前几天,同事在报告中提及检测角色是否在扇形攻击范围的方法。我觉得该方法的性能不是太好,提出另一个颇为直接的方法。此问题在游戏中十分常见,只涉及简单的数学,却又可以看出实现者是否细心,所以我觉得可当作一道简单的面试题。问题在微博发表后得到不少回应,故撰文提供一些解答。
问题定义:
在二维中,检测点 \mathbf{p}是否在 扇形(circular sector)内,设扇形的顶点为 \mathbf{c},半径为 r,从 \mathbf{\hat{u}}方向两边展开 \theta角度。
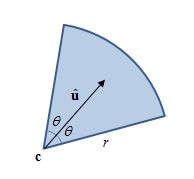
当中 \mathbf{p},\mathbf{c},\mathbf{\hat{u}} 以直角坐标(cartesian coordinates)表示,r>0,0 < \theta < \pi。\mathbf{p}在扇形区边界上当作不相交。实现时所有数值采用单精度浮点数类型。
问题分析
许多相交问题都可以分拆为较小的问题。在此问题中,扇形可表示为圆形和角度区间的交集。
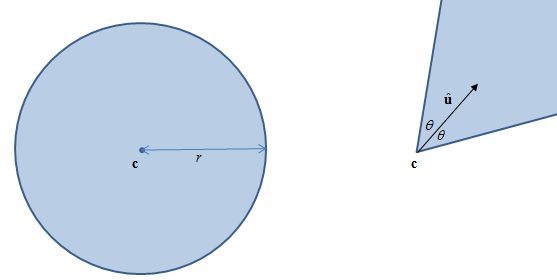
换句话说,问题等同于检测 \mathbf{p} 和 \mathbf{c} 的距离小于 r,及 \mathbf{p-c} 的方向在 \mathbf{\hat{u}} 两边 \theta 的角度范围内。
距离
\mathbf{p} 和 \mathbf{c} 的距离小于 r, 用数学方式表示:
极坐标
这是比较麻烦的部分,也是本题的核心。
有人想到,可以把 \mathbf{p-c} 和 \mathbf{\hat{u}} 从直角坐标转换成极坐标(polar coordinates)。数学上,\mathbf{p-c} 和 \mathbf{\hat{u}} 分别与 \mathbf{x} 轴的夹角可用atan2()函数求得:
然后,检查 \phi 是否在 (\alpha - \theta, \alpha + \theta) 区间内。但这要非常小心,因为 (\alpha - \theta, \alpha + \theta) 区间可能超越 (-\pi, \pi] 的范围,所以要检测:
这个方法是可行的,不过即使假设 \mathbf{\hat{u}} 和 \theta 是常数,可预计算 \alpha_1 和 \alpha_2 ,我们还是避免不了要计算一个atan2()。
点积
点积(dot product)可计算两个矢量的夹角,这非常适合本题的扇形表示方式。我们要检测 \mathbf{p-c} 和 \mathbf{\hat{u}} 的夹角是否小于 \theta :
相比极坐标的方法,点积算出来的夹角必然在 [0, \pi] 区间里,无需作特别处理就可以和 \theta 比较。
这是比较直观的角度比较方式。本文将以此方法为主轴。
编码与优化
若直接实现以距离和点积的检测,可以得到:
// Naive
bool IsPointInCircularSector(
float cx, float cy, float ux, float uy, float r, float theta,
float px, float py)
{
assert(cosTheta > -1 && cosTheta < 1);
assert(squaredR > 0.0f);
// D = P - C
float dx = px - cx;
float dy = py - cy;
// |D| = (dx^2 + dy^2)^0.5
float length = sqrt(dx * dx + dy * dy);
// |D| > r
if (length > r)
return false;
// Normalize D
dx /= length;
dy /= length;
// acos(D dot U) < theta
return acos(dx * ux + dy * uy) < theta;
}
优化版本1: 基本优化
由于计算矢量长度需要sqrt(),而不等式(1.1)左右两侧都是非负数,所以可以把两侧平方:
如果 r 为常数,我们可以预计算 r^2 。
另外,如果\theta是常数,我们可以预计算 \cos \theta ,然后把不等式(1.5) 改为:
可以这么做,是因为 \cos x 在 0 \le x \le \pi 的区间内是单调下降的。
此外,由于除法一般较乘法慢得多,而 |p-c| \ge 0 ,我们可以把 |\mathbf{p-c}| 调至右侧:
基于这两个可能预计算的参数,可把检测函数的参数由 r 和 \theta 改成 r^2 和 \cos \theta 。结合这些改动:
// Basic: use squareR and cosTheta as parameters, defer sqrt(), eliminate division
bool IsPointInCircularSector1(
float cx, float cy, float ux, float uy, float squaredR, float cosTheta,
float px, float py)
{
assert(cosTheta > -1 && cosTheta < 1);
assert(squaredR > 0.0f);
// D = P - C
float dx = px - cx;
float dy = py - cy;
// |D|^2 = (dx^2 + dy^2)
float squaredLength = dx * dx + dy * dy;
// |D|^2 > r^2
if (squaredLength > squaredR)
return false;
// |D|
float length = sqrt(squaredLength);
// D dot U > |D| cos(theta)
return dx * ux + dy * uy > length * cosTheta;
}
注意,虽然比较长度时不用开平方,在夹角的检测里还是要算一次开平方,但这也比必须算开平方好,因为第一个检测失败就不用算了。
优化版本2: 去除开平方
然而,我们有办法去除开平方吗?
