netty源码阅读之ByteBuf之ButeBuf内存的释放
我们这一篇文章要使用的用户代码如下:
public static void main(String[] args) {
PooledByteBufAllocator allocator = PooledByteBufAllocator.DEFAULT;
ByteBuf byteBuf = allocator.directBuffer(16);
byteBuf.release();
}分配一个tiny大小16b的内存,调用buteBuf的release进行内存释放,打断点:

F7 step into
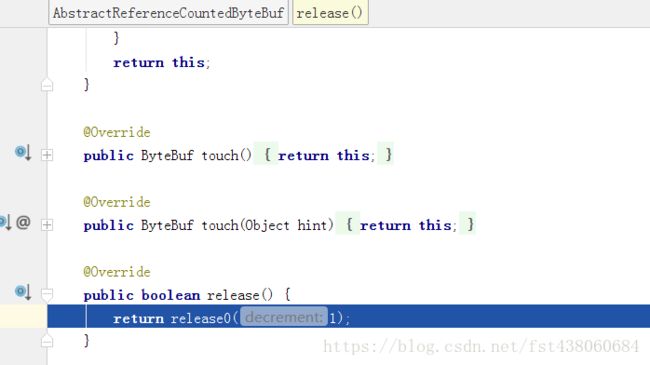
来到了AbstractReferenceCountedByteBuf的release方法,最终都会调用到它的release0()方法:

当refCnt和decrement相同的时候,也就是refCnt-decrement为0的时候,也就是当前的引用数和需要减去的引用数相同,那么就是调用deallocate()方法释放内存了。这里的refCnt和decrement都为1,所以进入了deallocate()方法

继续进入:

在这里将handle置为-1,不指向任何地方,memory也就是内存块也指向空。
ByteBuf内存的释放分为两个阶段,chunk.arena.free(chunk, handle, maxLength, cache);是第一个阶段(释放内存),recycle()是第二个阶段。两个阶段解释为:
1、内存释放
这里分两种情况:
A、连续的内存区段加到缓存
B、标记这段连续的内存区段为未使用
这里的逻辑是,如果添加连续的内存区段到缓存成功,那就直接进行第二阶段;如果添加到缓存未成功,有可能是缓存满了或者别的原因,那么就标记这段连续的内存区段为未使用
page级别的话是通过二叉树方式(层数标记为原来的层数就是未使用),subpage的级别通过位图的的方式(bitmap为0就是未使用)。
2、ByteBuf加到对象池
对象池里面ByteBuf一开始是没有的,ByteBuf释放之后必会被立即销毁,而是放到对象池里面,对象池才有ByteBuf。
一、内存释放
进入chunk.arena.free(chunk, handle, maxLength, cache);

由于是pool,所以会一直走到这里。我们回过头来看看sizeClass(normCapacity)的定义:
private SizeClass sizeClass(int normCapacity) {
if (!isTinyOrSmall(normCapacity)) {
return SizeClass.Normal;
}
return isTiny(normCapacity) ? SizeClass.Tiny : SizeClass.Small;
}其实就是方向查找内存的类型,这里返回tiny。
1、连续的内存区段加到缓存
由于我们的缓存正常,所以一般会走这一步,step into cache.add():

继续进入cache方法:
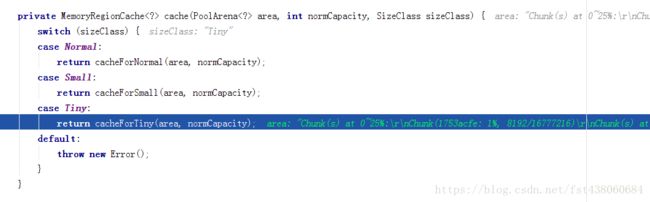
我们是tiny大小的,所以会进入cacheForTiny这个分支,这个方法很眼熟,因为我们之前这篇文章的第一点过 。通过这个方法,我们可以找到对应size的MemoryRegionCache数组里面的元素,可以对照源码去再一次分析。
然后往下走到了这里:

step into:

还记不记得我们在这篇文章第二大点从queue里面取出一个Entry的过程? 这里就是一个反向的过程,包chunk和handle包装成entry,然后放到queue里面,下次可以使用。
我们看newEntry函数吧:
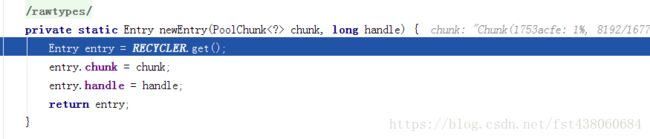
这里我们很惊讶entry是可以回收的,我们后面还会讲到butebuf也是会回收的 ,netty为了减少gc减少内存的创建,使用了对象池,也是用心良苦。
最后加入缓存成功,它一般都是加入缓存成功然后到达这里的:

所以直接返回,不会调用freeChunk方法了 。我们稍微分析下freeChunk方法。
2、标记连续的内存区段为未使用
标记连续的内存区段为未使用就是调用freeChunk方法,如果加入缓存不成功才会调用这个方法,一般不成功的原因是内存满了。
进入源码:
void freeChunk(PoolChunk chunk, long handle, SizeClass sizeClass) {
final boolean destroyChunk;
synchronized (this) {
switch (sizeClass) {
case Normal:
++deallocationsNormal;
break;
case Small:
++deallocationsSmall;
break;
case Tiny:
++deallocationsTiny;
break;
default:
throw new Error();
}
destroyChunk = !chunk.parent.free(chunk, handle);
}
if (destroyChunk) {
// destroyChunk not need to be called while holding the synchronized lock.
destroyChunk(chunk);
}
} 进入chunk.parent.free(chunk, handle);方法:
boolean free(PoolChunk chunk, long handle) {
chunk.free(handle);
if (chunk.usage() < minUsage) {
remove(chunk);
// Move the PoolChunk down the PoolChunkList linked-list.
return move0(chunk);
}
return true;
} 继续进入chunk.free():
void free(long handle) {
int memoryMapIdx = memoryMapIdx(handle);
int bitmapIdx = bitmapIdx(handle);
if (bitmapIdx != 0) { // free a subpage
PoolSubpage subpage = subpages[subpageIdx(memoryMapIdx)];
assert subpage != null && subpage.doNotDestroy;
// Obtain the head of the PoolSubPage pool that is owned by the PoolArena and synchronize on it.
// This is need as we may add it back and so alter the linked-list structure.
PoolSubpage head = arena.findSubpagePoolHead(subpage.elemSize);
synchronized (head) {
if (subpage.free(head, bitmapIdx & 0x3FFFFFFF)) {
return;
}
}
}
freeBytes += runLength(memoryMapIdx);
setValue(memoryMapIdx, depth(memoryMapIdx));
updateParentsFree(memoryMapIdx);
}
这个就是上两篇文章的方向过程。
找出memoryMapIdx定位chunk里面的位置,找出bitmapIdx看看是不是subpage,如果是将走bitmapIdx!=0这个条件里面的内容,把bitmap为1的置为0,就是一个反向过程。subpage是通过bitmap来分配的,page是通过完全二叉树找到对应的里面的节点去分配。
最后也是一个反向过程,把memoryMap里面相应的位置标记为未使用,并把父节点符合条件的也标记为未使用。
二、ByteBuf加到对象池
继续调试就到了这里:

然后是这里:
private void recycle() {
recyclerHandle.recycle(this);
}最后到了这里:
@Override
public void recycle(Object object) {
if (object != value) {
throw new IllegalArgumentException("object does not belong to handle");
}
stack.push(this);
}和我们这篇文章第三大点对应。
netty为了提高性能,申请ByteBuf的时候尽量从对象池里面取,释放的时候,把ByteBuf放到对象池里面,能够做到复用。
netty的ByteBuf为了提高性能,用心良苦,把内存细分为很多块,又用了对象池的技术和缓存技术。