netty内存管理
文章目录
- netty内存管理架构设计
- netty内存管理核心类
- PooledByteBufAllocator
- PoolArena
- PoolChunk
- PoolSubpage
- PoolThreadCache
- netty 中的引用计数接口ReferenceCounted
netty内存管理架构设计
netty 内存管理的高性能主要依赖于两个关键点:
- 内存的池化管理
- 使用堆外直接内存(Direct Memory)
堆外直接内存的优势:Java 网络程序中使用堆外直接内存进行内容发送(Socket读写操作),可以避免了字节缓冲区的二次拷贝;相反,如果使用传统的堆内存(Heap Memory,其实就是byte[])进行Socket读写,JVM会将堆内存Buffer拷贝一份到堆外直接内存中,然后才写入Socket中。这样,相比于堆外直接内存,消息在发送过程中多了一次缓冲区的内存拷贝。
池化管理内存和使用堆外内存带来的性能提升如下

netty内存管理核心类
我们使用netty时可以通过很多方式申请ByteBuffer,而这些申请动作最后都是落在ByteBufAllocator的两个实现类上,根据是否使用池化的内存空间选择使用PooledByteBufAllocator或UnpooledByteBufAllocator。这篇博客主要分析PooledByteBufAllocator。
下面是PooledByteBufAllocator的核心类关系图,netty池化内存管理的核心组件有PooledByteBufAllocator,PoolArena,PoolSubpage,PoolChunk。我们一一分析
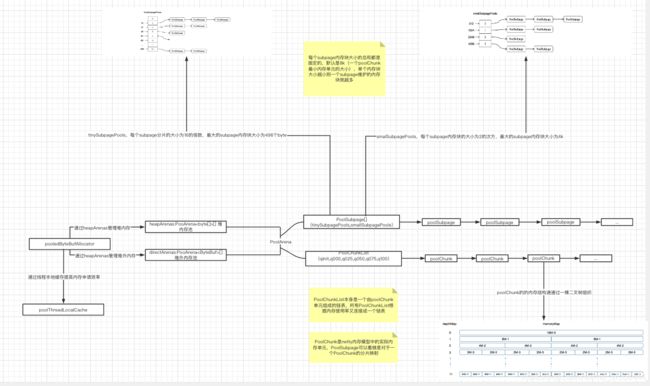
PooledByteBufAllocator
PooledByteBufAllocator是池化内存的申请入口,在静态代码块中读取jvm参数初始化配置(这些配置的修改需要清楚参数使用的原理否则容易踩坑,Netty 内存管理: PooledByteBufAllocator & PoolArena 代码探险)。
PooledByteBufAllocator中主要维护了三个属性
- PoolArena
- PoolArena[] directArenas
- PoolThreadLocalCache threadCache;
其中heapArenas和directArenas分别维护堆内存和堆外内存块,而threadCache用于维护线程本地缓存对象,这些都是netty内存管理体系的重要组成部分。
PoolArena
PoolArena是Netty内存池中的一个核心容器,它的主要作用是对创建的一系列的PoolChunk和PoolSubpage进行管理,根据申请的不同内存大小将最终的申请动作委托给这两个子容器进行管理。整体上,PoolArena管理的内存有直接内存和堆内存两种方式,其是通过子类继承的方式来实现对不同类型的内存的申请与释放的。
1. 整体结构
在整体上,PoolArena是对内存申请和释放的一个抽象,其有两个子类,结构如下图所示:

这里DirectArena和HeapArena是PoolArena对不同类型的内存申请和释放进行管理的两个具体的实现,内存的处理工作主要还是在PoolArena中。从结构上来看,PoolArena中主要包含三部分子内存池:tinySubpagePools,smallSubpagePools和一系列的PoolChunkList。tinySubpagePools和smallSubpagePools都是PoolSubpage的数组,数组长度分别为32和4;PoolChunkList则是一个链表,其内部可以保存一系列的PoolChunk对象,并且,Netty会根据内存使用率的不同,将PoolChunkList分为不同等级的容器。
如下是PoolArena在初始状态时的结构示意图:
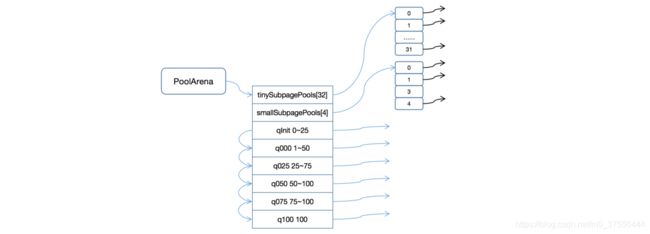
PoolArena的结构
-
初始状态时,tinySubpagePools是一个长度为32的数组,smallSubpagePools是一个长度为4的数组,其余的对象类型则都是PoolChunkList,只不过PoolArena将其按照其内存使用率分为qInit->内存使用率为0~25,q000->内存使用率为1~50,q025->内存使用率为25~75,q050->内存使用率为50~75,q075->内存使用率为75~100,q100->内存使用率为100。
-
初始时,tinySubpagePools和smallSubpagePools数组中的每一个元素都是空的,而PoolChunkList内部则没有保有任何的PoolChunk。从图中可以看出,PoolChunkList不仅内部保存有PoolChunk对象,而且还有一个指向下一高等级使用率的PoolChunkList的指针。PoolArena这么设计的原因在于,如果新建了一个PoolChunk,那么将其添加到PoolChunkList的时候,只需要将其添加到qInit中即可,其会根据当前PoolChunk的使用率将其依次往下传递,以保证将其归属到某个其使用率范围的PoolChunkList中;
-
tinySubpagePools数组中主要是保存大小小于等于496byte的内存,其将0~496byte按照16个字节一个等级拆分成了31等,并且将其保存在了tinySubpagePools的1~31号位中。需要说明的是,tinySubpagePools中的每一个元素中保存的都是一个PoolSubpage链表。也就是说,在tinySubpagePools数组中,第1号位中存储的PoolSubpage维护的内存大小为16byte,第2号位中存储的PoolSubpage维护的内存大小为32byte,第3号位中存储的PoolSubpage维护的内存大小为48byte,依次类推,第31号位中存储的PoolSubpage维护的内存大小为496byte。关于PoolSubpage的实现原理,读者可以阅读本人前面的文章Netty内存池之PoolSubpage详解;
smallSubpagePools数组长度为4,其维护的内存大小为496byte~8KB。smallSubpagePools中内存的划分则是按照2的指数次幂进行的,也就是说其每一个元素所维护的PoolSubpage的内存大小都是2的指数次幂,比如第0号位中存储的PoolSubpage维护的内存大小为512byte,第1号位为1024byte,第2号位为2048byte,第3号位为4096。需要注意的是,这里说的维护的内存大小指的是最大内存大小,比如申请的内存大小为5000 > 4096byte,那么PoolArena会将其扩展为8092,然后交由PoolChunk进行申请;
图中qInit、q000、q025、q050、q075和q100都是一个PoolChunkList,它们的作用主要是维护大小符合当前使用率大小的PoolChunk。
PoolChunkList结构
- PoolChunkList内部维护了一个PoolChunk的head指针,而PoolChunk本身就是一个单向链表,当有新的PoolChunk需要添加到当前PoolChunkList中时,其会将该PoolChunk添加到该链表的头部;
- PoolChunkList也是一个单项链表,如图中所示,其会根据图中的顺序,在内部维护一个下一等级使用率的PoolChunkList的指针。这样处理的优点在于,当需要添加一个PoolChunk到PoolChunkList中时,只需要调用头结点,也即qInit的add()方法,每个PoolChunkList都会检查目标PoolChunk使用率是否符合当前PoolChunkList,如果满足,则添加到当前PoolChunkList维护的PoolChunk链表中,如果不满足,则将其交由下一PoolChunkList处理;
