基础知识:
(待补充)
作业相关基本代码
import graphlab
#设置线程限制,节省内存,防止程序崩溃
graphlab.set_runtime_config("GRAPHLAB_DEFAULT_NUM_PYLAMBDA_WORKERS", 8)
#导入数据
products = graphlab.SFrame("amazon_baby.gl/")
#统计评论中的词语
products["word_count"] = graphlab.text_analytics.count_words(products["review"])
#选择12个词作为情感分析的输入
selected_words = ['awesome', 'great', 'fantastic', 'amazing', 'love', 'horrible', 'bad', 'terrible', 'awful', 'wow', 'hate']
#统计每一记录中各个词语的频数
def selected_words_count(dict):
value = 0
if i in dict:
value = dict[i]
return value
for i in selected_words:
products[i] = products['word_count'] .apply(selected_words_count)
#查看统计结果
products.head()
效果如下:

#统计12个词出现的次数
def count(word):
value = 0
for i in products["word_count"]:
if word in i:
value += i.get(word)
return value
list = []
for x in selected_words:
list.append(count(x))
new_dict = dict(zip(selected_words,list))
print new_dict
输出如下结果:
{'fantastic': 932, 'love': 42065, 'bad': 3724, 'awesome': 2090, 'great': 45206, 'terrible': 748, 'amazing': 1363, 'horrible': 734, 'awful': 383, 'hate': 1220, 'wow': 144}
#去除评论中性的词
products = products[products['rating'] != 3]
#添加新列'sentiment'
products['sentiment'] = products['rating'] >= 4
训练情感分类器
#将数据分为train(80%)和test(20%)两部分
train_data,test_data = products.random_split(.8, seed=0)
selected_words_model=graphlab.logistic_classifier.create(train_data,
target='sentiment',
features=selected_words,
validation_set=test_data)
输出如下结果:
Logistic regression:
Number of examples : 133448
Number of classes : 2
Number of feature columns : 11
Number of unpacked features : 11
Number of coefficients : 12
Starting Newton Method
+-----------+----------+--------------+-------------------+---------------------+
| Iteration | Passes | Elapsed Time | Training-accuracy | Validation-accuracy |
+-----------+----------+--------------+-------------------+---------------------+
| 1 | 2 | 1.285266 | 0.844299 | 0.842842 |
| 2 | 3 | 1.485671 | 0.844186 | 0.842842 |
| 3 | 4 | 1.685881 | 0.844276 | 0.843142 |
| 4 | 5 | 1.896848 | 0.844269 | 0.843142 |
| 5 | 6 | 2.098513 | 0.844269 | 0.843142 |
| 6 | 7 | 2.300982 | 0.844269 | 0.843142 |
+-----------+----------+--------------+-------------------+---------------------+
SUCCESS: Optimal solution found.
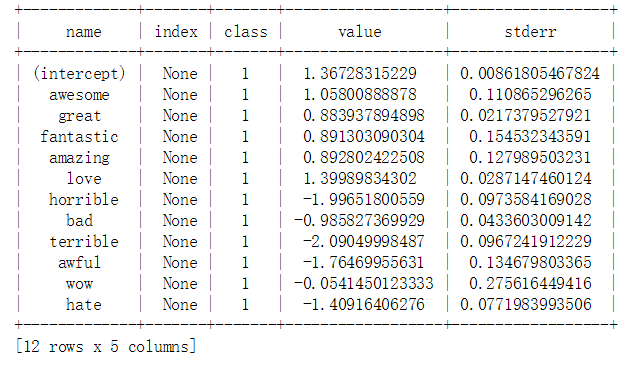
检查模型系数
selected_words_model['coefficients'].print_rows(num_rows=12)
输出结果如下:
评估模型
graphlab.canvas.set_target('ipynb')
selected_words_model.show(view='Evaluation')
selected_words_model.evaluate(test_data)
输出结果如下:


