附录B 更多IPython系统相关内容
B.3.2 对代码测时:%time和%timeit
对于更大规模或更长时间运行的数据分析应用程序,你可能希望测量各个组件或单个语句或函数调用的执行时间。你可能需要一个在复杂过程中哪些函数最耗时的报告。幸运的是,IPython允许你非常方便地在开发、测试代码的时候获得这些信息。
手工使用内置time模块及其函数time.clock和time.time通常是单调和重复的,因为你必须编写相同的无趣样板代码
由于这是一个很常见的操作,而IPython有两个魔术函数,%time和%timeit,为你自动执行此过程。
%time一次运行一条语句,并报告总执行时间。假设我们有一大串字符串,我们想比较不同的选择所有的字符串中以特殊前缀开始的字符串的方法。这里有一个包含600,000个字符串的列表和两个只选出以’foo’开头的方法(见图B-1)
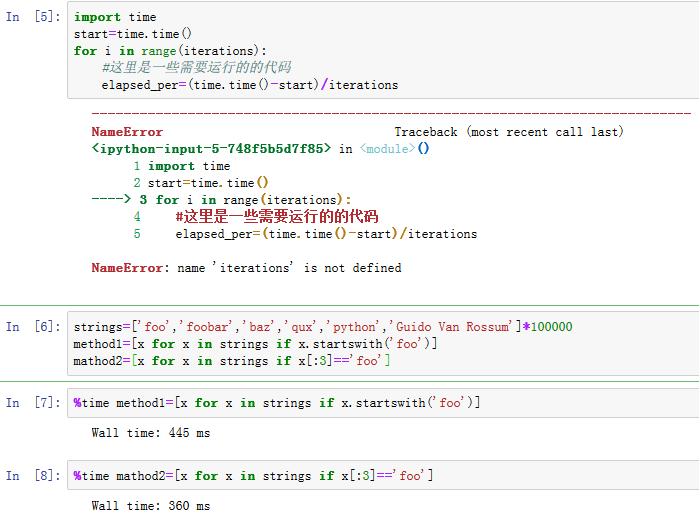
Wall time("wall-clock time"简写,壁钟时间)是我们主要感兴趣的数字。所以,看起来第一种方法需要两倍以上的时间,但这不是一个非常精确的测量。如果你尝试多用%time测试,你就发现测试结果是个变量。为了获得更精确的测量,可以使用%timeit魔术函数。给定任意的语句,%timeit有多次运行语句以产生更准确的平均运行时间的功能(见图B-2)

这个看似普通的例子表明,理解本书中使用的Python标准库、NumPy、pandas以及其他的类库的性能特征是很有必要的。在更大型的数据分析应用中,相差的毫秒就开始累加了!
%timeit对于执行时间很短的分析语句和函数特别有用,甚至在微秒(百万分之一秒)或纳秒(十亿分之一秒)的级别依然有效。
这些时间可能看起来微不足道,但是,调用100万次的20微秒函数比5毫秒的函数要多用15秒。在之前的例子中,我们可以非常直接地对比两个字符串操作来理解它们的性能差异(见图B-3)

B.3.3 基础分析:%prun和%run -p
代码分析与代码测试相关性很高,但代码分析更多关注于时间开销的位置。主要的Python分析工具是cProfile模块,该模块不是专用于IPython。cProfile执行程序或任意代码块,同时记录每个函数花费多少时间。
使用cProfile的常用方法是在命令行上运行整个程序,并输出每个函数的聚合时间。假设我们有一个简单的脚本,它在循环中执行一些线性代数(计算一系列100×100矩阵的最大绝对特征值):
import numpy as np
from numpy.linalg import eigvals
def run_experiment(niter=100):
K = 100
results = []
for _ in xrange(niter):
mat = np.random.randn(K, K)
max_eigenvalue = np.abs(eigvals(mat)).max()
results.append(max_eigenvalue)
return results
some_results = run_experiment()
print 'Largest one we saw: %s' % np.max(some_results)
你可以使用下面的代码在命令行中通过cProfile运行脚本:
python -m cProfile cprof_example.py
如果你按照上面的代码尝试,你会发现输出是按照函数名排序的。这让我们很难了解大部分时间花在哪里,所以通常需要使用-s标志指定一个排序顺序:
$ python -m cProfile -s cumulative cprof_example.py
Largest one we saw: 11.923204422
15116 function calls (14927 primitive calls) in 0.720 seconds
Ordered by: cumulative time
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.001 0.001 0.721 0.721 cprof_example.py:1()
100 0.003 0.000 0.586 0.006 linalg.py:702(eigvals)
200 0.572 0.003 0.572 0.003 {numpy.linalg.lapack_lite.dgeev}
1 0.002 0.002 0.075 0.075 __init__.py:106()
100 0.059 0.001 0.059 0.001 {method 'randn')
1 0.000 0.000 0.044 0.044 add_newdocs.py:9()
2 0.001 0.001 0.037 0.019 __init__.py:1()
2 0.003 0.002 0.030 0.015 __init__.py:2()
1 0.000 0.000 0.030 0.030 type_check.py:3()
1 0.001 0.001 0.021 0.021 __init__.py:15()
1 0.013 0.013 0.013 0.013 numeric.py:1()
1 0.000 0.000 0.009 0.009 __init__.py:6()
1 0.001 0.001 0.008 0.008 __init__.py:45()
262 0.005 0.000 0.007 0.000 function_base.py:3178(add_newdoc)
100 0.003 0.000 0.005 0.000 linalg.py:162(_assertFinite)
...