- 图中每个PoolChunkList后面都写了一个数字范围,这个数字范围表示的就是当前PoolChunkList所维护的使用率范围,比如qInit维护的使用率为0~25%,q000维护的使用率为1~50%等等;
- PoolChunkList在维护PoolChunk时,还会对其进行移动操作,比如某个PoolChunk内存使用率为23%,当前正处于qInit中,在一次内存申请时,从该PoolChunk中申请了5%的内存,此时内存使用率达到了30%,已经不符合当前PoolChunkList(qInit->0~25%)的内存使用率了,此时,PoolChunkList就会将其交由其下一PoolChunkList进行处理,q000就会判断收到的PoolChunk使用率30%是符合当前PoolChunkList使用率定义的,因而会将其添加到当前PoolChunkList中。
内存申请过程举例
- 上面的内存划分中可以看到,PoolArena内存大小区间为:tinySubpagePools->低于496byte,smallSubpagePools->512~4096byte,PoolChunkList->8KB~16M。PoolArena首先会判断目标内存在哪个内存范围,30 < 496byte,因而会将其交由tinySubpagePools进行申请;
- 由于tinySubpagePools中每个等级的内存块划分是以16byte为单位的,因而PoolArena会将目标内存扩容到大于其的第一个16的倍数,也就是32(如果申请的内存大小在smallSubpagePools或者PoolChunkList中,那么其扩容的方式则是查找大于其值的第一个2的指数次幂)。32对应的是tinySubpagePools的下标为2的PoolSubpage链表,这里就会取tinySubpagePools[2],然后从其头结点的下一个节点开始判断是否有足够的内存(头结点是不保存内存块的),如果有则将申请到的内存块封装为一个ByteBuf对象返回;
- 在初始状态时,tinySubpagePools数组元素都是空的,因而按照上述步骤将不会申请到对应的内存块,此时会将申请动作交由PoolChunkList进行。PoolArena首先会依次从qInit、q000、…、q100中申请内存,如果在某一个中申请到了,则将申请到的内存块封装为一个ByteBuf对象,并且将其返回;
- 初始时,每一个PoolChunkList都没有可用的PoolChunk对象,此时PoolArena会创建一个新的PoolChunk对象,每个PoolChunk对象维护的内存大小都是16M。然后内存申请动作就会交由PoolChunk进行,在PoolChunk申请到内存之后,PoolArena就会将创建的这个PoolChunk按照前面将的方式添加到qInit中,qInit会根据该PoolChunk已经使用的内存大小将其移动到对应使用率的PoolChunkList中;
- 关于PoolChunk申请内存的方式,这里需要说明的是,我们申请的是30byte内存,而PoolChunk内存申请最小值为8KB。因而这里在PoolChunk申请到8KB内存之后,PoolChunk会将其交由一个PoolSubpage进行维护,并且会设置该PoolSubpage维护的内存块大小为32byte,然后根据其维护的内存块大小,将其放到tinySubpagePools的对应位置,这里是tinySubpagePools[2]的PoolSubpage链表中。放到该链表之后,然后再在该PoolSubpage中申请目标内存扩容后的内存,也就是32byte,最后将申请到的内存封装为一个ByteBuf对象返回;
可以看出,PoolArena对内存块的维护是一个动态的过程,其会根据目标内存块的大小将其交由不同的对象进行处理。这样做的好处是,由于内存申请是一个多线程共享的高频率操作,将内存进行划分可以使得并发处理时能够减小锁的竞争。如下图展示了在多次内存申请之后,PoolArena的一个结构:

PoolArena主要属性讲解
PoolArena中有非常多的属性值,用于对PoolSubpage、PookChunk和PoolChunkList进行控制。在阅读源码时,如果能够理解这些属性值的作用,将会极大的加深对Netty内存池的理解。我们这里对PoolArena的主要属性进行介绍:
// 该参数指定了tinySubpagePools数组的长度,由于tinySubpagePools每一个元素的内存块差值为16,
// 因而数组长度是512/16,也即这里的512 >>> 4
static final int numTinySubpagePools = 512 >>> 4;
// 记录了PooledByteBufAllocator的引用
final PooledByteBufAllocator parent;
// PoolChunk底层是一个平衡二叉树,该参数指定了该二叉树的深度
private final int maxOrder;
// 该参数指定了PoolChunk中每一个叶节点所指代的内存块的大小
final int pageSize;
// 指定了叶节点大小8KB是2的多少次幂,默认为13,该字段的主要作用是,在计算目标内存属于二叉树的
// 第几层的时候,可以借助于其内存大小相对于pageShifts的差值,从而快速计算其所在层数
final int pageShifts;
// 指定了PoolChunk的初始大小,默认为16M
final int chunkSize;
// 由于PoolSubpage的大小为8KB=8196,因而该字段的值为
// -8192=>=> 1111 1111 1111 1111 1110 0000 0000 0000
// 这样在判断目标内存是否小于8KB时,只需要将目标内存与该数字进行与操作,只要操作结果等于0,
// 就说明目标内存是小于8KB的,这样就可以判断其是应该首先在tinySubpagePools或smallSubpagePools
// 中进行内存申请
final int subpageOverflowMask;
// 该参数指定了smallSubpagePools数组的长度,默认为4
final int numSmallSubpagePools;
// 指定了直接内存缓存的校准值
final int directMemoryCacheAlignment;
// 指定了直接内存缓存校准值的判断变量
final int directMemoryCacheAlignmentMask;
// 存储内存块小于512byte的PoolSubpage数组,该数组是分层次的,比如其第1层只用于大小为16byte的
// 内存块的申请,第2层只用于大小为32byte的内存块的申请,……,第31层只用于大小为496byte的内存块的申请
private final PoolSubpage<T>[] tinySubpagePools;
// 用于大小在512byte~8KB内存的申请,该数组长度为4,所申请的内存块大小为512byte、1024byte、
// 2048byte和4096byte。
private final PoolSubpage<T>[] smallSubpagePools;
// 用户维护使用率在50~100%的PoolChunk
private final PoolChunkList<T> q050;
// 用户维护使用率在25~75%的PoolChunk
private final PoolChunkList<T> q025;
// 用户维护使用率在1~50%的PoolChunk
private final PoolChunkList<T> q000;
// 用户维护使用率在0~25%的PoolChunk
private final PoolChunkList<T> qInit;