{'accuracy': 0.8431419649291376,
'auc': 0.6648096413721418,
'confusion_matrix': Columns:
target_label int
predicted_label int
count int
Rows: 4
Data:
+--------------+-----------------+-------+
| target_label | predicted_label | count |
+--------------+-----------------+-------+
| 0 | 0 | 234 |
| 0 | 1 | 5094 |
| 1 | 1 | 27846 |
| 1 | 0 | 130 |
+--------------+-----------------+-------+
[4 rows x 3 columns],
'f1_score': 0.914242563530107,
'log_loss': 0.4054747110366022,
'precision': 0.8453551912568306,
'recall': 0.9953531598513011,
'roc_curve': Columns:
threshold float
fpr float
tpr float
p int
n int
Rows: 100001
Data:
+-----------+-----+-----+-------+------+
| threshold | fpr | tpr | p | n |
+-----------+-----+-----+-------+------+
| 0.0 | 1.0 | 1.0 | 27976 | 5328 |
| 1e-05 | 1.0 | 1.0 | 27976 | 5328 |
| 2e-05 | 1.0 | 1.0 | 27976 | 5328 |
| 3e-05 | 1.0 | 1.0 | 27976 | 5328 |
| 4e-05 | 1.0 | 1.0 | 27976 | 5328 |
| 5e-05 | 1.0 | 1.0 | 27976 | 5328 |
| 6e-05 | 1.0 | 1.0 | 27976 | 5328 |
| 7e-05 | 1.0 | 1.0 | 27976 | 5328 |
| 8e-05 | 1.0 | 1.0 | 27976 | 5328 |
| 9e-05 | 1.0 | 1.0 | 27976 | 5328 |
+-----------+-----+-----+-------+------+
[100001 rows x 5 columns]
Note: Only the head of the SFrame is printed.
You can use print_rows(num_rows=m, num_columns=n) to print more rows and columns.}
应用模型进行预测(习题10)
diaper_champ_reviews= products[products['name'] == 'Baby Trend Diaper Champ']
selected_words_model.predict(diaper_champ_reviews[0:1], output_type='probability')
输出结果如下:
dtype: float
Rows: 1
[0.796940851290673]
使用所有词的模型进
sentiment_model = graphlab.logistic_classifier.create(train_data,
target='sentiment',
features=['word_count'],
validation_set=test_data)
sentiment_model.evaluate(test_data)
输出结果如下:
{'accuracy': 0.916256305548883,
'auc': 0.9446492867438502,
'confusion_matrix': Columns:
target_label int
predicted_label int
count int
Rows: 4
Data:
+--------------+-----------------+-------+
| target_label | predicted_label | count |
+--------------+-----------------+-------+
| 0 | 1 | 1328 |
| 0 | 0 | 4000 |
| 1 | 1 | 26515 |
| 1 | 0 | 1461 |
+--------------+-----------------+-------+
[4 rows x 3 columns],
'f1_score': 0.9500349343413533,
'log_loss': 0.26106698432422365,
'precision': 0.9523039902309378,
'recall': 0.9477766657134686,
'roc_curve': Columns:
threshold float
fpr float
tpr float
p int
n int
Rows: 100001
Data:
+-----------+----------------+----------------+-------+------+
| threshold | fpr | tpr | p | n |
+-----------+----------------+----------------+-------+------+
| 0.0 | 1.0 | 1.0 | 27976 | 5328 |
| 1e-05 | 0.909346846847 | 0.998856162425 | 27976 | 5328 |
| 2e-05 | 0.896021021021 | 0.998748927652 | 27976 | 5328 |
| 3e-05 | 0.886448948949 | 0.998462968259 | 27976 | 5328 |
| 4e-05 | 0.879692192192 | 0.998284243637 | 27976 | 5328 |
| 5e-05 | 0.875187687688 | 0.998212753789 | 27976 | 5328 |
| 6e-05 | 0.872184684685 | 0.998177008865 | 27976 | 5328 |
| 7e-05 | 0.868618618619 | 0.998034029168 | 27976 | 5328 |
| 8e-05 | 0.864677177177 | 0.997998284244 | 27976 | 5328 |
| 9e-05 | 0.860735735736 | 0.997962539319 | 27976 | 5328 |
+-----------+----------------+----------------+-------+------+
[100001 rows x 5 columns]
Note: Only the head of the SFrame is printed.
You can use print_rows(num_rows=m, num_columns=n) to print more rows and columns.}
习题9
diaper_champ_reviews= products[products['name'] == 'Baby Trend Diaper Champ']
diaper_champ_reviews['predicted_sentiment'] = sentiment_model.predict(diaper_champ_reviews, output_type='probability')
diaper_champ_reviews =diaper_champ_reviews .sort('predicted_sentiment', ascending=False)
diaper_champ_reviews[0:1]
输出结果如下:

Quiz Week 3
Out of the 11 words in selected_words, which one is most used in the reviews in the dataset?
-greatOut of the 11 words in selected_words, which one is least used in the reviews in the dataset?
-wowOut of the 11 words in selected_words, which one got the most positive weight in the selected_words_model?
-loveOut of the 11 words in selected_words, which one got the most negative weight in the selected_words_model?
-terribleWhich of the following ranges contains the accuracy of the selected_words_model on the test_data?
-0.843Which of the following ranges contains the accuracy of the sentiment_model in the IPython Notebook from lecture on the test_data?
-.916Which of the following ranges contains the accuracy of the majority class classifier, which simply predicts the majority class on the test_data?
-.835How do you compare the different learned models with the baseline approach where we are just predicting the majority class?
-all words better and other almost sameWhich of the following ranges contains the "predicted_sentiment" for the most positive review for "Baby Trend Diaper Champ", according to the sentiment_model from the IPython Notebook from lecture?
-0.999999937267Consider the most positive review for "Baby Trend Diaper Champ" according to the sentiment_model from the IPython Notebook from lecture. Which of the following ranges contains the predicted_sentiment for this review, if we use the selected_words_model to analyze it?
-0.79694Why is the value of the predicted_sentiment for the most positive review found using the sentiment_model much more positive than the value predicted using the selected_words_model?
-None of the selected_words appeared in the text of this review.