这或许是这解答中最难的问题。我们不能简单地把不等式(2.3)两侧平方:
因为两侧分别有可能是正数或负数。若把负数的一侧平方后,就会把负号清除了,我们必须把比较符号反转。
针对左右侧分别可以是负数和非负数四种情况,可以归纳为:
- 若左侧为非负数,右侧为非负数,检测 ((\mathbf{p-c}) \cdot \mathbf{\hat{u}})^2 > {|\mathbf{p-c}|}^2 \cos^2 \theta
- 若左侧为为负数,右侧为负数,检测 ((\mathbf{p-c}) \cdot \mathbf{\hat{u}})^2 < {|\mathbf{p-c}|}^2 \cos^2 \theta
- 若左侧为非负数,右侧为负数,那么不等式(2.3)一定成立
- 若左侧为负数,右侧为非负数,那么不等式(2.3)一定不成立
解释一下,在第2个情况中,先把两侧分别乘以-1,大于就变成小于,两侧就变成非负,可以平方。在实现中,若非第1个或第2个情况,只可能是第3个或第4个,所以只需分辨是3还是4,例如只检测左侧是否负数。
// Eliminate sqrt()
bool IsPointInCircularSector2(
float cx, float cy, float ux, float uy, float squaredR, float cosTheta,
float px, float py)
{
assert(cosTheta > -1 && cosTheta < 1);
assert(squaredR > 0.0f);
// D = P - C
float dx = px - cx;
float dy = py - cy;
// |D|^2 = (dx^2 + dy^2)
float squaredLength = dx * dx + dy * dy;
// |D|^2 > r^2
if (squaredLength > squaredR)
return false;
// D dot U
float DdotU = dx * ux + dy * uy;
// D dot U > |D| cos(theta)
// <=>
// (D dot U)^2 > |D|^2 (cos(theta))^2 if D dot U >= 0 and cos(theta) >= 0
// (D dot U)^2 < |D|^2 (cos(theta))^2 if D dot U < 0 and cos(theta) < 0
// true if D dot U >= 0 and cos(theta) < 0
// false if D dot U < 0 and cos(theta) >= 0
if (DdotU >= 0 && cosTheta >= 0)
return DdotU * DdotU > squaredLength * cosTheta * cosTheta;
else if (DdotU < 0 && cosTheta < 0)
return DdotU * DdotU < squaredLength * cosTheta * cosTheta;
else
return DdotU >= 0;
}
优化版本3: 减少比较
在一些架构上,浮点比较和分支是较慢的操作。由于我们只是要检测数值是否负值,我们可以利用IEEE754浮点数的二进制特性:最高位代表符号,0为正数,1为负数。
我们可把符号用位掩码(bit mask)分离出来,第1和第2个情况就变成比较左右侧的符号是否相等。我们还可以用OR把符号加到两侧平方,意义上就是当负数时把比较符号调换,
而第3个情况也可以直接用符号作比较。
// Bit trick
bool IsPointInCircularSector3(
float cx, float cy, float ux, float uy, float squaredR, float cosTheta,
float px, float py)
{
assert(cosTheta > -1 && cosTheta < 1);
assert(squaredR > 0.0f);
// D = P - C
float dx = px - cx;
float dy = py - cy;
// |D|^2 = (dx^2 + dy^2)
float squaredLength = dx * dx + dy * dy;
// |D|^2 > r^2
if (squaredLength > squaredR)
return false;
// D dot U
float DdotU = dx * ux + dy * uy;
// D dot U > |D| cos(theta)
// <=>
// (D dot U)^2 > |D|^2 (cos(theta))^2 if D dot U >= 0 and cos(theta) >= 0
// (D dot U)^2 < |D|^2 (cos(theta))^2 if D dot U < 0 and cos(theta) < 0
// true if D dot U >= 0 and cos(theta) < 0
// false if D dot U < 0 and cos(theta) >= 0
const unsigned cSignMask = 0x80000000;
union {
float f;
unsigned u;
}a, b, lhs, rhs;
a.f = DdotU;
b.f = cosTheta;
unsigned asign = a.u & cSignMask;
unsigned bsign = b.u & cSignMask;
if (asign == bsign) {
lhs.f = DdotU * DdotU;
