基于java的URP教务系统爬虫实现
URP教务系统是目前许多高校都在使用的教务系统,也是比较老的教务系统了(估计得有十年的历史了)。URP的页面结构非常简单,比较适合用来做爬虫练习,比较困难的地方是利用验证码识别进行自动登录。
因为笔者所在学校的URP教务系统,账号为学号,密码默认也为学号,有很多人没有改掉这个默认密码,所以就想去尝试一下使用默认密码登录指定学号区间的账号,并获取个人头像。(所有爬取到的图片已于24小时内删除,程序仅作为学习交流使用)
目标:利用java实现URP教务系统的自动登录,并尝试爬取目标账号的头像
首先我们先从最难的地方开始,也就是验证码识别。如果过不了验证码这关,其他的都是扯淡。好在URP这个老牌教务系统的验证码还算清楚,识别起来不是很困难。这里选择了tess4j这个框架,让我们先来学习一下tess4j的使用。
将下载的tess4j解压后,我们直接将其导入仅eclipse中,为了方便,我直接在net.sourceforge.tess4j这个包里(位于test文件夹下)新建了一个Test类,代码如下:
package net.sourceforge.tess4j;
import java.io.File;
import net.sourceforge.tess4j.*;
public class Test {
public static void main(String[] args) {
File imageFile = new File("C:\\Users\\fan\\Desktop\\temp\\a.jpg");
ITesseract instance = new Tesseract1(); // JNA Direct Mapping
instance.setLanguage("eng");
try {
String result = instance.doOCR(imageFile);
System.out.println(result.substring(0,4));
} catch (TesseractException e) {
System.err.println(e.getMessage());
}
}
}其中a.jpg是我直接从教务系统中拖下来的验证码,通过短短几行代码,就可以识别出图片的内容。但是需要注意的是,tess4j的识别率不是特别高,对同一验证码进行多次识别,得出的结果也是一样的,所以当识别错误的时候,就需要我们传入新的验证码进行识别,总有一个可以成功。
还有一点,识别出来的字符串尾部可能包含空格,比如原图是abcd,识别出来的字符串可能位abcd ,(注意这有一个空格),所以对结果要取前四个字符。
tess4j在使用前可以通过设置一些参数来提高识别率,这里没有做额外的设置,感兴趣的同学可以自己尝试一下。
将上面的代码做简单封装,留着备用就可以了
package crawler;
import java.io.*;
import net.sourceforge.tess4j.ITesseract;
import net.sourceforge.tess4j.Tesseract;
import net.sourceforge.tess4j.TesseractException;
public class Recognition {
public String execute(File imgFile) {
ITesseract instance = new Tesseract(); // JNA Interface Mapping
instance.setLanguage("eng");
try {
String result = instance.doOCR(imgFile);
return result;
} catch (TesseractException e) {
System.err.println(e.getMessage());
return "";
}
}
}这里还要啰嗦一句,tess4j使用的时候最好将全部的文件复制到项目目录中去,否则容易出现一些奇奇怪怪的问题。
解决了验证码识别的问题,下面我们开始设计爬虫的主体。这边我们选择htmlunit框架,htmlunit相当于一个没有ui界面的浏览器,其具备一个浏览器的全部功能,包括解析执行css、js,而登入URP必须靠js的支持才可以,否则连验证码都没法获取。
下面简单介绍一下htmlunit的使用方法:
WebClient wc = new WebClient();//初始化一个web客户端
//关闭一些无关紧要的异常和css支持
wc.getOptions().setThrowExceptionOnScriptError(false);
wc.getOptions().setThrowExceptionOnFailingStatusCode(false);
wc.getOptions().setCssEnabled(false);
wc.getCookieManager().setCookiesEnabled(true);//设置cookies
HtmlPage page = wc.getPage(URL);//获取dom树
Set cookie = wc.getCookieManager().getCookies();//获取cookies
HtmlForm form = page.getForms().get(0);//获取第0个form
HtmlTextInput input = form.getInputByName("name");//通过name值获取form的输入框
input.setValueAttribute("value");//设置input框的值
//http请求
WebRequest req = new WebRequest(new URL(URLValue));//新建一个http请求
req.setHttpMethod(HttpMethod.GET);//设置请求方法为get
Page page = wc.getPage(req);//发送请求,获取返回页面
WebResponse res = page.getWebResponse();//获取响应
InputStream is = res.getContentAsStream();//以流的形式获取相应体
上面介绍了一些简单的方法,一些dom树的查询方法(比如getElementByXXX,HtmlPage类的方法)就不多赘述了。
通过上面的方法,可以很轻松的建立与URP的连接,获取form并填充,具体实现代码就不写了,下面重点说一下验证码部分,先看下图: 
验证码图片的连接指向了validateCodeAction.do这个组建,并且还有一个请求字段random=0.85013064505066,刷新网页后,会发现这个random值是变化的。直接通过浏览器访问一下这个validateCodeAction.do,并带上相同的random,会发现验证码变了。 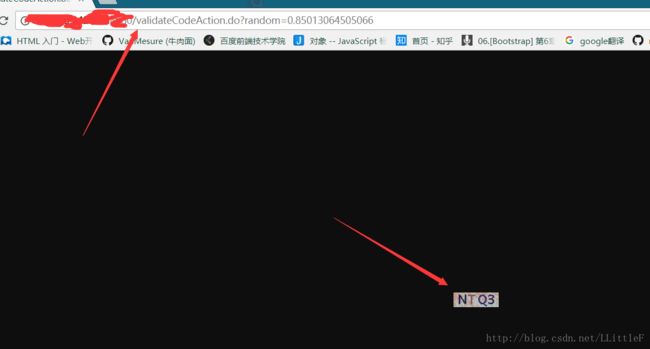
这就很麻烦了,验证码变来变去的,我们该怎么拿到网页上对应的那个验证码呢?
