A Hierarchical Approach for Generating Descriptive Image Paragraphs (CPVR 2017) Li Fei-Fei.
数据集地址: http://cs.stanford.edu/people/ranjaykrishna/im2p/index.html
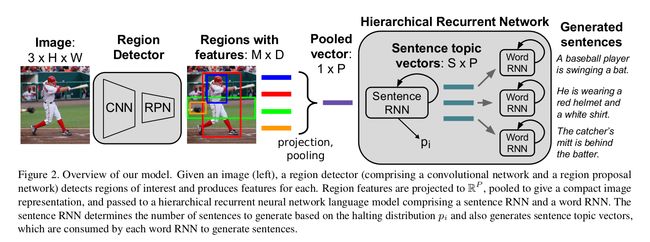
Workflow:
1.decompose the input image by detecting objects and other regions of interest
2.aggregate features across these regions to produce a pooled representation richly expressing the image semantics
3.take this feature vector as input by a hierarchical recurrent neural network composed of two levels: a sentence RNN and a word RNN.
4.sentence RNN receives the image features ,decides how many sentences to generate in the resulting paragraph, and produce an input topic vector for each sentence.
5.word RNN use this topic vector to generate the words of a single sentence.
Region Detector:
CNN+RPN
resize image-->pass through a CNN to get feature maps-->region proposal network(RPN) process the resulting feature maps-->regions of interest are projected onto the convolutional feature maps-->the corresponding region of the feature map is resized to a fixed size using bilinear interpolation and processed by two fully-connected layers to give a vector of dimension D for each region.
Given a dataset of images and ground-truth regions of interest, the region detector can be trained end-to-end fashion for object detection and for dense captioning.
Region Pooling:
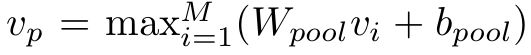
elementwise maximum, Wpool and bpool are learned parameters, vi stands for a set of vectors produced by the region detector.
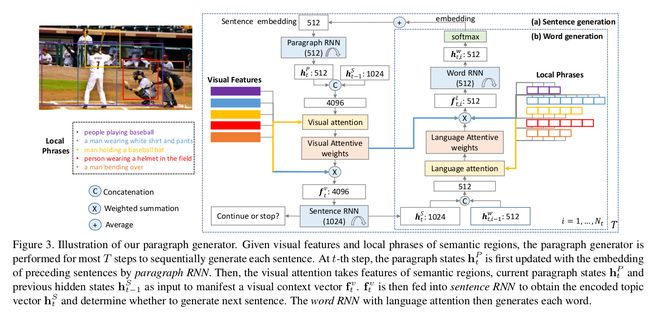
Hierarchical Recurrent Network:
Why Hierachical?
1.It reduces the length of time over which the recurrent networks must reason.
2.the generated paragraphs contain numbers of sentences, both the paragraph and sentence RNNs need only reason over much shorter time-scales, making learning an appropriate representation much more tractable
Sentence RNN: take the pooled region vector vp as input and produce a sequence of hidden states h1,h2,...,hS one for each sentence in the paragraph. Each hidden state used in two ways, produce a distributin pi to determine whether to stop and produce the topic vector ti for the i-th sentence of the paragraph ,which is the input of the word RNN.
Word RNN: the same as the LSTM components in the image captionings.
Training and Sampling:

training loss l(x,y) for the example (x,y) is a weighted sum of the two cross-entropy terms: a sentence loss lsent on the stopping distribution pi , and a word loss lword on the word distribution pij
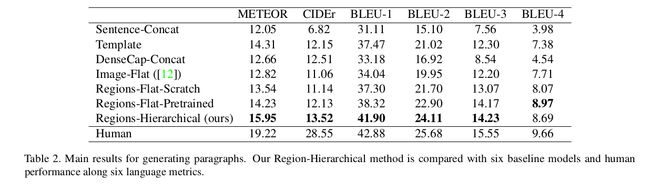
Experiments:
Recurrent Topic-Transition GAN for Visual Paragraph Generation (ICCV 2017)
Xiaodan Liang, Zhiting Hu, Hao Zhang, Chuang Gan, Eric Xing
RTT-GAN

Towards Diverse and Natural Image Descriptions via a Conditional GAN (ICCV 2017)
Previous approaches, including both generation methods and evaluation metrics, primarily focus on the resemblance to the training samples.
Instead of emphasizing n-gram matching, we aim to improve the naturalness and diversity.
Generation.Under the MLE principle, the joint probability of a sentence is, to a large extent, determined by whether it contains the frequent n-grams from the training set.
When the generator yields a few of words that match the prefix of a frequent n-gram, the remaining words of that n-gram will likely be produced following the Markov chain.
Evaluation.Classical metrics include BLEU, and ROUGE, which respectively focuses on the precision and recall of n-grams. Beyond them, METEOR uses a combination of both the precison and the recall of n-grams. CIDEr uses weighted statistics over n-grams. As we can see, such metrics mostly rely on matching n-grams with the "groundtruths". As a result, sentences that contain frequent n-grams will get higher scores as compared to those using variant expressions. SPICE: Instead of matching between n-grams, it focues on those linguistic entities that reflect visual concepts (e.g. objects and relationships). However, other qualities, e.g. the naturalness of the expressions, are not considered in this metric.
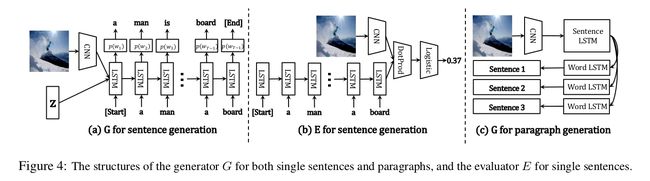
The generator G takes two inputs: an image feature f(I) derived from a CNN and a ramdom vector z.
Diverse and Coherent Paragraph Generation from Images (ECCV 2018)
github: https://github.com/metro-smiles/CapG_RevG_Code
The authors propose to augment paragraph generation techniques with "coherence vectors," "global topic vectors," and modeling of the inherent ambiguity of associating paragraphs with images, via a variational auto-encoder formulation.

Topic Generation Net and Sentence Generation Net
Training for Diversity in Image Paragraph Captioning (EMNLP 2018)
github: https://github.com/lukemelas/image-paragraph-captioning