输出只显示最前面的15行。通过扫描cumtime列来查看每个函数内花费的总时间是最容易的。
请注意,如果一函数调用了其他一些函数,时钟并不会停止运行。cProfile记录了每个函数调用的起始和结束时间,并以此来生成耗时。
除了命令行的使用,还可以通过编程方式使用cProfile来分析任意代码块,而无须运行新进程。IPython使用%prun命令和%run的-p选项为此功能提供了方便的接口。%prun与cProfile采用相同的“命令行选项”,但会分析任意Python语句而不是整个.py文件:
In [4]: %prun -l 7 -s cumulative run_experiment()
4203 function calls in 0.643 seconds
Ordered by: cumulative time
List reduced from 32 to 7 due to restriction <7>
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 0.643 0.643 :1()
1 0.001 0.001 0.643 0.643 cprof_example.py:4(run_experiment)
100 0.003 0.000 0.583 0.006 linalg.py:702(eigvals)
200 0.569 0.003 0.569 0.003 {numpy.linalg.lapack_lite.dgeev}
100 0.058 0.001 0.058 0.001 {method 'randn'}
100 0.003 0.000 0.005 0.000 linalg.py:162(_assertFinite)
200 0.002 0.000 0.002 0.000 {method 'all' of 'numpy.ndarray'}
同样,调用%run -p -s cumulative cprof_example.py与命令行方法具有相同的效果,并且你不必离开IPython。
在Jupyter notebook中,你可以使用%%prun魔术方法(两个百分号%)来分析整个代码块。这会弹出一个包含配置文件输出的独立窗口。独立窗口对于快速回答如下问题很有用:“为什么代码块需要很长时间才能运行?”
还有其他工具可以帮助你在使用IPython或Jupyter时更容易理解配置文件。其中一个是SnakeViz(https://github.com/jiffyclub/snakeviz),它使用d3.js生成配置文件结果的交互式可视化。
B.3.4 逐行分析函数
某些情况下,你从%prun(或者及其他基于cProfile的分析方法)获得的信息可能无法完整阐述函数的执行时间,或者特别复杂而使得根据函数名聚合得到的结果太难而无法解释。对于这种情况,有一个小的库,叫作line_profiler(从PyPI或者其他的包管理工具中获得)。
这个库包含了一个IPython拓展,增加了一个新的魔术函数%lprun, %lprun可以对一或多个函数进行逐行分析。你可以通过修改你的IPython配置类开启这个拓展(参考IPython官方文档或本章之后介绍配置的小节),修改配置时增加下面一行:
# IPython拓展需要载入的模块名称列表
c.TerminalIPythonApp.extensions = ['line_profiler']
你也可以运行以下命令:
%load_ext line_profiler
line_profiler可以按编程的方式使用(参考line_profiler完整文档),但是可能最有效的使用方式还是在IPython中交互式使用。假设你有一个prod_mod模块,该模块含有以下进行NumPy数组操作的代码:
from numpy.random import randn
def add_and_sum(x, y):
added = x + y
summed = added.sum(axis=1)
return summed
def call_function():
x = randn(1000, 1000)
y = randn(1000, 1000)
return add_and_sum(x, y)
如果我们想要知道add_and_sum函数的性能,%prun会给出以下结果:
In [569]: %run prof_mod
In [570]: x = randn(3000, 3000)
In [571]: y = randn(3000, 3000)
In [572]: %prun add_and_sum(x, y)
4 function calls in 0.049 seconds
Ordered by: internal time
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.036 0.036 0.046 0.046 prof_mod.py:3(add_and_sum)
1 0.009 0.009 0.009 0.009 {method 'sum' of 'numpy.ndarray'}
1 0.003 0.003 0.049 0.049 :1()
这不是特别让人理解。通过激活line_profiler的IPython扩展,可以使用新的命令% lprun。使用的唯一区别是我们必须向%lprun指明我们希望分析哪些函数。一般的语法是:
%lprun -f func1 -f func2 statement to profile
在这种情况下,我们想要对add_and_sum做分析,因此我们运行以下代码:
In [573]: %lprun -f add_and_sum add_and_sum(x, y)
Timer unit: 1e-06 s
File: prof_mod.py
Function: add_and_sum at line 3
Total time: 0.045936 s
Line # Hits Time Per Hit % Time Line Contents
==========================================================
3 def add_and_sum(x, y):
4 1 36510 36510.0 79.5 added = x + y
5 1 9425 9425.0 20.5 summed = added.sum(axis=1)
6 1 1 1.0 0.0 return summed
这结果更容易解释。在这种情况下,我们分析了我们在之前语句中使用的相同函数。查看之前的模块代码,我们可以调用并分析call_function以及add_and_sum,从而全面了解代码的性能:
In [574]: %lprun -f add_and_sum -f call_function call_function()
Timer unit: 1e-06 s
File: prof_mod.py
Function: add_and_sum at line 3
Total time: 0.005526 s
Line # Hits Time Per Hit % Time Line Contents
==============================================================
3 def add_and_sum(x, y):
4 1 4375 4375.0 79.2 added = x + y
5 1 1149 1149.0 20.8 summed = added.sum(axis=1)
6 1 2 2.0 0.0 return summed
File: prof_mod.py
Function: call_function at line 8
Total time: 0.121016 s
Line # Hits Time Per Hit % Time Line Contents
==============================================================
8 def call_function():
9 1 57169 57169.0 47.2 x = randn(1000, 1000)
10 1 58304 58304.0 48.2 y = randn(1000, 1000)
11 1 5543 5543.0 4.6 return add_and_sum(x, y)
作为一个通用的经验规则,我倾向于使用%prun(基于cProfile)作为”宏观“的性能分析,用%lprun(基于line_profiler)作为微观分析。对于这两个工具的理解都是非常有意义的。
注:你必须明确指定要使用% lprun进行分析的函数的名称,原因是“回溯”每行的执行时间的开销很大。回溯不感兴趣的函数可能会显著改变分析结果。