Javac工作原理分析(1):词法分析器
Javac分四个模块:词法分析器,语法分析器,语义分析器,代码生成器。
整个流程如下图:
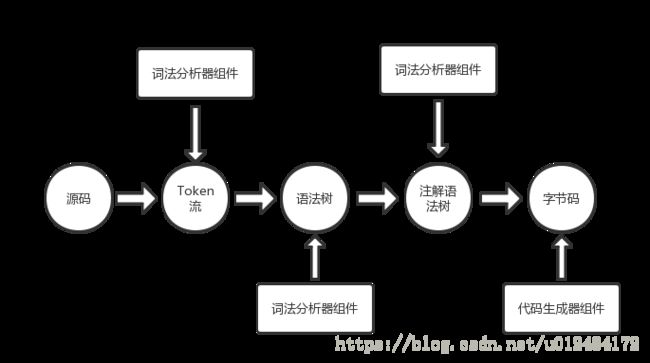
本文先记录词法分析器的工作过程,文中出现的源码出自Jdk9
首先来看一下词法分析器设计的类图:

Lexer和Parser:Javac的主要词法分析器的接口类
Scanner:Lexer的默认实现类,逐个读取java源文件的单个字符,对读取到的词法进行归类
JavacParser:规定哪些词是符合Java语言规范的
Token:规定了所有Java语言的合法关键词
Names:存储和表示解析后的词法
词法分析过程是在JavacParser的parseCompilationUnit方法中完成的:
public JCTree.JCCompilationUnit parseCompilationUnit() {
Token firstToken = token;
JCModifiers mods = null;
boolean consumedToplevelDoc = false;
boolean seenImport = false;
boolean seenPackage = false;
ListBuffer defs = new ListBuffer<>();
if (token.kind == MONKEYS_AT)
// 解析修饰符 "@"
mods = modifiersOpt();
if (token.kind == PACKAGE) {
// 解析package声明
int packagePos = token.pos;
List annotations = List.nil();
seenPackage = true;
if (mods != null) {
checkNoMods(mods.flags);
annotations = mods.annotations;
mods = null;
}
nextToken();
JCExpression pid = qualident(false);
accept(SEMI);
JCPackageDecl pd = F.at(packagePos).PackageDecl(annotations, pid);
attach(pd, firstToken.comment(CommentStyle.JAVADOC));
consumedToplevelDoc = true;
storeEnd(pd, token.pos);
defs.append(pd);
}
boolean checkForImports = true;
boolean firstTypeDecl = true;
while (token.kind != EOF) {
if (token.pos <= endPosTable.errorEndPos) {
// error recovery
skip(checkForImports, false, false, false);
if (token.kind == EOF)
break;
}
if (checkForImports && mods == null && token.kind == IMPORT) {
// 解析import声明
seenImport = true;
defs.append(importDeclaration());
} else {
// 解析class主体
Comment docComment = token.comment(CommentStyle.JAVADOC);
if (firstTypeDecl && !seenImport && !seenPackage) {
docComment = firstToken.comment(CommentStyle.JAVADOC);
consumedToplevelDoc = true;
}
if (mods != null || token.kind != SEMI)
mods = modifiersOpt(mods);
if (firstTypeDecl && token.kind == IDENTIFIER) {
ModuleKind kind = ModuleKind.STRONG;
if (token.name() == names.open) {
kind = ModuleKind.OPEN;
nextToken();
}
if (token.kind == IDENTIFIER && token.name() == names.module) {
if (mods != null) {
checkNoMods(mods.flags & ~Flags.DEPRECATED);
}
defs.append(moduleDecl(mods, kind, docComment));
consumedToplevelDoc = true;
break;
} else if (kind != ModuleKind.STRONG) {
reportSyntaxError(token.pos, "expected.module");
}
}
JCTree def = typeDeclaration(mods, docComment);
if (def instanceof JCExpressionStatement)
def = ((JCExpressionStatement)def).expr;
defs.append(def);
if (def instanceof JCClassDecl)
checkForImports = false;
mods = null;
firstTypeDecl = false;
}
}
JCTree.JCCompilationUnit toplevel = F.at(firstToken.pos).TopLevel(defs.toList());
if (!consumedToplevelDoc)
attach(toplevel, firstToken.comment(CommentStyle.JAVADOC));
if (defs.isEmpty())
storeEnd(toplevel, S.prevToken().endPos);
if (keepDocComments)
toplevel.docComments = docComments;
if (keepLineMap)
toplevel.lineMap = S.getLineMap();
this.endPosTable.setParser(null); // remove reference to parser
toplevel.endPositions = this.endPosTable;
return toplevel;
} 从上述代码中可看出Javac分析词法的原貌,从源文件的一个字符开始,按照Java语法规范一次找出package、import、类定义,以及属性和方法定义等,最后构建一个抽象语法树。
基于上面的原理,下面代码的Token流如图所示。
package test;
public class Cifa {
int a;
int b = a + 1;
}
在上图的Token流中,除了在Java语言规范中定义的保留关键字,还有一个特殊的词TokenKind.IDENTIFIER,这个Token用于表示用户定义的名称,如类名、包名、变量名、方法名等等。
接下来带着两个问题继续深入:
1:Javac怎么知道package就是一个TokenKind.PACKAGE,而不是用户自定义的TokenKind.IDENTIFIER的名称呢?
