关于 Rocksdb 性能分析 需要知道的一些“小技巧“
文章目录
- 内部工具
- 包含头文件
- 接口使用
- 核心指标
- Perf Context
- IOStats Context
- 外部工具
- systemtap
- Perf工具
2020.8.20 23:23 ,又到了夜深人静学习时,不断得思考总结总会让繁忙一天的大脑得到舒缓。
作为单机存储引擎,Rocksdb总会被嵌入到各个存储系统之中作为核心数据的存储,那么有理有据得“甩锅”便需要一些手段。在业务场景未达到rocksdb自身性能情况下,如何将rocksdb性能在业务中的体现合理展现给使用者,让他们心服口服得"背锅"。
本篇通过内部工具 + 外部工具 的介绍 来全面展示rocksdb 整个IO链(这个IO的范围是从rocksdb入,到文件系统write系统调用完成)上的性能获取,从而更好得决定自己是否可以潇洒"甩锅"。
内部工具
facebook顶尖工程师的不断投入,精心雕琢得社区已经让rocksdb的各个核心特性及其实现都完整展现给使用者,那么一些profling的状态也必然存在。
基本的profiling使用方式如下:
包含头文件
当然这两种头文件是不同的profling状态
iostats_context.h主要是io层面的耗时统计,比如write,read等系统调用的耗时,计数
perf_context.h 主要是内部各个子流程的耗时统计,比如写wal的耗时/请求计数,写memtable的耗时/请求计数
#include “rocksdb/iostats_context.h”
#include “rocksdb/perf_context.h”
接口使用
rocksdb::SetPerfLevel(rocksdb::PerfLevel::kEnableTimeExceptForMutex); //开启profiling
rocksdb::get_perf_context()->Reset(); // 初始化perf_context对象
rocksdb::get_iostats_context()->Reset() // 初始化 iostats_context对象
// ...... 调用Get/Put ,或者一些其他的IO流程
rocksdb::SetPerfLevel(rocksdb::PerfLevel::kDisable); // 关闭profling
//获取具体的profling结果
std::cout << rocksdb::get_perf_context()->ToString() << std::endl; //获取所有的perf 状态
std::cout << rocksdb::get_iostats_context()->ToString() << std::endl; //获取所有的iostats状态
std::cout << "get_from_memtable_time: "
<< rocksdb::get_perf_context()->get_from_memtable_time
<< "write_nanos: "
<< rocksdb::get_iostats_context()->write_nanos
<< std::endl; // 获取某一个具体状态的数值
简单说一下rocksdb提供的perf级别,在文件perf_level.h中
enum PerfLevel : unsigned char {
kUninitialized = 0, // 什么也不监控,一般不实用这个选项
kDisable = 1, // 关闭profling功能
kEnableCount = 2, // 仅开启count计数的profling 功能
kEnableTimeExceptForMutex = 3, // 仅开启time profiling功能,我们耗时方面分析就直接开启这个级别。
// 不过使用者需要注意这里统计的耗时在不同的系统上是有差异的。
