tidytext | 耳目一新的R-style文本分析库
腾讯课堂 | Python网络爬虫与文本分析
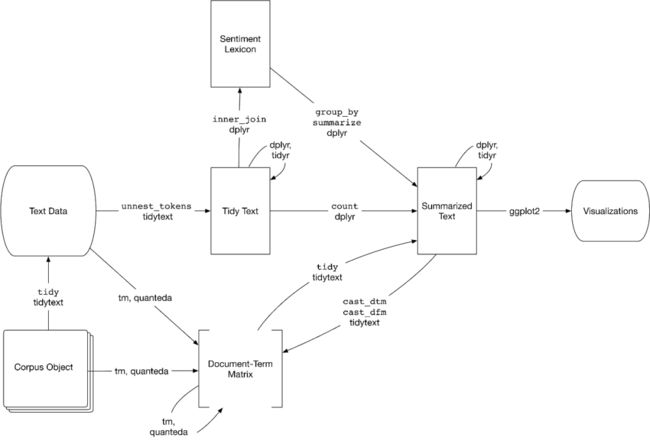
tidytext是R语言的文本分析包,一般数据会整理为dataframe,每行都是由docid-word-freq组成。有一本R语言的文本挖掘书《Text mining with R》,知识体系挺完整的,该书主力分析工具是R语言的tidytext包。
Python中也有一个tidytext库,是对R语言版本的python实现,大家可以了解下文本分析新的数据组织形式,会有一种耳目一新的感觉。Python版只有分词和tfidf两个功能,而R语言中的tidytext还有三种情感词典(bing/nrc/afinn),进行情感分析。如果大家电脑里同时有Python和R,可以使用rpy2库 | 在jupyter中调用R语言代码 这样也能在Python中体验R的文本分析工具。
安装
pip3 install tidytext
准备数据
这里以Python之禅的英文文本作为待处理的文本数据。
import pandas as pd
#设置最大显示行数
pd.set_option('display.max_rows', 6)
zen = """
The Zen of Python, by Tim Peters
Beautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex.
Complex is better than complicated.
Flat is better than nested.
Sparse is better than dense.
Readability counts.
Special cases aren't special enough to break the rules.
Although practicality beats purity.
Errors should never pass silently.
Unless explicitly silenced.
In the face of ambiguity, refuse the temptation to guess.
There should be one-- and preferably only one --obvious way to do it.
Although that way may not be obvious at first unless you're Dutch.
Now is better than never.
Although never is often better than *right* now.
If the implementation is hard to explain, it's a bad idea.
If the implementation is easy to explain, it may be a good idea.
Namespaces are one honking great idea -- let's do more of those!
"""
zen_split = zen.splitlines()
df = pd.DataFrame({'docid': list(range(len(zen_split))),
'text': zen_split})
df
| docid | text | |
|---|---|---|
| 0 | 0 | |
| 1 | 1 | The Zen of Python, by Tim Peters |
| 2 | 2 | |
| ... | ... | ... |
| 19 | 19 | If the implementation is hard to explain, it's... |
| 20 | 20 | If the implementation is easy to explain, it m... |
| 21 | 21 | Namespaces are one honking great idea -- let's... |
22 rows × 2 columns
tidytext库常用函数
unnest_tokens 分词
bind_tf_idf 计算tf-idf