rhs.f = squaredLength * cosTheta * cosTheta;
lhs.u |= asign;
rhs.u |= asign;
return lhs.f > rhs.f;
}
else
return asign == 0;
}
上述所作的”优化”,其实只是从算法上著手,试图消除一些可能开销较高的操作。实际上不同的CPU架构的结果也会有所差异。所以我们必须实测才能得知,在某硬件、编译器上,”优化”是否有效。
时间所限,我只做了一个简单的性能测试(欠缺足够边界条件单元测试……):
const unsigned N = 1000;
const unsigned M = 100000;
template
float Test(TestFunc f, float rmax = 2.0f) {
unsigned count = 0;
for (int i = 0; i < N; i++) {
float cx = gCx[i];
float cy = gCy[i];
float ux = gUx[i];
float uy = gUy[i];
float r = naiveParam ? gR[i] : gSquaredR[i];
float t = naiveParam ? gTheta[i] : gCosTheta[i];
for (int j = 0; j < M; j++) {
if (f(cx, cy, ux, uy, r, t, gPx[j], gPy[j]))
count++;
}
}
return (float)count / (N * M);
}
我先用伪随机数生成一些测试数据,然后用两个循环共执行1亿次检测。这比较合乎游戏应用的情况,每次通常是检测M个角色是否在1个扇形之内,做N个迭代。
使用 VS2010,缺省设置加上/fp:fast,Win32/Release的结果:
NoOperation hit=0% time=0.376s
IsPointInCircularSector hit=30.531% time=3.964s
NoOperation hit=0% time=0.364s
IsPointInCircularSector1 hit=30.531% time=0.643s
IsPointInCircularSector2 hit=30.531% time=0.614s
IsPointInCircularSector3 hit=30.531% time=0.571s
NoOperation是指测试的函数只简单传回false,用来检测函循环、读取测试数据和函数调用的开销。之后测的时间会减去这个开销。
可以看到,在简单优化后,预计算 \cos \theta 和 r^2,并延后sqrt(),性能大幅提升4倍以上。之后的优化(第2和第3个版本),只能再优化少许。为了减少sqrt(),却增加了乘数和比较。
有趣的是,若打开/arch:SSE2
NoOperation hit=0% time=0.453s
IsPointInCircularSector hit=30.531% time=2.645s
NoOperation hit=0% time=0.401s
IsPointInCircularSector1 hit=30.531% time=0.29s
IsPointInCircularSector2 hit=30.531% time=0.32s
IsPointInCircularSector3 hit=30.531% time=0.455s
所有性能都提升了,但优化版本反而一直倒退。主要原因应该是SSE含sqrtss指令,能快速完成开平方运算,第2个和第3个版本所做的优化反而增加了指令及分支,而第3个版本更需要把SSE寄存器的值储存至普通寄在器做整数运算,造成更大损失。
优化版本4和5: SOA SIMD
由于编译器自动化的SSE标量可以提高性,进一步的,可采用SOA(struct of array)布局进行以4组参数为单位的SIMD版本。使用了SSE/SSE2 intrinsic的实现,一个版本使用_mm_sqrt_ps(),一个版本去除了_mm_sqrt_ps():
// SSE2, SOA(struct of array) layout
// SSE2, SOA(struct of array) layout
__m128 IsPointInCircularSector4(
__m128 cx, __m128 cy, __m128 ux, const __m128& uy, const __m128& squaredR, const __m128& cosTheta,
const __m128& px, const __m128& py)
{
// D = P - C
__m128 dx = _mm_sub_ps(px, cx);
__m128 dy = _mm_sub_ps(py, cy);
// |D|^2 = (dx^2 + dy^2)
__m128 squaredLength = _mm_add_ps(_mm_mul_ps(dx, dx), _mm_mul_ps(dy, dy));
// |D|^2 < r^2
__m128 lengthResult = _mm_cmpgt_ps(squaredR, squaredLength);
// |D|
__m128 length = _mm_sqrt_ps(squaredLength);
// D dot U
__m128 DdotU = _mm_add_ps(_mm_mul_ps(dx, ux), _mm_mul_ps(dy, uy));
// D dot U > |D| cos(theta)
