pyhon3 爬取河海大学URP教务系统,爬取个人成绩,和本学期的成绩GPA,保存到excel
pyhon3 爬取河海大学URP教务系统,爬取个人成绩,和本学期的成绩GPA,保存到excel
现在不想写,中间有些坑,过几天来聊聊
1.利用百度的ocr,对教务系统的验证码进行识别;
2. 利用urllib库进行模拟登陆和爬取
3. 利用 beautifulSoup对网页进行解析,获取所需数据
4. 利用 xlwt,xlrd,xlutils进行excel的新建和读取和修改
一、爬虫环境搭建
cmd命令pip安装下列模块
pip install bs4
pip install lxml
pip install xlwt
pip install xlrd
pip install xlutils
pip install baidu-aip
pip install pillow
在当前路径下新建一个文件夹data
二、爬虫代码
将学号和密码改成你的
HohaiUrpSpider.py
# encoding: utf-8
'''
@author: weiyang_tang
@contact: [email protected]
@file: HohaiUrpSpider_01.py
@time: 2019-02-18 16:03
@desc: 1.利用百度的ocr,对教务系统的验证码进行识别;
2. 利用urllib库进行模拟登陆和爬取
3. 利用 beautifulSoup对网页进行解析,获取所需数据
4. 利用 xlwt,xlrd,xlutils进行excel的新建和读取和修改
'''
import urllib.request, urllib.parse, urllib.error
import http.cookiejar
from BaiduOcr import getVcode
from bs4 import BeautifulSoup
import xlwt
import xlrd
from xlutils.copy import copy
SNO = '你的学号' # 学号
pwd = '你的密码' # 密码
SName = '' # 学生姓名不用写
capurl = "http://jwurp.hhuc.edu.cn/validateCodeAction.do" # 验证码地址
loginUrl = "http://jwurp.hhuc.edu.cn/loginAction.do" # 登陆地址
logInMaxTryTimes = 10 # 识别验证码最多多少次试错机会,若超过一个阈值则认为学号和密码不符,停止爬虫
getPersonalInfoTimes = 0 # 识别验证码次数,若超过一个阈值则认为学号和密码不符,停止爬虫
getGradesTimes = 0
#保存登陆成功的Cookies
cookie_jar = http.cookiejar.CookieJar()
cookie_jar_handler = urllib.request.HTTPCookieProcessor(cookiejar=cookie_jar)
opener = urllib.request.build_opener(cookie_jar_handler)
picPath = 'D:/image.jpg' # 验证码存放的位置
# 登陆教务系统
def AutomaticLogin(): # 利用百度ocr识别验证码,为了弥补识别可能出错的缺陷,识别错误多次识别,若多次识别仍是错误,则认为是学号和密码不符
picture = opener.open(capurl).read()
local = open(picPath, 'wb')
local.write(picture) # 将验证码写入本地
local.close()
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.67 Safari/537.36',
'Host': 'jwurp.hhuc.edu.cn',
'Origin': 'http://jwurp.hhuc.edu.cn',
'Referer': 'http://jwurp.hhuc.edu.cn/loginAction.do'
}
code = getVcode()
print(code)
postdatas = {'zjh': SNO, 'mm': pwd, 'v_yzm': code}
# 模拟登陆教务处
data = urllib.parse.urlencode(postdatas).encode(encoding='gb2312')
request = urllib.request.Request(loginUrl, data, headers)
try:
response = opener.open(request)
html = response.read().decode('gb2312')
# print(html)
soup = BeautifulSoup(html, 'lxml')
print(soup.title.string)
title = soup.title.string
if (title.__contains__('错误信息')):
# print('登录失败')
AutomaticLogin()
except urllib.error.HTTPError as e:
print(e.code)
def getGrades():
global getGradesTimes
scoreList = [] # 存放成绩的
AutomaticLogin()
# 获取成绩
gradeUrl = 'http://jwurp.hhuc.edu.cn/bxqcjcxAction.do'
gradeRequest = urllib.request.Request(gradeUrl)
responseGrade = opener.open(gradeRequest).read().decode('gb2312')
# print(responseGrade)
soup = BeautifulSoup(responseGrade, 'lxml')
if (soup.title.string != None):
title = soup.title.string
if (title.__contains__('错误信息')):
getGradesTimes = getGradesTimes + 1
if (getGradesTimes <= logInMaxTryTimes):
getGrades()
return None
else:
print('请检查账号和密码是否正确')
return None
# print(soup.title.string)
try:
old_excel = xlrd.open_workbook('data/' + SNO + '_' + SName + '.xls', formatting_info=True)
except Exception:
getPersonalInfo()
getGrades()
return None
new_excel = copy(old_excel)
ws = new_excel.add_sheet('本学期成绩')
rowIndex = 0
colIndex = 0
for th in soup.find_all(name='th'):
ws.write(rowIndex, colIndex, th.string.strip())
colIndex = colIndex + 1
print('%-60s' % th.string.strip(), end=' ')
print()
rowIndex = 1
for tr in soup.find_all(class_='odd'):
scoreList.append([])
colIndex = 0
for td in tr.find_all(name='td'):
scoreList[rowIndex - 1].append(td.string.strip())