2:Javac是如何知道哪些字符组合在一起就是一个Token的呢?它是如何从一个字符流中划分出Token来的?
先回答第一个问题:
Javac在进行词法分析时会由JavacParser根据Java语言规范来控制什么顺序、什么地方应该出现什么Token。下面以package关键词为例来说明词法分析器是如何解析词法的。
看一下JavacParser的构造函数:
protected JavacParser(ParserFactory fac,
Lexer S,
boolean keepDocComments,
boolean keepLineMap,
boolean keepEndPositions,
boolean parseModuleInfo) {
this.S = S;
nextToken(); // prime the pump
...忽略无关代码...
}
public void nextToken() {
S.nextToken();
token = S.token();
}在创建JavacParser对象的构造函数时,Scanner会读取第一个Token,而这个Token就是TokenKind.PACKAGE,至于这个Token是怎么分辨出来的,将在第二个问题中回答。前面说了词法分析的整个过程是在JavacParser的parserCompilationUnit方法中完成的,我们再接着看看这个方法的第9行代码。这里是判断当前的Token是不是PACKAGE,如果是的话就会读取整个package的定义。我们看这个if中的执行过程:会接着读取下一个Token,而这个Token就是第二个TokenKind.IDENTIFIER,然后调用qualident方法。
public JCExpression qualident(boolean allowAnnos) {
JCExpression t = toP(F.at(token.pos).Ident(ident()));
while (token.kind == DOT) {
int pos = token.pos;
nextToken();
List<JCAnnotation> tyannos = null;
......
t = toP(F.at(pos).Select(t, ident()));
......
}
return t;
}这段代码的第一行是根据TokenKind.IDENTIFIER的Token构建一个JCIdent的语法节点,然后去取下一个Token,判断这个Token是否是TokenKind.DOT。如果是的话,就进入while循环,读取整个package定义的类路径名称;最后调用accept(SEMI)收尾,该函数判断下一个Token是不是一个Token.SEMI(分号’;’),这样整个”package test;”代码就解析完成了。
接下来回答第二个问题:
package语法、import语法、类定义、field定义、method定义、变量定义、表达式定义等,主要也就这些规则,而这些规则除了一些Java语法规定的关键词就是用户自定义的变量名称了。自定义变量名称包含包名、类名、变量名、方法名,关键词和自定义变量名称之间用空格隔开,每个语法表达式用分号结束。如何判断哪些字符组合是一个Token的规则是在Scanner的nextToken方法中定义的,没调用一次这个方法就会构造一个Token,而这些Token必然是com.sun.tools.javac.parser.Tokens.Token中的任何元素之一。
实际上在读取每一个Token时都需要一个转换过程,如在package中的”test”包名要转换成TokenKind.IDENTIFIER类型,在Java源码中的所有字符集合都要找到在com.sun.tools.parser.Tokens.Token中定义的对应关系,这个任务是在com.sun.tools.javac.parser.Tokens类中完成,Tokens负责将所有字符集合对应到Token集合中(在JDK9中Token其实是Tokens的静态内部类,在更早的JDK版本中是有Keywords类来完成Tokens的工作的)。字符集合到Token转换相关的类关系图如下图所示

每个字符集合都会是一个Name对象,所有的Name对象都存储在Name.Table这个内部类中,这个类就是对应的这个类的符号表。Tokens会将在Token中所有的元素按照它们的Token.name先转化成Name对象,然后建立Name对象和Token的对应关系,这个关系保存在Tokens类中的key数组中,这个key数组只保存了在Token类中定义的所有Token到Name对象的关系,而其他所有字符集合Tokens都会将它对应到TokenKind.IDENTIFIER类型,如下述代码所示:
TokenKind lookupKind(Name name) {
return (name.getIndex() > maxKey) ? TokenKind.IDENTIFIER : key[name.getIndex()];
}其中maxKey的值是在这个Token中最后一个Token对应的Name在Name.Table表中的起始位置。而Name.Table表的前面几个显然都是在Token类中定义的符号。不在Token中的Name对象Index肯定大于keyMax,所以默认的都是IDENTIFiER。