// 用户维护使用率在75~100%的PoolChunk
private final PoolChunkList<T> q075;
// 用户维护使用率为100%的PoolChunk
private final PoolChunkList<T> q100;
// 记录了当前PoolArena已经被多少个线程使用了,在每一个线程申请新内存的时候,其会找到使用最少的那个
// PoolArena进行内存的申请,这样可以减少线程之间的竞争
final AtomicInteger numThreadCaches = new AtomicInteger();
源码
内存申请
PoolArena对内存申请的控制,主要是按照前面的描述,如下是其allocate()方法的源码:
PooledByteBuf<T> allocate(PoolThreadCache cache, int reqCapacity, int maxCapacity) {
// 这里newByteBuf()方法将会创建一个PooledByteBuf对象,但是该对象是未经初始化的,
// 也就是说其内部的ByteBuffer和readerIndex,writerIndex等参数都是默认值
PooledByteBuf<T> buf = newByteBuf(maxCapacity);
// 使用对应的方式为创建的ByteBuf初始化相关内存数据,我们这里是以DirectArena进行讲解,因而这里
// 是通过其allocate()方法申请内存
allocate(cache, buf, reqCapacity);
return buf;
}
上述方法主要是一个入口方法,首先创建一个属性都是默认值的ByteBuf对象,然后将真正的申请动作交由allocate()方法进行:
private void allocate(PoolThreadCache cache, PooledByteBuf<T> buf, final int reqCapacity) {
// 这里normalizeCapacity()方法的主要作用是对目标容量进行规整操作,主要规则如下:
// 1. 如果目标容量小于16字节,则返回16;
// 2. 如果目标容量大于16字节,小于512字节,则以16字节为单位,返回大于目标字节数的第一个16字节的倍数。
// 比如申请的100字节,那么大于100的16的倍数是112,因而返回112个字节
// 3. 如果目标容量大于512字节,则返回大于目标容量的第一个2的指数幂。
// 比如申请的1000字节,那么返回的将是1024
final int normCapacity = normalizeCapacity(reqCapacity);
// 判断目标容量是否小于8KB,小于8KB则使用tiny或small的方式申请内存
if (isTinyOrSmall(normCapacity)) {
int tableIdx;
PoolSubpage<T>[] table;
boolean tiny = isTiny(normCapacity); // 判断目标容量是否小于512字节,小于512字节的为tiny类型的
if (tiny) {
// 这里首先从当前线程的缓存中尝试申请内存,如果申请到了,则直接返回,该方法中会使用申请到的
// 内存对ByteBuf对象进行初始化
if (cache.allocateTiny(this, buf, reqCapacity, normCapacity)) {
return;
}
// 如果无法从当前线程缓存中申请到内存,则尝试从tinySubpagePools中申请,这里tinyIdx()方法
// 就是计算目标内存是在tinySubpagePools数组中的第几号元素中的
tableIdx = tinyIdx(normCapacity);
table = tinySubpagePools;
} else {
// 如果目标内存在512byte~8KB之间,则尝试从smallSubpagePools中申请内存。这里首先从
// 当前线程的缓存中申请small级别的内存,如果申请到了,则直接返回
if (cache.allocateSmall(this, buf, reqCapacity, normCapacity)) {
return;
}
// 如果无法从当前线程的缓存中申请到small级别的内存,则尝试从smallSubpagePools中申请。
// 这里smallIdx()方法就是计算目标内存块是在smallSubpagePools中的第几号元素中的
tableIdx = smallIdx(normCapacity);
table = smallSubpagePools;
}
// 获取目标元素的头结点
final PoolSubpage<T> head = table[tableIdx];
// 这里需要注意的是,由于对head进行了加锁,而在同步代码块中判断了s != head,
// 也就是说PoolSubpage链表中是存在未使用的PoolSubpage的,因为如果该节点已经用完了,
// 其是会被移除当前链表的。也就是说只要s != head,那么这里的allocate()方法
// 就一定能够申请到所需要的内存块
synchronized (head) {
final PoolSubpage<T> s = head.next;
// s != head就证明当前PoolSubpage链表中存在可用的PoolSubpage,并且一定能够申请到内存,
// 因为已经耗尽的PoolSubpage是会从链表中移除的
if (s != head) {
// 从PoolSubpage中申请内存
long handle = s.allocate();
// 通过申请的内存对ByteBuf进行初始化
s.chunk.initBufWithSubpage(buf, null, handle, reqCapacity);
// 对tiny类型的申请数进行更新
incTinySmallAllocation(tiny);
return;
}
}
synchronized (this) {
// 走到这里,说明目标PoolSubpage链表中无法申请到目标内存块,因而就尝试从PoolChunk中申请
allocateNormal(buf, reqCapacity, normCapacity);
}
// 对tiny类型的申请数进行更新
incTinySmallAllocation(tiny);
return;
}
// 走到这里说明目标内存是大于8KB的,那么就判断目标内存是否大于16M,如果大于16M,
// 则不使用内存池对其进行管理,如果小于16M,则到PoolChunkList中进行内存申请
if (normCapacity <= chunkSize) {
// 小于16M,首先到当前线程的缓存中申请,如果申请到了则直接返回,如果没有申请到,
// 则到PoolChunkList中进行申请
if (cache.allocateNormal(this, buf, reqCapacity, normCapacity)) {
return;
}
synchronized (this) {
// 在当前线程的缓存中无法申请到足够的内存,因而尝试到PoolChunkList中申请内存
allocateNormal(buf, reqCapacity, normCapacity);
++allocationsNormal;
}
} else {
// 对于大于16M的内存,Netty不会对其进行维护,而是直接申请,然后返回给用户使用
allocateHuge(buf, reqCapacity);
}
}
