或由用户自定义。
历史库
海量的测点数据,普通关系数据库是难以招架的。如SQL SERVER免费版只有4-10个G上限。而这个容量可能一个月就溢出了。
因此,为了适应天量数据,就需要二进制文件存储。有人会问为啥不用NO SQL,Hadoop这些高大上的东东,我的观点是不追求高大上,因为工控数据不同于搜索引擎,都是简单而标准的结构。可以根据其特点进行有针对性的设计,无需部署复杂的NO SQL架构也一样可以实现高性能。
历史数据库要最大限度的压缩数据,同时又要保证快速插入、快速查询。
如何保证数据单元最小化?
分析存储结构,一条记录包括变量名、当前值、时间戳。
变量名可能为一个长字符串,数据量大之后显然是过于冗长。因此代之以ID号(2字节)。还可以进一步压缩,如相同变量存在一起,ID也可以省了。
当前值大部分是浮点数,4字节,这个不能缩减,否则影响数据精度。
时间戳为DateTime,要占8字节,但如果数据按日排序,日期部分省去,4个字节的时间部分就可以精确到毫秒。
这样,通过合理设计存储结构,一条记录可以压缩到8个字节(开关量5个字节)。
如何保证快速插入记录?
存档文件日积月累肯定是越来越庞大,如果采用覆盖式写入或更新写入,不仅可靠性下降,读写成本也越来越高。想快速插入必须保证每次写入不改变原来的数据,仅仅在末尾追加。
如何保证快速查询?
首先为保证可靠性和数据容量限制,数据分月存放。文件名为【年-月.bin】。如需跨月查询,按文件名搜索拼接即可。开头256个字节存放日期索引。32*8字节,对应每日记录的头指针,也即上一日记录的末尾。
主索引下,每一天的记录头为日内索引区。包含一个索引数组,每一项索引有变量ID、变量长度、数量。如要查某日某ID的变量,即可先找到ID,再根据其变量长度*数量累加计算,即可定位到该变量的第一条记录。
同一变量的记录按时间戳顺序排列。这样,要定位到该变量某一时间的记录,即可对时间戳采用二分法快速定位。
字符串类型的归档比较特殊,专门在EventLog作为日志存取。
三、 数据转储流程
为什么要建立三级转储
数据在什么情况下会被采集?默认是变化了采集。如果一个数据长期不变,但需要定期采样,可以设置归档周期:
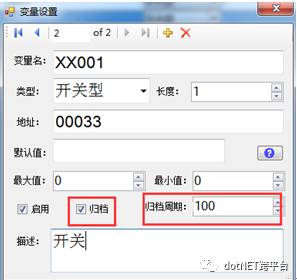
数据被采集之后首先是存在内存中。内存的特点是快,小。存取快,但是容量有限,采样数据堆积多了就要清理转储到关系数据库。
为什么要多一层关系数据库?因为采样的数据是时间序列的,但最终二进制文件的索引结构按照变量-时间戳排布,比如依次排入变量A-13:40,变量B-13:41,变量A-13:42这样一个时间序列,如直接写二进制存档文件就需按变量排序并重新整理写入,文件越大其写入效率越低,对系统拖累越大。而先转储到关系数据库,再定期将上一日的数据转储到二进制文件,既可以充分利用关系数据库的高性能批量插入功能(在SQL SERVER就是Sqlbulkcopy),又可利用关系库的查询排序能力,一举两得,转储之后数据库记录清空,也避免关系库容量溢出的问题。
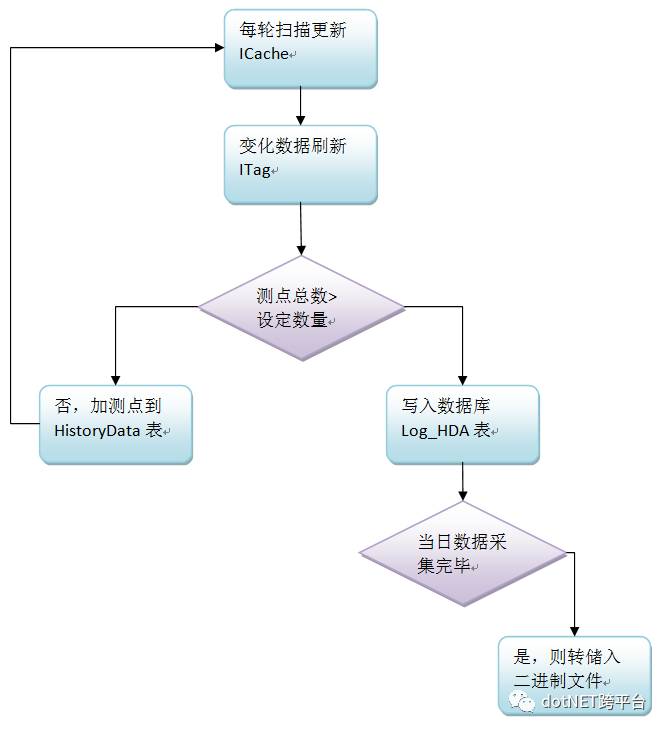
由上所述,转储包含【历史数据缓存:HistoryList】→【关系数据库:Log_HDA】→【二进制文件:bin文件】三级。
每转储成功一次,上一级的数据就清空,保证每一级之间的数据不重叠。
这样一来,数据记录就分布于三个位置:内存、关系库、二进制文件。要查询数据,就需要对这三部分数据进行“拼接”。拼接的规则就是以当前级最末一条记录的时间戳为准。如当前级中没有,就查下一级。
源头:内存数据库