经过一番研究,发现这个验证码是有漏洞的。对于同一个cookie,同样的random字段,每次访问都会返回不同的验证码图片,但是实际上任何一个验证码图片都是被后台认可的。也就是说,当我们打开教务网首页的时候,出现了验证码a,我们带着相同的random值去另外访问验证码页面,得到了验证码b,我们将验证码b输入到主页,也是可以成功登录的。
有了上面这个小漏洞,那么就好办了。具体思路为 :
1、访问首页—拿到cookie和验证码src中的ramdom字段
2、另起一个WebClient,设置好cookie后,发起对/validateCodeAction.do?random= 的请求,random的值为刚刚得到的random值。
3、获取响应流,写入到png文件中
4、调用我们准备好的验证码识别接口,进行验证码识别
5、填充表单,登录
//表单填充完毕后
HtmlImageInput btn = (HtmlImageInput) page.getElementById("btnSure");//获取登录按钮,注意登录按钮其实是一张图片,所以要做一下强制类型转换
HtmlPage newPage = (HtmlPage) btn.click();//点击按钮,得到新的页面
上面的操作不能保证登录一定成功,那么就需要判断一下了。具体分为下面这几种情况:
1、登录失败,有可能是验证码错误,也有可能是密码错误,需要分别判断。
首先通过title可以判断一下登录有没有成功(字符串是直接复制过来的title标签内容)
"URP 综合教务系统 - 登录".equals(newPage.getTitleText())
如果上面这行代码结果为true的话,说明我们登录失败了,具体分为以下两种情况来处理。
登录不成功-验证码错误 
如果是验证码错误,服务器返回的html中多了一个td标签(注意直接访问网站返回的html中并没有这个标签),其class为errorTop,内容为空。
登录不成功-密码错误 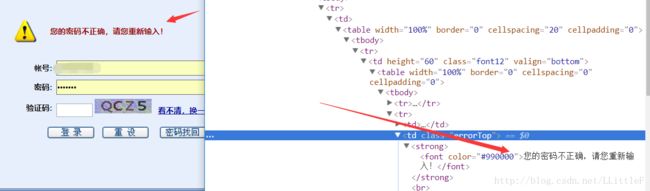
如果是密码错误,同样多了一个class为errorTop的标签,只不过有具体内容了。
所以我们通过这个特殊的td标签,来判断一下到底是验证码错误还是密码错误:
newPage.querySelector(".errorTop").asText().equals("")
如果上面这行代码返回true,说明是验证码错误,那么我们要去重新请求一边验证码,然后调用验证码识别窗口来识别。
如果返回false,说明密码错误,程序终止。
上面介绍了登录失败的情况,如果
"URP 综合教务系统 - 登录".equals(newPage.getTitleText())
不成立的话,那么就说明我们登录成功了(这里忽略了数据库忙的情况)。
成功登录之后,通过抓包分析http请求,带着cookie发送对应的请求,就可以获得想要的数据了。 下图为头像对应的请求。 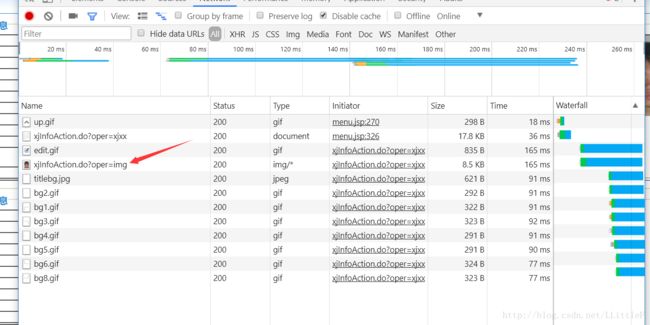
以上只写了部分关键代码,全部代码请浏览我的github主页 https://github.com/VanMesure/URPCrawler。