如何榨干cpu的每一滴资源(parallel computing in R)
前言
现在计算机的cpu和system基本都采用了multicore技术(intel i3 2cores、i5 4cores…),但是Windows下我们常常在设计程序时大多是单线程的,然而这却是一种对cpu资源的极度浪费。网上看到过一个动图觉得很能讽刺这种情况
随着R语言学习的加深,也许大家都会觉得处理速度越来越力不从心,那么我们就该考虑如何让我们的程序跑的更快了:
①少用for循环,替而代之的是apply函数族
②将底层计算交给C语言(package “Rcpp”)
③并行计算(package “parallel”)
在本篇博文中我们重点讲述③,R的并行计算。这里推荐一本Norman Matloffd的《CRC.Parallel computong for data science –with examples in R,C plus plus and CUDA》一书,想深入学习的朋友可以阅读,只有英文版的哟!

还想说的是parallel包的大多数并行计算框架都只能基于linux操作系统。其次网上我查阅了很多有关parallel R的使用方法,大多都只是寥寥几个函数的使用便完成计算,虽然实现了并行计算,但却完全没有发挥出并行计算的强大效果。
几个必要函数的简介
①detectCores() 此函数能够检测出计算机或集群所有能够使用的核数
②makeCluster(x) 此函数能创建一个使用的核集cls,x为你想创建的核集的数量 ,不能大于函数detectCores所检测到的核的数量哟
③clusterExport(cls,x) 此函数是将变量x传给cls核集中的所有核的cache
④clusterApply() 方法的使用雷同于apply函数,只不过多了个cls参数来指引核集罢了,是真正执行并行计算的主要函数,静态分配任务块
⑤clusterApplyLB() 功能与clusterApply相同,动态分配任务块
实例讲解
问题描述
线性回归是统计学中一个非常重要的点,而如何选取自变量变成了一个比较容易头疼的问题,自变量的个数过少容易拟合度不高,自变量的个数过多又容易过拟合,所以我们将要写一个函数去计算出自变量的所有搭配组合,然后将每个组合去线性拟合,计算出他们的adjust R square值。这是个非常恐怖的计算过程,如果自变量的个数为3的话,会产生8种组合,如果个数为10的话,将有1024种组合,若个数为x,则产生2的x次方的组合数。
代码分析
主函数:负责各核任务的分配以及结果的整合(类似于hadoop的mapreduce)
snowapr<-function(cls,predictors,responsor,amount,reverse=F,dyn=F,chunksize=1){#参数cls为核makeCluster()创建的核集,predictors为所有的自变量,responsor为因变量,amount是所需计算的自变量组合中自变量的最大个数,reverse为是否倒序分配任务块,dyn为是否动态分配任务块,chunksize是任务块的大小
library(parallel)#导入parallel包
npredictors<-ncol(predictors)#计算有多少个自变量
allcombs<-genallcombs(npredictors,amount)#产生自变量个数不大于amount的所有组合
ncombs<-length(allcombs)#计算产生的组合的个数
clusterExport(cls,'do1pset')#将函数“do1pset”穿给cls中的每一核。因为自编函数并非在每一核的环境下,所以需要传递,否则每个核将找不到自编函数
tasks<- if(!reverse)#若不倒叙则生产正序序列作为每一任务块的起始
seq(1,ncombs,chunksize)
else #若倒叙则生成倒叙序列作为每一任务块的起始
seq(ncombs,1,-chunksize)
out<- if(!dyn)#若不动态分配则使用clusterApply()函数 clusterApply(cls,tasks,dochunk,predictors,responsor,allcombs,chunksize)
else #若动态分配则使用clusterApplyLB()函数
clusterApplyLB(cls,tasks,dochunk,predictors,responsor,allcombs,chunksize)
Reduce(rbind,out)#将所有得到的结果整合
}子函数1:产生自变量个数不大于amount的所有组合
genallcombs<-function(np,amount){#参数np为自变量的个数,amount为自变量组合中的最大自变量个数
allcombs<-list()#创建一个list用于以后装载所有组合
for(i in 1:amount){#从1到amount逐个计算组合
tmp<-combn(1:np,i)#产生1到np中,个数为i的所有组合
allcombs<-c(allcombs,matrixtolist(tmp))#整合组合
}
allcombs#返回所有组合
}子函数2:矩阵装化为列表
matrixtolist<-function(mat){
Map(function(colnum) mat[,colnum],1:ncol(mat))#按列将每列转换成列表项
}子函数3:每个核所执行的程序
dochunk<-function(psetstart,predictors,responsor,allcombs,chunksize){#参数psetstart为被分派的任务块的起始,predictors为所有自变量,responsor为因变量,allcombs为自变量的所有组合,chunksize为任务块大小
ncombs<-length(allcombs)#计算组合的个数
lasttask<-min(psetstart+chunksize-1,ncombs)#计算任务块的结束
t(sapply(allcombs[psetstart:lasttask],do1pset,predictors,responsor))#将任务块中的每一种组合计算其adjust R square值
}子函数4:计算单个组合的adjust R square值
do1pset<-function(onepset,predictors,responsor){#onepset为单个自变量的组合
slm<-summary(lm(responsor~predictors[,onepset]))#计算adjust R square值
n0s<-ncol(predictors)-length(onepset)#计算有多少个自变量没有参与线性拟合
c(slm$adj.r.squared,onepset,rep(0,n0s))#返回标准个数的计算结果
}设计过程
其实设计的思想还是比较简单的,首先完成每个核内该执行的函数dochunk(),然后通过clusterApply函数将所有的任务分派给每个核执行,并将每个核执行的结果通过list的形式返回给我们。
耗时分析
这里我们产生10000个对象,20个自变量x,并生成相应的应变量y
![]()
小批量结果显示
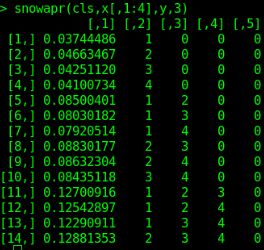
如图,返回的矩阵中,第一列为adjust R square的值,而后几列分别对应为自变量组合的形式
cl2+chunksize1:
首先我们通过cl2<-makeCluster(2)之创建2个可用核的核集,并执行snowapr()函数