kEnableTimeAndCPUTimeExceptForMutex = 4, // 仅开启cpu 耗时的统计
kEnableTime = 5, // 开启所有stats的统计,包括耗时和计数
kOutOfBounds = 6 // 这个不太理解。。。。。。。反正也用不到
};
一般耗时的分析直接用kEnableTimeExceptForMutex 这个级别,如果想要抓取所有的stats信息,包括耗时和计数,就可以使用kEnableTime功能。
详细的实现主要是在perf_context_imp.h 通过宏定义来 实现一些计数和统计的接口,也是为了减少本身统计过程中函数调用的开销。
核心指标
Perf Context
Ps: 以下的耗时统计都是取决于自己什么时候调用SetPerfLevel(rocksdb::PerfLevel::kDisable);的接口,来终止prifling。
二分查找的耗时
user_key_comparison_count统计二分查找的次数,如果次数过多,可能是我们配置的comparator不是很合理。当然这个也与系统中数据量的大小,是否是冷热数据有关。
block cache或者 page cache的效率
block_cache_hit_count我们从block cache中读取数据的次数block_read_count从page cache中读取数据的次数,通过和上一个指标的对比来评估block cache的miss rate,从而确定当前配置下的block cache性能。(实现上,block cache是在page cache之上的一层缓存,默认是LRU)
Get 链路的耗时统计
一般以get 开头的指标,如下是比较重要那的几个
get_from_memtable_time从memtable中读取数据的耗时get_from_output_files_time从sst文件中读取数据的耗时seek_on_memtable_time查找memtable的耗时
Put 链路耗时统计
一般以 write 开头的指标,如下是几个比较重要的
write_wal_time写wal的耗时write_memtable_time写memtable的耗时write_pre_and_post_process_time主要是写入数据之前的一些准备耗时,不包括wal以及memtale的写入耗时
比如在组提交过程中,非leader的写入需要等待leader完成wal的写入之后才能开始写memtble,这一些耗时也会被计算在内
如下代码,在开始写memtale的时候才会停止计时,如果writer是非leader,则writer的状态并不是能够写memtable的,不会进入到这个逻辑,那么非leader就会等待一段时间。
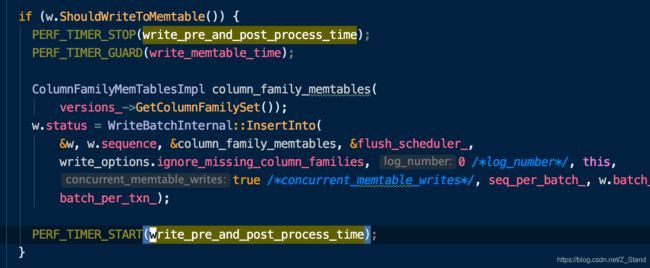
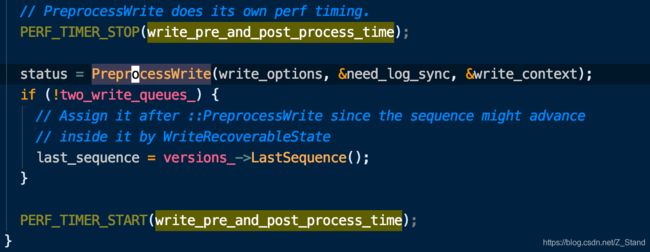
之后还会进入ProcessWrite函数来统计即将写入前的write delay 部分的耗时
IOStats Context
如下几个重要的耗时指标,统计的总时间取决于什么时候关闭profiling接口,也可以每一个请求都统计一次。
write_nanos调用write 和 pwrite系统调用的耗时read_nanos调用read和 pread系统调用的耗时统计fsync_nanos调用fsync系统调用的耗时cpu_write_nanos官方给的描述是 : cpu在write 和 pwrite的耗时
这里应该是统计cpu的写入key-value到文件的计算耗时,因为看代码是在compaction的最终由cpu处理ProcessKeyValueCompaction函数的起始和末尾计算了一下耗时cpu_read_nanoscpu在read 和 pread的耗时
同样read也是在上文中的函数中进行统计的,因为ProcessKeyValueCompaction的处理过程中会涉及key-value 从底层sst文件中的读取
一个简单的demo之前的统计信息:
.......