内存数据库是一个HistoryData列表。有两种情况可以触发清理:定期清理、溢出清理。定期清理是设置固定的周期。溢出就是超过一定大小,到时间就转到关系库。可由server.xml配置。
中介:关系数据库
就是数据库的Log_HDA表。承上(内存)启下(二进制文件),暂存数据。也包含ID、值、时间戳这几个字段。每天凌晨开始,网关服务调用DataHelper内部的WriteToFile方法(实际是调用关系库的WRITEHDATA存储过程),对暂存的测点记录按时间、变量排序,转储到二进制文件中。如写入失败,判断最后一个时间戳,下一次继续追加写入,类似断点续传。
存储:二进制数据库
二进制存档文件按月存放,自带索引。所有对其操作均在DataHelper的HDAIOHelper 类中。包括从数据库写入、查询、定期转储、压缩归档(用旋转门算法)等。为提高读写性能,采用内存映射文件MemoryMappedFile。
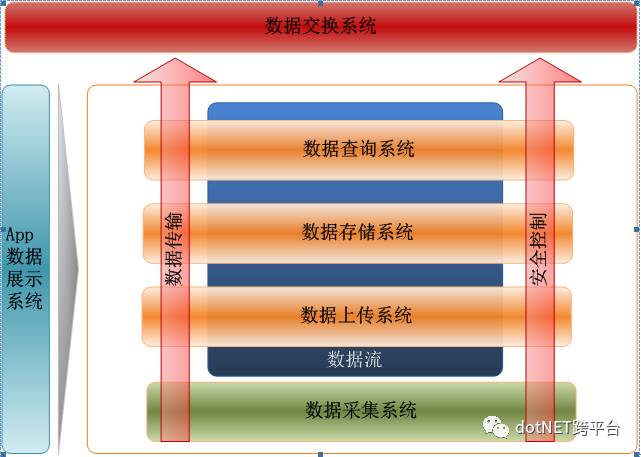
四、 应用场景
数据应用场景
数据的应用场景,主要是查询、显示、挖掘。查询→生成各种报表、图表,以供人工分析比较;显示→图形化展示,一目了然;挖掘→结合先进的挖掘工具,找出数据内在关联性,提供决策支持。
数据查询
目前支持的查询场景包括:按时间段检索、按变量ID检索、获取某变量在一段时间内的平均值/最大值/最小值/初始值/当前值。如要对一段记录执行复杂查询(如按时间间隔分组等),需要取出该时间段内所有记录,用Linq查询。
数据显示
目前支持实时数据显示和历史数据趋势图。我这里用了一套微软俄罗斯研究院的DynamicDataDisplay开源组件,性能不错,很适合动态图显示,目前还发展出了javascript版本。

数据报表
利用微软的RDLC报表和Chart图表的强大功能,可以方便的设计出各种复杂报表、图表。顺带赞一下RDLC,集成于Visual Studio和SQL SERVER,可以在Web显示,支持内嵌表格、仪表、图表、钻取报表,还可以方便的导出为Excel、Pdf、Word,与.NET 完美集成,强烈推荐。
未来改进
分布式:对一个大系统,分布式是必须的。即数据分别在不同节点采集、存储,但形式上依然是一个整体,可以统一查询和传输。
内存映像:目前的测点缓存模式存在可靠性不足的问题(如突然断电或系统崩溃造成的数据丢失),可依赖Sqlite和内存映像解决。
MQTT:物联网通行的MQTT协议可以解决不同系统之间的实时订阅传输问题。
查询扩展:原生支持按时间间隔分组取出数据等常用查询场景,可以有效提高查询性能。
安全控制:采用证书认证方式,加强权限管理,防止数据传输过程中被篡改。
数据归档流程:
五、 下面的计划
网关层接口概述
上下位机通讯原理
如何实现一个设备驱动
如何设计图元
数据采集与归档
VS插件模块及原理
归档模块及文件格式
如何进行功能扩展
组态变量表达式实现
github地址:https://github.com/GavinYellow/SharpSCADA。QQ群:102486275
相关文章:
.NET十年回顾
开源纯C#工控网关+组态软件
开源纯C#工控网关+组态软件(三)加入一个新驱动:西门子S7
开源纯C#工控网关+组态软件(四)上下位机通讯原理
开源纯C#工控网关+组态软件(五)从网关到人机界面
开源纯C#工控网关+组态软件(六)图元组件
原文:http://www.cnblogs.com/evilcat/p/7909578.html
.NET社区新闻,深度好文,欢迎访问公众号文章汇总 http://www.csharpkit.com