我们能够很清楚的看到cpu0和cpu2的使用率为53.5%和58.7,而其他核却不足10%,最后整个程序运行了213秒钟!!!多么糟糕的一个数字啊
cl4+chunksize1:
既然这么慢我们为何不将四个核全部用上?


显示4个cpu的使用率都在50%左右,而程序执行时间相对于2个核运行来说快了1.53倍,这个很好理解,4个人干活当然要比2个人干活来的快嘛,但是为什么不是快2倍呢?虽然4个人比2人干活快,但是分配起来耗时间倍。
cl4+chunksize1+dyn


在使用动态分配任务块后发现每个核的使用率从50%左右增长到了70%+,cpu使用率高了自然程序执行的时间也少了很多,可为什么动态分配要比静态分配时cpu的使用率要高呢?假设当前有2个核c1、c2,4个任务块A、B、C、D,所需耗时分别为40、30、20、10,若按照静态分配的话就是c1分配任务A、C,c2分配任务B、D,总耗时为c1的60秒钟,而c2有足足20秒钟时间的空闲;若按照动态分配的话就是c1分配任务A,c2分配任务B,c2先执行完任务B后获得任务C,c1后执行完任务A后在执行任务D,总耗时只有为50秒,两个核均无空闲。虽然这个例子不能普世化,但却足以表明大多数动态分配为何优于静态分配了
cl4+chunksize3
我们试图改变了chunksize的大小


cpu的使用率居然也提到了70%多,时间也快了不少,多么令人惊喜的一刻。之前chunksize大小为1时是任务一组一组的向每个核发放,这往往使得io的速度跟不上cpu的执行速度,即cpu还未发挥性能就已经计算完任务而又需要io分配新任务。当chunksize大小改为3时便以三组为单位向每个核分配了,自然cpu的使用率高了不少
cl4+chunksizeX
带着上一个的惊喜我们又进一步增加chunksize大小
cores:chunksize5–>chunksize10–>chunksize20



time:chunksize5–>chunksize10–>chunksize20



curve:chunksize1~22
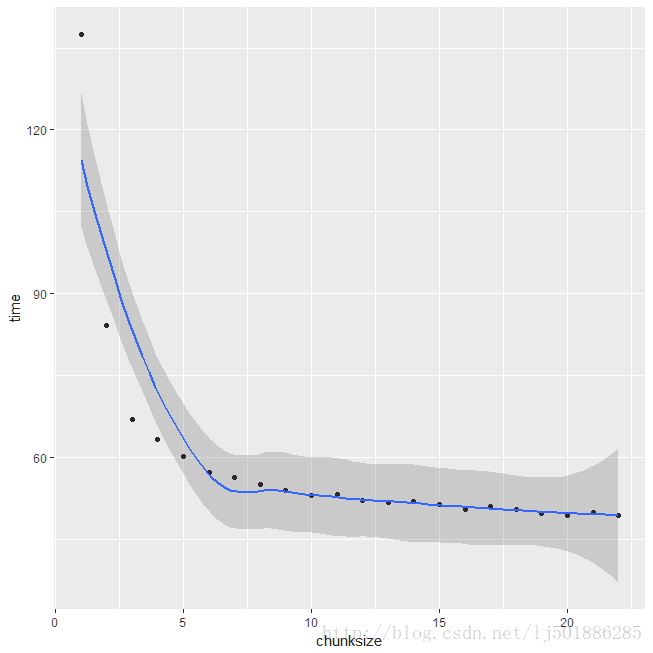
能够很容易得出随着chunksize的逐步增大,cpu使用率越来越高,耗时渐短。但是并不是一味的减小,好像大到一定上限后便不再变化,这就是极限了么?
cl4+chunksize20+dyn
我们在chunksize20的基础上又结合了动态分配


哈哈,时间又进一步减少了1秒,4个核的cpu使用率已达到99%+接近饱和,终于榨干了cpu的每一滴资源。可以看出,虽然chunksize的增大能是cpu使用率上升,却始终受到静态任务分配的瓶颈限制。