记一次线上问题排查引发数据库事务与分布式锁的思考
背景
这周有用户反馈关于某个服务数据异常无法正常展示,在后台看日志是server在从数据库中查询完数据,使用Java stream聚合数据时出现了唯一用户 —— 唯一物品的多条数据(隐去业务具体字段名称,以用户、物品作为此次问题的字段),这些异常数据在我们的业务逻辑中是不应该出现的,且通过日志和代码在问题定位的过程中也是相对比较坎坷,因此记录分享一下。
正文
业务逻辑与日志信息
如下所示为我们整个业务的流程,用户客户端调用上传操作物品的具体信息的接口,然后服务端进行或一些必要的参数校验、分布式锁、更新用户信息表(tb_user_info)、新增用户物品关系(tb_user_goods)、最后一步为发送自消费mq消息来处理其他激励相关的业务逻辑。
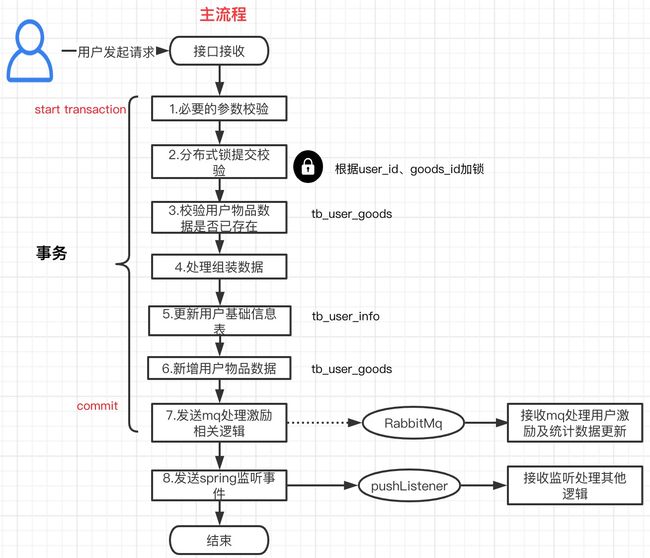
整体看上来是一个挺普通常见的业务场景,且在进行后续逻辑时,有分布式锁、数据重复的提前校验,按说应该不会出现同一个user_id、goods_id在tb_user_goods表中多个数据的情况。然而在数据库中确实有如下的数据,在11点左右三条用户、物品数据被插入至数据库,大体如下:
| id | user_id | goods_id | status_content | create_time | update_time |
|---|---|---|---|---|---|
| f0d96d8fe72d46e3 | 10000 | 39330fa899 | 3 | 11:02:21 | 11:02:21 |
| f5b08cd1275249af | 10000 | 39330fa899 | 3 | 11:05:38 | 11:05:38 |
| 0658e06345554b | 10000 | 39330fa899 | 3 | 11:05:54 | 11:05:54 |
话说日志是代码表达自己的方式,于是我们去查了这个用户对应在11点左右的关于此接口的日志记录,如下,用户陆陆续续进行了8次的提交,而且其中第1次、第7次、第8次按照日志信息都走完了我们上面说提到的业务全流程,而且其他的几次也都走到了业务流程的第7步。
时间 |日志级别|单个服务traceId|微服务间traceId |线程 | 代码行号
[ 11:02:21.584]|[INFO]|[308754bbd24131ac,e68239827357f907]|[http-nio-8080-exec-22]|c.x.c.i.s.s.UserGoodsService-90|
[ 11:03:54.017]|[INFO]|[fb6b104932dde47c,8106fd96ef54cb52]|[http-nio-8080-exec-72]|c.x.c.i.s.s.UserGoodsService-90|
[ 11:04:10.699]|[INFO]|[b8fe086ad30821da,ab33babe55a62008]|[http-nio-8080-exec-56]|c.x.c.i.s.s.UserGoodsService-90|
[ 11:04:31.657]|[INFO]|[b9752e10833c9a85,d049d16327624fd0]|[http-nio-8080-exec-51]|c.x.c.i.s.s.UserGoodsService-90|
[ 11:04:47.319]|[INFO]|[d947a36a4c65a7bb,537c0326e68d5a46]|[http-nio-8080-exec-52]|c.x.c.i.s.s.UserGoodsService-90|
[ 11:05:01.074]|[INFO]|[cf055a3692c5b3a7,1e670463b6203788]|[http-nio-8080-exec-19]|c.x.c.i.s.s.UserGoodsService-90|
[ 11:05:38.616]|[INFO]|[0394e4a9504f994b,6eb1c114c734511b]|[http-nio-8080-exec-52]|c.x.c.i.s.s.UserGoodsService-90|
[ 11:05:54.928]|[INFO]|[2e110eb76b45437f,26a0f82fb0afc229]|[http-nio-8080-exec-19]|c.x.c.i.s.s.UserGoodsService-90|
问题定位
可以看到第1次、第7次、第8次这几次的提交时间与我们数据库的入库时间吻合,而剩下的几次提交均未在数据库中得到体现。因此可以大概看到两个问题:1.为何第1次走完了全流程,剩下2-8次还能通过我们的数据重复校验;2.为何剩下2-8次只有后面的几次成功保存了数据。
数据库级别重复校验问题