rocksdb::get_perf_context()->Reset();
rocksdb::get_iostats_context()->Reset();
std::vector<string> keys, values;
rocksdb::WriteOptions write_option;
rocksdb::Status s;
/*执行具体IO操作,stats的统计是两次put,一个get的总和*/
s = binlog_vec[n_db]->Put(write_option, k, rand_value);
assert(s.ok());
s = db_vec[n_db]->Get(rocksdb::ReadOptions(), k, &value);
assert(s.ok());
s = db_vec[n_db]->Put(write_option, k, rand_value);
assert(s.ok());
req_num ++;
buff_num ++;
if (!s.ok())
{
cerr << "Put failed: " << s.ToString() << endl;
exit(1);
}
//if ( thread_id==21 && (now() - ts) >= 1.00 )
if ( (now() - ts) >= 1.00 ) //每隔一秒打印一次
{
time_t temp;
temp = time(NULL);
printf("time is :%s thread_id %ld db%d : count=%ld, speed=%ld\n", \
ctime(&temp),thread_id, n_db, req_num, buff_num);
ts = now();
buff_num = 0;
g_time += 10;
// 关闭profiling
rocksdb::SetPerfLevel(rocksdb::PerfLevel::kDisable);
std::cout << "get_perf_context: \n get_from_memtable_time: " << rocksdb::get_perf_context()->get_from_memtable_time
<< "\nget_from_output_files_time: " << rocksdb::get_perf_context()->get_from_output_files_time
<< "\nblock_read_time: " << rocksdb::get_perf_context()->block_read_time
<< "\nseek_on_memtable_time "<< rocksdb::get_perf_context()->seek_on_memtable_time
<< "\nseek_min_heap_time "<< rocksdb::get_perf_context()->seek_min_heap_time
<< "\neek_max_heap_time "<< rocksdb::get_perf_context()->seek_max_heap_time
<< "\nseek_internal_seek_time "<< rocksdb::get_perf_context()->seek_internal_seek_time
<< "\nwrite_wal_time "<< rocksdb::get_perf_context()->write_wal_time
<< "\nwrite_memtable_time "<< rocksdb::get_perf_context()->write_memtable_time
<< "\nwrite_delay_time "<< rocksdb::get_perf_context()->write_delay_time
<< "\nwrite_scheduling_flushes_compactions_time "<< rocksdb::get_perf_context()->write_scheduling_flushes_compactions_time
<< "\n write_pre_and_post_process_time "<< rocksdb::get_perf_context()->write_pre_and_post_process_time
<< "\nwrite_nanos "<< rocksdb::get_iostats_context()-> write_nanos
<< "\nread_nanos "<< rocksdb::get_iostats_context()-> read_nanos<< std::endl;
std::string out;
db_vec[n_db]->GetProperty("rocksdb.estimate-pending-compaction-bytes", &out);
fprintf(stdout, "rocksdb.estimate-pending-compaction-bytes : %s\n", out.c_str());
if(g_time == 60) {
std::cout << "begin write" << std::endl;
judge_read = false;
}
}
......
输出如下,以下的耗时统计单位都是微妙:
get_perf_context:
get_from_memtable_time: 838
get_from_output_files_time: 0
block_read_time: 0