上述代码就是PoolArena申请目标内存块的主要流程,首先会判断目标内存是在哪个内存层级的,比如tiny、small或者normal,然后根据目标层级的分配方式对目标内存进行扩容。接着首先会尝试从当前线程的缓存中申请目标内存,如果能够申请到,则直接返回,如果不能申请到,则在当前层级中申请。对于tiny和small层级的内存申请,如果无法申请到,则会将申请动作交由PoolChunkList进行。这里我们主要看一下PoolArena是如何在PoolChunkList中申请内存的,如下是allocateNormal()的源码:
private void allocateNormal(PooledByteBuf<T> buf, int reqCapacity, int normCapacity) {
// 将申请动作按照q050->q025->q000->qInit->q075的顺序依次交由各个PoolChunkList进行处理,
// 如果在对应的PoolChunkList中申请到了内存,则直接返回
if (q050.allocate(buf, reqCapacity, normCapacity)
|| q025.allocate(buf, reqCapacity, normCapacity)
|| q000.allocate(buf, reqCapacity, normCapacity)
|| qInit.allocate(buf, reqCapacity, normCapacity)
|| q075.allocate(buf, reqCapacity, normCapacity)) {
return;
}
// 由于在目标PoolChunkList中无法申请到内存,因而这里直接创建一个PoolChunk,
// 然后在该PoolChunk中申请目标内存,最后将该PoolChunk添加到qInit中
PoolChunk<T> c = newChunk(pageSize, maxOrder, pageShifts, chunkSize);
boolean success = c.allocate(buf, reqCapacity, normCapacity);
qInit.add(c);
}
这里申请过程比较简单,首先是按照一定的顺序分别在各个PoolChunkList中申请内存,如果申请到了,则直接返回,如果没申请到,则创建一个PoolChunk进行申请。这里需要说明的是,在PoolChunkList中申请内存时,本质上还是将申请动作交由其内部的PoolChunk进行申请,如果申请到了,其还会判断当前PoolChunk的内存使用率是否超过了当前PoolChunkList的阈值,如果超过了,则会将其移动到下一PoolChunkList中。
内存释放
对于内存的释放,PoolArena主要是分为两种情况,即池化和非池化,如果是非池化,则会直接销毁目标内存块,如果是池化的,则会将其添加到当前线程的缓存中。如下是free()方法的源码:
void free(PoolChunk<T> chunk, ByteBuffer nioBuffer, long handle, int normCapacity,
PoolThreadCache cache) {
// 如果是非池化的,则直接销毁目标内存块,并且更新相关的数据
if (chunk.unpooled) {
int size = chunk.chunkSize();
destroyChunk(chunk);
activeBytesHuge.add(-size);
deallocationsHuge.increment();
} else {
// 如果是池化的,首先判断其是哪种类型的,即tiny,small或者normal,
// 然后将其交由当前线程的缓存进行处理,如果添加成功,则直接返回
SizeClass sizeClass = sizeClass(normCapacity);
if (cache != null && cache.add(this, chunk, nioBuffer, handle,
normCapacity, sizeClass)) {
return;
}
// 如果当前线程的缓存已满,则将目标内存块返还给公共内存块进行处理
freeChunk(chunk, handle, sizeClass, nioBuffer);
}
}
PoolChunk
通过对PoolArena的分析,我们知道最终对池内存块的申请会落在PoolChunk这个数据结构上,PoolChunk是Netty内存池中的重要组成部分,其作用主要在于维护了一个较大的内存块,当需要申请超过8KB的内存时,就会从PoolChunk中获取。
PoolChunk整体结构
PoolChunk默认申请的内存大小是16M,在结构上,其会将这16M内存组织成为一颗平衡二叉树,二叉树的每一层每个节点所代表的内存大小都是均等的,并且每一层节点所代表的内存大小总和加起来都是16M,整颗二叉树的总层数为12,层号从0开始。
其结构示意图如下:
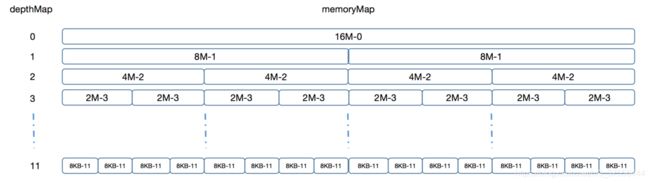
关于上图,我们主要有如下几点需要说明:
- 一个PoolChunk占用的总内存是16M,其会按照当前二叉树所在的层级将16M内存进行划分,比如第1层将其划分为两个8M,第二层将其划分为4个4M等等,整颗二叉树最多有12层,因而每个叶节点的内存大小为8KB,也就是说,PoolChunk能够分配的内存最少为8KB,最多为16M;
- 可以看出,图中的二叉树叶子节点有2^11=2048个,因而整颗树的节点数有4095个。PoolChunk将这4095个节点平铺到了一个长度为4096的数组上,其第1号位存储了0,第23号位存储了1,第47号位存储了2,依次类推,整体上其实就是将这棵以层号表示的二叉树存入了一个数组中。这里的数组就是左边的depthMap,通过这棵二叉树,可以快速通过下标得到其层数,比如2048号位置的值为11,表示其在二叉树的第11层。
depthMap的结构如下图所示:

在图中二叉树的每个节点上,我们为当前节点所代表的内存大小标记了一个数字,这个数字其实就表示了当前节点所能够分配的内存大小,比如0代表16M,1代表了8M等等。这些数字就是由memoryMap来存储的,表示二叉树中每个节点代表的可分配内存大小,其数据结构与depthMap完全一样。图中,每一个父节点所代表的可分配内存大小都等于两个子节点的和,如果某个子节点的内存已经被分配了,那么该节点就会被标记为12,表示已分配,而它们的父节点则会被更新为另一个子节点的值,表示父节点可分配的内存就是其两个子节点所能提供的内存之和;
内存申请过程举例
对于PoolChunk对内存的申请和释放的整体流程,我们以申请的是9KB的内存进行讲述:
- 首先将9KB=9126拓展为大于其的第一个2的指数,也就是2«13=16384,由于叶节点8KB=2 « 12,其对应的层数为11,因而16384所在的层数为10,也就是说从内存池中找到一个第10层的未分配的节点即可;
- 得出目标节点在第10层后,这里就会从头结点开始比较,如果头结点所存储的值比10要小,那么就说明其有足够的内存用于分配目标内存,然后就会将其左子节点与10进行比较,如果左子节点比10要大(一般此时左子节点已经被分配出去了,其值为12,因而会比10大<注意这里值越大说明剩余的内存越小>),那么就会将右子节点与10进行比较,此时右子节点肯定比10小,那么就会从右子节点的左子节点开始继续上面的比较;
- 当比较到某一个时刻,有一个节点的数字与10相等,就说明这个位置就是我们所需要的内存块,那么就会将其标注为12(为什么标注为12?因为这课二叉树最多只有12层,而标记节点内存大小的index是从0开始的),然后递归的回溯,将其父节点所代表的内存值更新为其另一个子节点的值:

- 关于内存的分配,这里需要说明的最后一个问题就是,通过上面的计算方式,我们可以找到一个节点作为我们目标要分配的节点,此时就需要将此节点所代表的内存起始地址和长度返回。由于我们只有整个PoolChunk所申请的16M内存的地址值,而通过目标节点所在的层号和其是该层第几个节点就可以计算出该节点相对于整个内存块起始地址的偏移量,从而就可以得到该节点的起始地址值;关于该节点所占用的内存长度,直观的感觉可以理解为一个映射,比如11代表8KB长度,10代表16KB长度等等。当然这里的起始地址和偏移量的计算,PoolChunk并不是通过这种算法直接实现的,而是通过更高效的位运算来实现的。
PoolChunk主要属性
在阅读Netty内存池源码的时候,相信大多数读者都会被其各种纷繁复杂的属性所混淆,从而感觉阅读起来艰涩难懂。这里我们单独将其属性列出来,以方便读者在阅读源码时能够更快的理解其各个属性的作用。
// netty内存池总的数据结构,该类我们后续会对其进行讲解
final PoolArena<T> arena;
// 当前申请的内存块,比如对于堆内存,T就是一个byte数组,对于直接内存,T就是ByteBuffer,
// 但无论是哪种形式,其内存大小都默认是16M
final T memory;
// 指定当前是否使用内存池的方式进行管理
final boolean unpooled;
// 表示当前申请的内存块中有多大一部分是用于站位使用的,整个内存块的大小是16M+offset,默认该值为0
final int offset;
// 存储了当前代表内存池的二叉树的各个节点的内存使用情况,该数组长度为4096,二叉树的头结点在该数组的
// 第1号位,存储的值为0;两个一级子节点在该数组的第2号位和3号位,存储的值为1,依次类推。二叉树的叶节点
// 个数为2048,因而总节点数为4095。在进行内存分配时,会从头结点开始比较,然后比较左子节点,然后比较右
// 子节点,直到找到能够代表目标内存块的节点。当某个节点所代表的内存被申请之后,该节点的值就会被标记为12,
// 表示该节点已经被占用
private final byte[] memoryMap;
// 这里depthMap存储的数据结构与memoryMap是完全一样的,只不过其值在初始化之后一直不会发生变化。
// 该数据的主要作用在于通过目标索引位置值找到其在整棵树中对应的层数
private final byte[] depthMap;
// 这里每一个PoolSubPage代表了二叉树的一个叶节点,也就是说,当二叉树叶节点内存被分配之后,
// 其会使用一个PoolSubPage对其进行封装
private final PoolSubpage<T>[] subpages;
// 其值为-8192,二进制表示为11111111111111111110000000000000,它的后面0的个数正好为12,而2^12=8192,
// 因而将其与用户希望申请的内存大小进行“与操作“,如果其值不为0,就表示用户希望申请的内存在8192之上,从而
// 就可以快速判断其是在通过PoolSubPage的方式进行申请还是通过内存计算的方式。
private final int subpageOverflowMask;
// 记录了每个业节点内存的大小,默认为8192,即8KB
private final int pageSize;
// 页节点所代表的偏移量,默认为13,主要作用是计算目标内存在内存池中是在哪个层中,具体的计算公式为:
// int d = maxOrder - (log2(normCapacity) - pageShifts);
// 比如9KB,经过log2(9KB)得到14,maxOrder为11,计算就得到10,表示9KB内存在内存池中为第10层的数据
private final int pageShifts;
// 默认为11,表示当前你最大的层数
private final int maxOrder;
// 记录了当前整个PoolChunk申请的内存大小,默认为16M
private final int chunkSize;
// 将chunkSize取2的对数,默认为24
private final int log2ChunkSize;
// 指定了代表叶节点的PoolSubPage数组所需要初始化的长度
private final int maxSubpageAllocs;
// 指定了某个节点如果已经被申请,那么其值将被标记为unusable所指定的值
private final byte unusable;
// 对创建的ByteBuffer进行缓存的一个队列
private final Deque<ByteBuffer> cachedNioBuffers;
// 记录了当前PoolChunk中还剩余的可申请的字节数
private int freeBytes;
// 在Netty的内存池中,所有的PoolChunk都是由当前PoolChunkList进行组织的,
// 关于PoolChunkList和其前置节点以及后置节点我们会在后续进行讲解,本文主要专注于PoolChunk的讲解
PoolChunkList<T> parent;
// 在PoolChunkList中当前PoolChunk的前置节点
PoolChunk<T> prev;
// 在PoolChunkList中当前PoolChunk的后置节点
PoolChunk<T> next;
源码
关于PoolChunk的功能,我们这里主要对其内存的分配和回收过程进行讲解。
内存分配
PoolChunk的内存分配主要在其allocate()方法中,而分配的整体描述前面已经进行了讲解,这里不再赘述,我们直接进入其源码进行阅读:
boolean allocate(PooledByteBuf<T> buf, int reqCapacity, int normCapacity) {
final long handle;
// 这里subpageOverflowMask=-8192,通过判断的结果可以看出目标容量是否小于8KB。
// 在下面的两个分支逻辑中,都会返回一个long型的handle,一个long占8个字节,其由低位的4个字节和高位的
// 4个字节组成,低位的4个字节表示当前normCapacity分配的内存在PoolChunk中所分配的节点在整个memoryMap
// 数组中的下标索引;而高位的4个字节则表示当前需要分配的内存在PoolSubPage所代表的8KB内存中的位图索引。
// 对于大于8KB的内存分配,由于其不会使用PoolSubPage来存储目标内存,因而高位四个字节的位图索引为0,
// 而低位的4个字节则还是表示目标内存节点在memoryMap中的位置索引;
// 对于低于8KB的内存分配,其会使用一个PoolSubPage来表示整个8KB内存,因而需要一个位图索引来表示目标内存
// 也即normCapacity会占用PoolSubPage中的哪一部分的内存。
if ((normCapacity & subpageOverflowMask) != 0) { // >= pageSize
// 申请高于8KB的内存
handle = allocateRun(normCapacity);
} else {
// 申请低于8KB的内存
handle = allocateSubpage(normCapacity);
}
// 如果返回的handle小于0,则表示要申请的内存大小超过了当前PoolChunk所能够申请的最大大小,也即16M,
// 因而返回false,外部代码则会直接申请目标内存,而不由当前PoolChunk处理
if (handle < 0) {
return false;
}
// 这里会从缓存的ByteBuf对象池中获取一个ByteBuf对象,不存在则返回null
ByteBuffer nioBuffer = cachedNioBuffers != null ? cachedNioBuffers.pollLast() : null;
// 通过申请到的内存数据对获取到的ByteBuf对象进行初始化,如果ByteBuf为null,则创建一个新的然后进行初始化