首先第一个问题,为何第1次提交走完了全流程,数据入库后,剩下的2-8次请求数据还能通过数据重复校验。这让我首先想到了数据库事务隔离级别的概念,不同的请求在业务处理中的事务id是不一样的,属于不同的事务,因此我们在使用可重复读repeatable-read事务隔离级别时,不同的事务之前数据是不互通的,因此存在一种可能,第1次的事务请求一直没有提交commit,导致剩下2-8次的请求对第1次已经入库的user-goods数据无感知,也顺理成章的通过了数据重复性校验。根据这个猜想,我们就通过后端内部的traceId,看到了此次请求的全流程,果然第1次的请求发起时间:11:02:21,业务处理后的时间:11:06:28,整整用了4分多钟,而4分多钟主要是在业务流程的第7步发送mq的阻塞,后来得知是这个服务依赖的mq组件在当时出了短暂的故障问题,于是在数据库的视角来看,这个事务历经4分钟才提交,其他所有在 11:02:21——11:06:28之间的事务都是不能看到这条user-goods数据的。
其他请求数据保存失败问题
第二个问题,为何2-8次只有7和8次请求保存了数据。对于这个疑问,我们又拿着剩下2-8次的请求traceId查看了请求全流程,发现没有入库的2-6次请求都抛出了一个异常,这是典型的数据库锁超时异常,说明2-6次的请求对于表tb_user_info获取锁时等待超时,最后抛出异常以致整个事务回滚,插入到tb_user_goods表的user-goods数据由于是同一个事务,数据也被回滚。
### Error updating database. Cause: com.mysql.jdbc.exceptions.jdbc4.MySQLTransactionRollbackException: Lock wait timeout exceeded; try restarting transaction
### The error may involve in ....
### SQL: update tb_user_info set ....
至于超时时间多久?使用命令就可以查看SHOW GLOBAL VARIABLES LIKE 'innodb_lock_wait_timeout'; 查看过后,我们业务的锁超时间是50S,而由于第1次的请求在11:02:21——11:06:28期间一直掌握着tb_user_info中,user_id为10000的这条记录,而Innodb事务更新锁是行级锁,这次对应的是一条记录,从第1次请求最终结束11:06:28往前追溯50S,11:05:38这个时间为一个其他事务获取锁等待的最长超时时间即50S。因此第7次请求从11:05:38开始,正好是锁等待的最长时间,在11:06:28锁被释放后成功存入数据,第8次由于更靠后就肯定能成功。

分布式锁问题
第1次的请求历经11:02:21——11:06:28,这个时间内为何相同的数据(user_id、goods_id)进来没有拒绝,后来我查看了一下这个服务的分布式锁实现,是没有进行超时未释放的续约操作的,而我们知道一个完整的分布式锁实现是需要以下几个特点同时满足:
- 上锁时保证原子性,包括value设置、超时时间设置,key为业务属性,value为对应上锁线程id,防止其他线程释放锁(lua脚本实现);
- 如果长时间未释放,需要轮询任务对锁进行续约(防止业务处理时间超长,导致其他相同请求进入);
- 释放锁时带上当前线程id,如果value为对应线程id则释放,否则不允许释放。
而本文中没有对该分布式锁进行续约,或者锁过期时间设置较短导致后续问题的发生。
场景分析
我们将8次请求的时间和日志都整理过之后,基本能还原用户的操作场景,从第1次请求开始等待5S后,客户端判定超时,用户显示提交异常,接下来陆陆续续进行了6次请求均为超时,直至第8次请求,后端依赖的mq中间件恢复、数据库锁释放,在客户端操作的角度,才完成了一次完整的数据提交。然而此时数据已经是异常的多条数据在后端存储了,用户点击回看时后端聚合数据会出现duplicate key,这就是问题的整个场景了。
问题总结
此次问题出现较难定位,且日志及数据库表现形式异常诡异,究其原因是我们在多个地方处理的不到位导致:
- 对于确定唯一数据的表,在建表之初一定要做联合唯一索引,比如这次的tb_user_goods需要建立user_id和goods_id的联合唯一索引,在后面几次请求插入数据时会直接抛出异常,从而回滚整个事务,不会造成脏数据的产生;
- 分布式锁的实现和应用要更为谨慎,不能因为自己想象不到业务场景就断定不存在,采用简易的实现方案后续可能会导致问题,例如此次未对分布式锁进行续约;
- 尽量少的在同步处理的主业务流程依赖中间件,此次如果将发送mq消息的步骤使用线程池实现,也不会导致问题的出现,如果一定要依赖中间件,可以考虑使用可靠性较高的云服务;
- traceId很必要,在整个定位问题的过程中traceId起到了很大的作用,特别是当日志上下文数据传递缺失的时候。
- 显示声明事务时,可以手动控制事务超时时间,此服务使用springboot框架,@Transactional注解配置timeout=5属性即声明超时时间5s,这样可以使业务进入“快速失败”的情景,不至于多个线程hang住。