__m128 angularResult = _mm_cmpgt_ps(DdotU, _mm_mul_ps(length, cosTheta));
__m128 result = _mm_and_ps(lengthResult, angularResult);
return result;
}
// SSE2, SOA(struct of array) layout without sqrt()
__m128 IsPointInCircularSector5(
__m128 cx, __m128 cy, __m128 ux, const __m128& uy, const __m128& squaredR, const __m128& cosTheta,
const __m128& px, const __m128& py)
{
// D = P - C
__m128 dx = _mm_sub_ps(px, cx);
__m128 dy = _mm_sub_ps(py, cy);
// |D|^2 = (dx^2 + dy^2)
__m128 squaredLength = _mm_add_ps(_mm_mul_ps(dx, dx), _mm_mul_ps(dy, dy));
// |D|^2 < r^2
__m128 lengthResult = _mm_cmpgt_ps(squaredR, squaredLength);
// D dot U
__m128 DdotU = _mm_add_ps(_mm_mul_ps(dx, ux), _mm_mul_ps(dy, uy));
// D dot U > |D| cos(theta)
// <=>
// (D dot U)^2 > |D|^2 (cos(theta))^2 if D dot U >= 0 and cos(theta) >= 0
// (D dot U)^2 < |D|^2 (cos(theta))^2 if D dot U < 0 and cos(theta) < 0
// true if D dot U >= 0 and cos(theta) < 0
// false if D dot U < 0 and cos(theta) >= 0
__m128 asign = _mm_and_ps(DdotU, cSignMask.v);
__m128 bsign = _mm_and_ps(cosTheta, cSignMask.v);
__m128 equalsign = _mm_castsi128_ps(_mm_cmpeq_epi32(_mm_castps_si128(asign), _mm_castps_si128(bsign)));
__m128 lhs = _mm_or_ps(_mm_mul_ps(DdotU, DdotU), asign);
__m128 rhs = _mm_or_ps(_mm_mul_ps(squaredLength, _mm_mul_ps(cosTheta, cosTheta)), asign);
__m128 equalSignResult = _mm_cmpgt_ps(lhs, rhs);
__m128 unequalSignResult = _mm_castsi128_ps(_mm_cmpeq_epi32(_mm_castps_si128(asign), _mm_setzero_si128()));
__m128 result = _mm_and_ps(lengthResult, _mm_or_ps(
_mm_and_ps(equalsign, equalSignResult),
_mm_andnot_ps(equalsign, unequalSignResult)));
return result;
}
因为要以SIMD并行执行,不能分支。所有分支都要计算,然后再混合(blend)在一起。测试结果:
IsPointInCircularSector4 hit=30.531% time=0.121s
IsPointInCircularSector5 hit=30.531% time=0.177s
SOA的好处是移植简单,基本上只要把float改成__m128,然后用相应的intrinsic代替浮点四则运算便可。而且能尽用每指令4个数据的吞吐量(throughput)。如果用__m128表示二维矢量(或其他问题中的三维矢量),许多时候会浪费了一些吞吐量(例如在点积运算上)。
第4版本大约比之前最快的版本快近两倍,比没有/arch:SSE2最慢的版本快32倍。第5版本虽去除了开平方,在这个架构下还是得不偿失。
如果计上NoOperationSIMD的时间,SOA、对齐的内存访问方式,以及减少迭代数目,性能提高的幅度就更大。在实际应用中,通常比较难直套用这种内存布局,可能需要做转置(transpose)。对于开发高性能的子系统,在数据结构上可考虑直接储存为SOA。
其他可行方法
除了本文所述的方法,还可以用其他方法:
- 把 \mathbf{p} 转换至扇形的局部坐标 \mathbf{p}’ (如 \mathbf{\hat{u}} 为局部坐标的x轴),然后再比较角度。这个是原来同事的做法。
- 利用二维的"叉积"(实际上叉积只定义于三维)去判断 \mathbf{(p-v)} 是否在两边之内。但需要把u旋转\pm \theta来计算两边。另外,边与 \mathbf{(p-v)} 的夹角可能大于 \pi ,要小心处理。
- 查表。对于现在的机器来说,许多时候直接计算会比查表快,对于SOA来说,查表不能并行,更容易做成瓶颈。此外,查表要结合逻辑所需的精度,通用性会较弱。然言,对于某些应用场景,例如更复杂的运算、非常受限的处理单元(CPU/GPU/DSP等),查表还是十分有用的思路。
或许你还会想到其他方法。也可尝试用不同的扇形表示方式。
结语
这个看来非常简单的问题,也可以作不同尝试。在日常的工作中,可以改善的地方就更是数之不尽了。
源码在放上了Github。