initBuf(buf, nioBuffer, handle, reqCapacity);
return true;
}
可以看到对于内存的分配,主要会判断其是否大于8KB,如果大于8KB,则会直接在PoolChunk的二叉树中年进行分配,如果小于8KB,则会直接申请一个8KB的内存,然后将8KB的内存交由一个PoolSubpage进行维护。关于PoolSubpage的实现原理,我们后续会进行讲解,这里我们只是对其进行简单的讲解,以帮助读者理解位图索引的概念。当我们从PoolChunk的二叉树中申请到了8KB内存之后,会将其交由一个PoolSubpage进行维护。在PoolSubpage中,其会将整个内存块大小切分为一系列的16字节大小,这里就是8KB,也就是说,它将被切分为512 = 8KB / 16byte份。为了标识这每一份是否被占用,PoolSubpage使用了一个long型数组来表示,该数组的名称为bitmap,因而我们称其为位图数组。为了表示512份数据是否被占用,而一个long只有64个字节,因而这里就需要8 = 512 / 64个long来表示,因而这里使用的的是long型数组,而不是单独的一个long字段。long型的handle用来表示申请的内存在netty内存池索引,一个long占8个字节,其由低位的4个字节和高位的4个字节组成,低位的4个字节表示当前normCapacity分配的内存在PoolChunk中所分配的节点在整个memoryMap数组中的下标索引;而高位的4个字节则表示当前需要分配的内存在PoolSubPage所代表的8KB内存中的位图索引。因而这里只需要一个长整型的handle即可表示当前申请到的内存在整个内存池中的位置,以及在PoolSubpage中的位置。
allocateRun
private long allocateRun(int normCapacity) {
// 这里maxOrder为11,表示整棵树最大的层数,log2(normCapacity)会将申请的目标内存大小转换为大于该大小的
// 第一个2的指数次幂数然后取2的对数的形式,比如log2(9KB)转换之后为14,这是因为大于9KB的第一个2的指数
// 次幂为16384,将其取2的对数后为14。pageShifts默认为13,这里整个表达式的目的就是快速计算出申请目标
// 内存(normCapacity)需要对应的层数。
int d = maxOrder - (log2(normCapacity) - pageShifts);
// 通过前面讲的递归方式从先父节点,然后左子节点,接着右子节点的方式依次判断其是否与目标层数相等,
// 如果相等,则会将该节点所对应的在memoryMap数组中的位置索引返回
int id = allocateNode(d);
// 如果返回值小于0,则说明在当前PoolChunk中无法分配目标大小的内存,这一般是由于目标内存大于16M,
// 或者当前PoolChunk已经分配了过多的内存,剩余可分配的内存不足以分配目标内存大小导致的
if (id < 0) {
return id;
}
// 更新剩余可分配内存的值
freeBytes -= runLength(id);
return id;
}
这里allocateRun()方法首先会计算目标内存所对应的二叉树层数,然后递归的在二叉树中查找是否有对应的节点,找到了则直接返回。这里我们继续看allocateNode()方法看其是如何对二叉树进行递归遍历的:
private int allocateNode(int d) {
int id = 1;
int initial = -(1 << d);
// 获取memoryMap中索引为id的位置的数据层数,初始时获取的就是根节点的层数
byte val = value(id);
// 如果更节点的层数值都比d要大,说明当前PoolChunk中没有足够的内存用于分配目标内存,直接返回-1
if (val > d) {
return -1;
}
// 这里就是通过比较当前节点的值是否比目标节点的值要小,如果要小,则说明当前节点所代表的子树是能够
// 分配目标内存大小的,则会继续遍历其左子节点,然后遍历右子节点
while (val < d || (id & initial) == 0) {
id <<= 1;
val = value(id);
// 这里val > d其实就是表示当前节点的数值比目标数值要大,也就是说当前节点是没法申请到目标容量的内存,
// 那么就会执行 id ^= 1,其实也就是将id切换到当前节点的兄弟节点,本质上其实就是从二叉树的
// 左子节点开始查找,如果左子节点无法分配目标大小的内存,那么就到右子节点进行查找
if (val > d) {
id ^= 1;
val = value(id);
}
}
// 当找到之后,获取该节点所在的层数
byte value = value(id);
// 将该memoryMap中该节点位置的值设置为unusable=12,表示其已经被占用
setValue(id, unusable);
// 递归的更新父节点的值,使其继续保持”父节点存储的层数所代表的内存大小是未分配的
// 子节点的层数所代表的内存之和“的语义。
updateParentsAlloc(id);
return id;
}
这里allocateNode()方法主要逻辑就是查找目标内存在memoryMap中的索引下标值,并且对所申请的节点的父节点值进行更新。下面我们来看看allocateSubpage()的实现原理:
private long allocateSubpage(int normCapacity) {
// 这里其实也是与PoolThreadCache中存储PoolSubpage的方式相同,也是采用分层的方式进行存储的,
// 具体是取目标数组中哪一个元素的PoolSubpage则是根据目标容量normCapacity来进行的。
PoolSubpage<T> head = arena.findSubpagePoolHead(normCapacity);
int d = maxOrder;
synchronized (head) {
// 这里调用allocateNode()方法在二叉树中查找时,传入的d值maxOrder=11,也就是说,其本身就是
// 直接在叶节点上查找可用的叶节点位置
int id = allocateNode(d);
// 小于0说明没有符合条件的内存块
if (id < 0) {
return id;
}
final PoolSubpage<T>[] subpages = this.subpages;
final int pageSize = this.pageSize;
freeBytes -= pageSize;
// 计算当前id对应的PoolSubpage数组中的位置
int subpageIdx = subpageIdx(id);
PoolSubpage<T> subpage = subpages[subpageIdx];
// 这里主要是通过一个PoolSubpage对申请到的内存块进行管理,具体的管理方式我们后续文章中会进行讲解。
if (subpage == null) {
// 这里runOffset()方法会返回该id在PoolChunk中维护的字节数组中的偏移量位置,
// normCapacity则记录了当前将要申请的内存大小;
// pageSize记录了每个页的大小,默认为8KB
subpage = new PoolSubpage<T>(head, this, id, runOffset(id), pageSize, normCapacity);
subpages[subpageIdx] = subpage;
} else {
subpage.init(head, normCapacity);