注意 如果是中文数据,需要先用jieba库把中文整理为 英文样式(用空格间隔词语的形式)
分词
unnest_tokens(_data, output, input)
_data传入的dfoutput 分词结果字段名
input df中待分词数据的字段名
现在使用tidytext库中的unnest_tokens()进行分词。可以结合昨日文章了解plydata用法 plydata库 | 数据操作管道操作符>>
from tidytext import unnest_tokens, bind_tf_idf
from plydata import count, slice_rows
#等同于unnest_tokens(data=df,output='word',input='zen')
tokens = df >> unnest_tokens(output='word',
input='text')
tokens
| docid | word | |
|---|---|---|
| 0 | 0 | NaN |
| 1 | 1 | the |
| 1 | 1 | zen |
| ... | ... | ... |
| 21 | 21 | more |
| 21 | 21 | of |
| 21 | 21 | those |
145 rows × 2 columns
#统计词频,显示前20个词
wordfreq1 = (tokens
>> count('word', sort=True)
>> slice_rows(10)
)
wordfreq1
| word | n | |
|---|---|---|
| 0 | is | 10 |
| 1 | better | 8 |
| 2 | than | 8 |
| ... | ... | ... |
| 7 | although | 3 |
| 8 | idea | 3 |
| 9 | be | 3 |
10 rows × 2 columns
词频可视化
熟悉R语言的童鞋应该都不陌生下面的可视化代码,我们使用Python的plotnine库进行可视化绘图 plotnine: Python版的ggplot2作图库
from plotnine import ggplot, aes, geom_col, coord_flip, xlab, ylab
(ggplot(wordfreq1, aes('reorder(word, n)', 'n'))+
geom_col()+
coord_flip()+
ylab('word frequency')+
xlab('')
)

计算tf-idf
bind_tf_idf(_data, term, document, n)
_data传入的dfterm df中词语对应的字段名
document df中文档id的字段名
n df中词频数对应的字段名
tokens

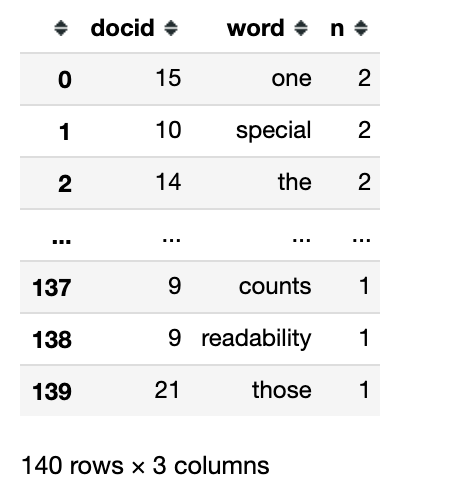
(tokens
>> count('docid', 'word', sort=True)
)
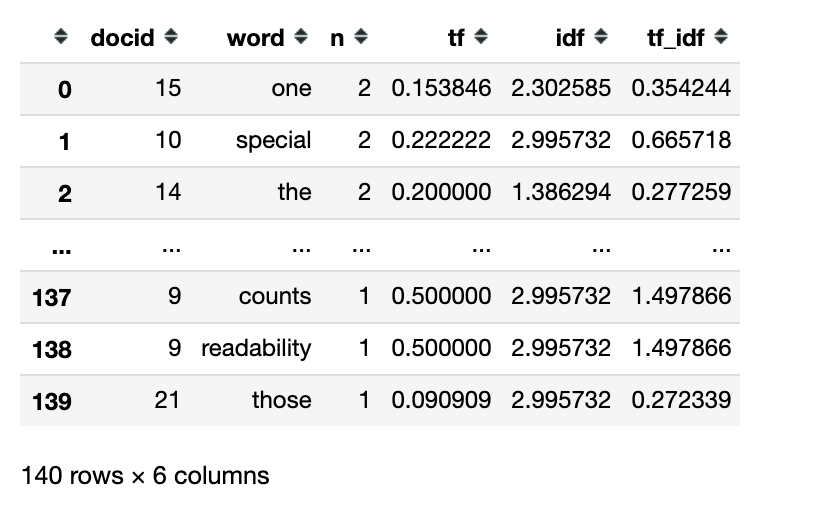
(tokens
>> count('docid', 'word', sort=True)
>> bind_tf_idf(term='word',
document='docid',
n='n')
)
近期文章
[更新] Python网络爬虫与文本数据分析
rpy2库 | 在jupyter中调用R语言代码
plydata库 | 数据操作管道操作符>>
plotnine: Python版的ggplot2作图库
七夕礼物 | 全网最火的钉子绕线图制作教程
读完本文你就了解什么是文本分析
文本分析在经管领域中的应用概述
综述:文本分析在市场营销研究中的应用
plotnine: Python版的ggplot2作图库
小案例: Pandas的apply方法
stylecloud:简洁易用的词云库
用Python绘制近20年地方财政收入变迁史视频
Wow~70G上市公司定期报告数据集
漂亮~pandas可以无缝衔接Bokeh
YelpDaset: 酒店管理类数据集10+G
后台回复关键词【20200820】获取本文代码和《text mining with R》汉化教程
“分享”和“在看”是更好的支持!