seek_on_memtable_time 0
seek_min_heap_time 0
eek_max_heap_time 0
seek_internal_seek_time 0
write_wal_time 5947
write_memtable_time 2050
write_delay_time 0
write_scheduling_flushes_compactions_time 261
write_pre_and_post_process_time 899
write_nanos 4513
read_nanos 0
这样,我们就可以通过简单的rocksdb内部已有的工具来进行引擎层的profiling过程排查分析,比如上层存储系统调用rocksdb接口,我们可以将我们rocksdb内部耗时完整展示出来,那么是不是我们的问题就一目了然了。
当然这样的调试过程还会有一些麻烦,我们需要侵入业务的代码,增加一些状态统计,不过结果是精确的,即使因为统计本事的耗时所产生的误差也基本都是us级的,并不影响宏观上的性能比对。
外部工具
结合内部调试工具,我们再通过外部工具进行一些rocksdb流程上耗时的抓取,这里需要对rocksdb内部实现有一定的了解, 我们需要知道抓取一些rocksdb的IO链上的函数。
抓取之前需要应用的二进制文件中包含rocksdb的符号表,即编译rocksdb需要加入-g或者-gd b参数来编译。
大体思路上,还是说先集中在rocksdb内部的耗时之上,因为我们需要明确rocksdb自己的性能上限,处理一个key的过程中,内部各个字阶段的耗时大概是什么样子的量级,相关的测试都是基于Centos7.4 3.10内核。
systemtap
Systemtap 工具是一种可以通过脚本进行自由扩展的动态追踪技术,但是因为长时间游离于内核之外,所以在RHEL系统中是比较稳定,而其他系统则容易出现异常。
反过来说,在3.x 等旧版本内核中,systemtap 相比于eBPF 是一个巨大的优势。
首先通过systemtap 来获取我们rocksdb内部子流程上的关键函数调用栈,从而帮助大家更好的分析。
如果没有stap命令,则可以通过sudo yum install system tap -y来安装systemtap工具。
比如我们抓取写WAL 函数的调用栈,编写call_trace.stp 如下
#!/bin/stap
probe process("/home/test_binary").function("rocksdb::DBImpl::WriteToWAL")
print("------------------------------------\n")
print_ubacktrace()
print("------------------------------------\n")
}
通过sudo stap call_trace.stp | c++filt 将每次调用WriteToWAL函数的调用栈打印出来。这里如果编译rocksdb的时候采用demangle的方式,那么就不需要c++filt了, 否则会出现一些乱码,这里使用c++filt进行过滤。
最终可以看到很多wal相关的调用栈信息如下

通过调用栈,我们就大概知道了从rocksdb的IO链路到上层应用链路的调用关系, 取到了这条路径上的函数,再逐层从下向上结合后面的stap脚本进行耗时统计。
以下是一个案例,可以在binary中增加多个探针,来打印对应函数的耗时情况。
!#/bin/stap
global times
probe process("/home/test_binary").function("rocksdb::DBImpl::WriteImpl").return,
process("/home/test_binary").function("rocksdb::DBImpl::WriteToWAL").return,
process("/home/test_binary").function("rocksdb::WriteBatchInternal::InsertInto").return,
process("/home/test_binary").function("rocksdb::WriteBatchInternal::Iterate").return,
process("/home/test_binary").function("rocksdb::MemTable::Add").return {
times[pid(), ppfunc()] += gettimeofday_us() - @entry(gettimeofday_us()) #耗时及耗时信息放在times 数组之中
}
probe timer.s(10) { #每隔十秒打印一次
println("========%s", execname())
foreach([pid, pp] in times - limit 10) {
printf("pid:%5d %50s %10ld(us)\n", pid, pp, times[pid, pp])
}
delete times
}
最终结果如下(这个结果显然偏高了):
========%sswapper/42
pid:98097 rocksdb::DBImpl::WriteImpl 1510686(us)
pid:98097 rocksdb::DBImpl::WriteToWAL 1153604(us)
pid:98097 rocksdb::WriteBatchInternal::InsertInto 574674(us)