}
// 通过PoolSubpage申请一块内存,并且返回代表该内存块的位图索引,位图索引的具体计算方式,
// 我们前面已经简要讲述,详细的实现原理我们后面会进行讲解。
return subpage.allocate();
}
}
这里可以看到,allocateSubpage()方法主要是将申请到的8KB内存交由一个PoolSubpage进行管理,并且由其返回响应的位图索引。这里关于handle参数的产生方式已经讲解完成,关于allocate()方法中initBuf()方法的调用,其原理比较简单,本质上就是首先计算申请到的内存块的起始位置地址值,以及申请的内存块的长度,然后将其设置到一个ByteBuf对象中,以对其进行初始化,这里不再赘述其实现原理。
内存释放
关于内存释放的原理,其比较简单,通过前面的讲解,我们可以看到,内存的申请就是在主内存块中查找可以申请的内存块,然后将代表其位置的比如层号,或者位图索引标志为已经分配。那么这里的释放过程其实就是返回来,然后将这些标志进行重置。这里我们以直接内存(ByteBuffer)的释放过程讲解内存释放的源码:
void free(long handle, ByteBuffer nioBuffer) {
int memoryMapIdx = memoryMapIdx(handle); // 根据当前内存块在memoryMap数组中的位置
int bitmapIdx = bitmapIdx(handle); // 获取当前内存块的位图索引
// 如果位图索引不等于0,说明当前内存块是小于8KB的内存块,因而将其释放过程交由PoolSubpage进行
if (bitmapIdx != 0) {
PoolSubpage<T> subpage = subpages[subpageIdx(memoryMapIdx)];
PoolSubpage<T> head = arena.findSubpagePoolHead(subpage.elemSize);
synchronized (head) {
// 由PoolSubpage释放内存
if (subpage.free(head, bitmapIdx & 0x3FFFFFFF)) {
return;
}
}
}
// 走到这里说明需要释放的内存大小大于8KB,这里首先计算要释放的内存块的大小
freeBytes += runLength(memoryMapIdx);
// 将要释放的内存块所对应的二叉树的节点对应的值进行重置
setValue(memoryMapIdx, depth(memoryMapIdx));
// 将要释放的内存块所对应的二叉树的各级父节点的值进行更新
updateParentsFree(memoryMapIdx);
// 将创建的ByteBuf对象释放到缓存池中,以便下次申请时复用
if (nioBuffer != null && cachedNioBuffers != null &&
cachedNioBuffers.size() < PooledByteBufAllocator
.DEFAULT_MAX_CACHED_BYTEBUFFERS_PER_CHUNK) {
cachedNioBuffers.offer(nioBuffer);
}
}
可以看到,这里对内存的释放,主要是判断其是否小于8KB,如果低于8KB,则将其交由PoolSubpage进行处理,否则就通过二叉树的方式对其进行重置。
PoolSubpage
通过前面的分析我们已经知道,小于8k的内存分配都发生在PoolSubpage,可以把PoolSubpage看做PoolChunk的一个视图,专门用来管理小于8KB的内存。而对于低于8KB的内存,Netty也是将其分成了两种情况0~496byte和512byte~8KB。其中,0~496byte的内存是由一个名称为tinySubpagePools的PoolSubpage的数组维护的,512byte~8KB的内存则是由名称为smallSubpagePools的PoolSubpage数组来维护的。
tinySubpagePools和smallSubpagePools整体结构
这里我们直接查看这两个PoolSubpage数组的结构:

tinySubpagePools和smallSubpagePools在结构上都是由一个数组来实现的,只是tinySubpagePools的数组长度为32,但是其真正使用的只有其下标在1~31内的节点。而smallSubpagePools的数组长度为4,其每个节点都会使用;
在存储数据内存的划分上,图中,我们可以看到,两个数组的每个节点都是一个PoolSubpage的单向链表,而节点前面我们都使用了一个数字进行标注。这个数字的意思是,这个节点所对应的链表所能够申请的内存最大值,这样就可以达到将不同大小的内存申请进行了划分,并且加锁的时候可以减小锁的粒度,从而减小竞争。这里比如我们申请8byte的内存,那么其就会到tinySubpagePools的下标为1的链表中进行申请,需要注意的是,如果该下标位置的链表是空的,那么就会创建一个,但是一定会保证是在该下标处进行申请;
tinySubpagePools和smallSubpagePools的最大区别在于两者对于内存的划分。图中我们可以看到,tinySubpagePools的每个节点所指代的内存相差16byte,而smallSubpagePools的内存则是2的指数次幂;
在对内存的管理上,这里每一个PoolSubpage也都是维护的一个内存池,它们的大小永远都是8KB。这里比如tinySubpagePools的第1号位的每一个PoolSubpage,其能够申请的内存最大为16byte,由于每一个PoolSubpage的大小都为8KB,因而其链表中每个PoolSubpage都维护了8192 / 16 = 512个内存块;由比如smallSubpagePools的第2号位的每一个PoolSubpage,其能够申请的内存最大为2048byte,因而其链表中每一个PoolSubpage都维护了8192 / 2048 = 4个内存块;
内存申请过程举例
在进行内存申请时,用户会传入一个其所希望的内存大小,但实际获取的大小,Netty都会进行扩容,这里我们以50byte内存的申请为例进行讲解:
- 首先Netty会判断目标内存,这里为50byte,是否小于8KB,只有小于8KB的内存才会交由tinySubpagePools和smallSubpagePools进行申请;进行了如此判断之后,Netty还会判断其是否小于512byte,从而判断其是应该从tinySubpagePools还是从smallSubpagePools中进行申请,这里50小于512,因而是从tinySubpagePools中进行申请;
- 将目标内存进行扩容,因为已经知道其是从tinySubpagePools中进行申请,由于tinySubpagePools中的内存阶梯是16的倍数,因而会将目标内存扩容为大于其值的第一个16的倍数,这里也就是64。如果目标内存是在smallSubpagePools中,那么就会将其扩容为大于该值的第一个2的指数次幂;
- 根据扩容后的大小计算出其在数组中的位置,这里就是64 / 16 = 4(在Netty源码中是直接将目标内存向右移动4位,即64 »> 4,这样也能达到除以16的目的);
- 在目标链表中找到第一个PoolSubpage,从其剩余的内存中划分目标内存块,这里需要注意的是,第一个PoolSubpage中是一定会存在可划分的内存块的,因为如果链表中某个PoolSubpage中没有剩余的可划分内存块时,其将会被从当前链表中移除。关于PoolSubpage内存块的划分,后面会进行详细讲解。
位图索引