ws.write(rowIndex, colIndex, td.string.strip())
colIndex = colIndex + 1
print('%-60s' % td.string.strip(), end=' ')
rowIndex = rowIndex + 1
print()
gpa = getGPA(scoreList)
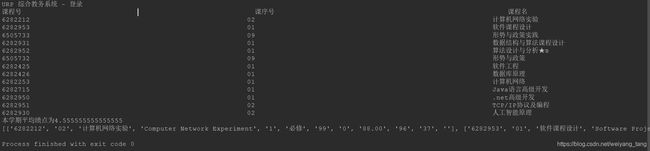
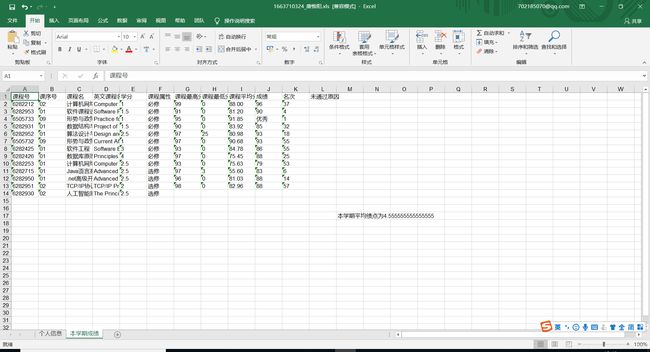
ws.write(rowIndex + 2, colIndex, '本学期平均绩点为' + str(gpa))
print(scoreList)
new_excel.save('data/' + SNO + '_' + SName + '.xls')
def getPersonalInfo():
global getPersonalInfoTimes
personalInfo = []
AutomaticLogin()
personalInfoUrl = 'http://jwurp.hhuc.edu.cn/xjInfoAction.do?oper=xjxx' # 个人信息的url
gradeRequest = urllib.request.Request(personalInfoUrl)
responseGrade = opener.open(gradeRequest).read().decode('gb2312')
myWorkbook = xlwt.Workbook()
mySheet = myWorkbook.add_sheet('个人信息')
rowIndex = 0
soup = BeautifulSoup(responseGrade, 'lxml')
if (soup.title.string != None):
title = soup.title.string
if (title.__contains__('错误信息')):
getPersonalInfoTimes = getPersonalInfoTimes + 1
if (getPersonalInfoTimes <= logInMaxTryTimes):
getPersonalInfo()
return None
else:
return None
for table in soup.find_all(id='tblView'):
for tr in table.find_all(name='tr'):
personalInfo.append([])
colIndex = 0
for td in tr.find_all(name='td'):
if td.string != None:
personalInfo[rowIndex].append(td.string.strip())
mySheet.write(rowIndex, colIndex, td.string.strip())
colIndex = colIndex + 1
print(td.string.strip(), end='')
rowIndex = rowIndex + 1
print()
global SName
SName = personalInfo[0][3]
myWorkbook.save('data/' + SNO + '_' + SName + '.xls')
'''
计算本学期的平均绩点
'''
def getGPA(scoreList):
sumCredit = 0
sumPA = 0.0
for rowIndex in range(len(scoreList)):
if scoreList[rowIndex][5] == '必修':
sumCredit = sumCredit + float(scoreList[rowIndex][4])
sumPA = sumPA + getPA(scoreList[rowIndex][9]) * float(scoreList[rowIndex][4])
try:
avgPA = sumPA / sumCredit
print('本学期平均绩点为' + str(avgPA))
return avgPA
except Exception:
pass
def getPA(score):
if score == "优秀": return 5.0
if score == "良好": return 4.5
if score == "中等": return 3.5
if score == "及格": return 2.5
if score == "不及格": return 0.0
if float(score) >= 90 and float(score) <= 100: return 5.0
if float(score) >= 85 and float(score) <= 89: return 4.5
if float(score) >= 80 and float(score) <= 84: return 4.0
if float(score) >= 75 and float(score) <= 79: return 3.5
if float(score) >= 70 and float(score) <= 74: return 3.0
if float(score) >= 65 and float(score) <= 69: return 2.5
if float(score) >= 60 and float(score) <= 65: return 2.0
if float(score) <= 59: return 0.0
if __name__ == '__main__':
getPersonalInfo()
getGrades()
BaiduOcr.py
利用百度AI的文字识别的API进行验证码识别
# encoding: utf-8
'''
@author: weiyang_tang
@contact: [email protected]
@file: BaiduOcr.py
@time: 2019-02-09 15:10
@desc: 基于百度ocr所做的验证码识别
'''
from aip import AipOcr
from PIL import Image
# 定义常量
APP_ID = '15537967'
API_KEY = 'WfwAe7nwLBiLRiEThmQcrsG4'
SECRET_KEY = 'G3kHHD2QhvsfVk3jtLmvlR7O5qASXp5l'
# 初始化AipFace对象
aipOcr = AipOcr(APP_ID, API_KEY, SECRET_KEY)
# 读取图片
filePath = "D:/image.jpg"
def get_file_content(filePath):
# im = Image.open('D:/image.jpg') # 1.打开图片
# im.show()
with open(filePath, 'rb') as fp:
return fp.read()
def getVcode():
# 定义参数变量
options = {
'detect_direction': 'true',
'language_type': 'CHN_ENG',
}
# 调用通用文字识别接口
result = aipOcr.basicGeneral(get_file_content(filePath), options)
print(result)
keyWord = ''
try:
if (result["words_result"] != None and result["words_result"] != ''):
keyWord = result["words_result"][0]['words'].replace(' ', '')
except Exception:
pass
return keyWord
if __name__ == '__main__':
code = getVcode()
print(code)
三、爬虫成果