pid:98097 rocksdb::WriteBatchInternal::Iterate 437807(us)
pid:98097 rocksdb::MemTable::Add 257805(us)
一般不建议使用这种多个探针方式进行探测,这样会对应用程序性能有比较大的影响,systemtap的执行方式是 先转换成C代码,编译成内核模块,加载到内核中,对指定的用户程序添加探针,根据指定的行为做对应的返回。如果同时有过多的探针,那肯定会对性能有比较大的影响。
所以这里抓取 的 耗时能够和rocksdb内部统计的耗时数据核对上之后(比如writeToWAL函数的消耗),再进行逐层向上抓取,当然也可以向下抓取。
比如writeToWAL之下会调用AddRecord函数进行log文件的写入,再之下会通过Flush函数进行数据的写入,通过PosixWritableFile::Append函数 调用 PosixWrite函数,最终执行到文件系统的write系统调用之上。详细的写WAL的实现可以参考Rocksdb Wal机制 底层探索。
System tap 这个工具本身还是有很多可以研究的地方,能够极大得节省内核的调试效率(本身的执行方式就是编译成对应的内核模块,加载到系统中执行的),但是在调试用户态应用过程中除了会对应用本身性能有影响之外,其他功能方面的影响还好。
Perf工具
Perf 同样是google开发出来的可以调试用户态以及内核态应用的工具,这里还是挑一些简单的子工具来用作我们rocksdb层面的性能分析。
首先Perf 能够抓取On CPU的进程消耗调用栈,且提供一个火焰图来展示调用栈的信息。
下载FlameGraph到服务器之上,进入FlameGraph目录之后通过root用户执行如下脚本抓取对应进程的On CPU消耗,并且是调用栈的形式。
#!/bin/bash
pid=$1
if [ -z "$pid" ];then
perf record -F 99 -g -- sleep 180
else
perf record -F 99 -p $pid -g -- sleep 180
fi
perf script > out.perf
./stackcollapse-perf.pl out.perf > out.folded
./flamegraph.pl out.folded > kernel-"$pid".svg
传入进程PID,即可生成一个可视化的.svg文件,包含on cpu的进程内部各个函数的消耗情况。
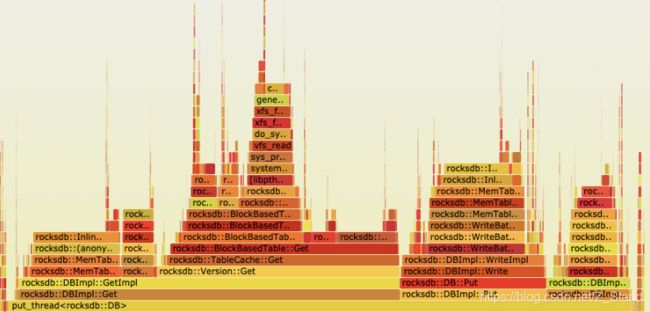
当然这个只能看到一个大体的百分比,我们想要看到具体的耗时情况需要切换一下子工具。
使用perf probe来增加类似于systemtap的探针功能,不过perf的采样更加轻量级,关于内核态的调试这里也是类似的,可以提前perf list来查看 可调试的探针。
-
perf probe增加探针
这里需要提前说明一下,因为perf probe向用户态应用增加探针时可能因为编译选项的一些问题(C++工程没有demangle),则无法找到对应探测的函数地址。建议先手动找一下函数地址,直接使用函数地址进行探测。
通过objdump工具查看函数所处二进制文件中的偏移地址,位于打印出来的第一列objdump /home/test_binary --syms | c++filt | grep -i "rocksdb::rocksdb::log::Writer::AddRecord"增加perf 探针
sudo perf probe -x /home/test_binary '0x0000000000f7d59c'增加成功之后会给一个类似于这样的地址
probe_test_binary:abs_f7d59c,直接复制进行接下来的采样即可。
如果是探测内核函数,更换一下命令选项即可。$ perf probe --add do_sys_open Added new event: probe:do_sys_open (on do_sys_open) You can now use it in all perf tools, such as: perf record -e probe:do_sys_open -aR sleep 1 -
perf record进行采样sudo perf record -e probe_test_binary:abs_f7d59c -aR sleep 60 -
perf script生成可读性报告,查看采样结果sudo perf script
当然这里调试内核的时候可以增加一些参数选项:$ perf probe -V do_sys_open Available variables at do_sys_open @<do_sys_open+0> char* filename int dfd int flags struct open_flags op umode_t mode从而能够使用带参数的探测选项来完成更加详细的探测信息展示:
perf probe --add 'do_sys_open filename:string' -
perf brobe --del探针用完之后需要删除掉sudo perf probe --del probe_test_binary:abs_f7d59c
这里的perf probe还是追踪一些调用关系的逻辑,在火焰图的分析中可以再关注rocksdb层面在当前进程中的消耗占比,大体是能够看出我们rocksdb在当前CPU下的一个压力情况。
通过如上的内部工具 + 外部工具基本能够观察到整个rocksdb 引擎层的耗时情况,这个时候即使不能甩锅,也能轻松定位到具体耗时的函数,来让我们的问题分析排查过程更加精确简单。