对于PoolSubpage的实现原理,其内部本质上是使用一个位图索引来表征某个内存块是否已经被占用了的。前面我们讲到,每个PoolSubpage的总内存大小都是8192byte,这里我们以tinySubpagePools的第1号位的大小为16字节的PoolSubpage为例进行讲解(其实从这里就可以看出,前面我们图中数组前面的数字就是表示当前节点链表中PoolSubpage所划分的内存块的大小)。
由于每个内存块大小为16字节,而总大小为8192字节,因而总会有8192 / 16 = 512个内存块。为了对这些内存块进行标记,那么就需要一个长度为512的二进制位图索引进行表征。Netty并没有使用jdk提供的BitMap这个类,而是使用了一个long型的数组。由于一个long占用的字节数为64,因而总共需要512 / 64 = 8个long型数字来表示。这也就是PoolSubpage中的long[] bitmap属性的作用。下图表示了PoolSubpage使用位图索引表示每个内存块是否被使用的一个示意图:

这里需要说明的是,我们这里是以每个内存块的大小为16为例进行讲解的,而16是PoolSubpage所能维护的最小内存块,对于其他大小的内存块,其个数是比512要小的,但是PoolSubpage始终会声明一个长度为8的long型数组,并且声明一个bitmapLength来记录当前PoolSubpage中有几个long是用于标志内存块使用情况。
源码
对于PoolSubpage的实现原理,我们这里首先对其各个属性进行讲解:
// 记录当前PoolSubpage的8KB内存块是从哪一个PoolChunk中申请到的
final PoolChunk<T> chunk;
// 当前PoolSubpage申请的8KB内存在PoolChunk中memoryMap中的下标索引
private final int memoryMapIdx;
// 当前PoolSubpage占用的8KB内存在PoolChunk中相对于叶节点的起始点的偏移量
private final int runOffset;
// 当前PoolSubpage的页大小,默认为8KB
private final int pageSize;
// 存储当前PoolSubpage中各个内存块的使用情况
private final long[] bitmap;
PoolSubpage<T> prev; // 指向前置节点的指针
PoolSubpage<T> next; // 指向后置节点的指针
boolean doNotDestroy; // 表征当前PoolSubpage是否已经被销毁了
int elemSize; // 表征每个内存块的大小,比如我们这里的就是16
private int maxNumElems; // 记录内存块的总个数
private int bitmapLength; // 记录总共可使用的bitmap数组的元素的个数
// 记录下一个可用的节点,初始为0,只要在该PoolSubpage中申请过一次内存,就会更新为-1,
// 然后一直不会发生变化
private int nextAvail;
// 剩余可用的内存块的个数
private int numAvail;
对于各个属性的初始化,我们可以通过构造函数进行讲解,如下是其构造函数源码:
PoolSubpage(PoolSubpage<T> head, PoolChunk<T> chunk, int memoryMapIdx, int runOffset,
int pageSize, int elemSize) {
this.chunk = chunk;
this.memoryMapIdx = memoryMapIdx;
this.runOffset = runOffset;
this.pageSize = pageSize; // 初始化当前PoolSubpage总内存大小,默认为8KB
// 计算bitmap长度,这里pageSize >>> 10其实就是将pageSize / 1024,得到的是8,
// 从这里就可以看出,无论内存块的大小是多少,这里的bitmap长度永远是8,因为pageSize始终是不变的
bitmap = new long[pageSize >>> 10];
// 对其余的属性进行初始化
init(head, elemSize);
}
void init(PoolSubpage<T> head, int elemSize) {
doNotDestroy = true;
// elemSize记录了当前内存块的大小
this.elemSize = elemSize;
if (elemSize != 0) {
// 初始时,numAvail记录了可使用的内存块个数,其个数可以通过pageSize / elemSize计算,
// 我们这里就是8192 / 16 = 512。maxNumElems指的是最大可使用的内存块个数,
// 初始时其是与可用内存块个数一致的。
maxNumElems = numAvail = pageSize / elemSize;
nextAvail = 0; // 初始时,nextAvail是0
// 这里bitmapLength记录了可以使用的bitmap的元素个数,这是因为,我们示例使用的内存块大小是16,
// 因而其总共有512个内存块,需要8个long才能记录,但是对于一些大小更大的内存块,比如smallSubpagePools
// 中内存块为1024字节大小,那么其只有8192 / 1024 = 8个内存块,也就只需要一个long就可以表示,
// 此时bitmapLength就是8。
// 这里的计算方式应该是bitmapLength = maxNumElems / 64,因为64是一个long的总字节数,
// 但是Netty将其进行了优化,也就是这里的maxNumElems >>> 6,这是因为2的6次方正好为64
bitmapLength = maxNumElems >>> 6;
// 这里(maxNumElems & 63) != 0就是判断元素个数是否小于64,如果小于,则需要将bitmapLegth加一。
// 这是因为如果其小于64,前面一步的位移操作结果为0,但其还是需要一个long来记录
if ((maxNumElems & 63) != 0) {
bitmapLength++;
}
// 对bitmap数组的值进行初始化
for (int i = 0; i < bitmapLength; i++) {
bitmap[i] = 0;
}
}
// 将当前PoolSubpage添加到PoolSubpage的链表中,也就是最开始图中的链表
addToPool(head);
}
内存申请
这里对于PoolSubpage的初始化主要是对bitmap、numAvail、bitmapLength的初始化,下面我们看看其是如何通过这些属性来从PoolSubpage中申请内存的:
// 对于allocate()方法,其没有传入任何参数是因为当前PoolSubpage所能申请的内存块大小在构造方法中
// 已经通过elemSize指定了。
// 当前方法返回的是一个long型整数,这里是将要申请的内存块使用了一个long型变量进行表征了。由于一个内存块
// 是否使用是通过一个long型整数表示的,因而,如果想要表征当前申请到的内存块是这个long型整数中的哪一位,
// 只需要一个最大为63的整数即可(long最多为64位),这只需要long型数的低6位就可以表示,由于我们使用的是一个
// long型数组,因而还需要记录当前是在数组中第几个元素,由于数组长度最多为8,因而对于返回值的7~10位则是记录
// 了当前申请的内存块是在bitmap数组的第几个元素中。总结来说,返回值的long型数的高32位中的低6位
// 记录了当前申请的是是bitmap中某个long的第几个位置的内存块,而高32位的7~10位则记录了申请的是bitmap数组
// 中的第几号元素。
// 这里说返回值的高32位是因为其低32位记录了当前8KB内存块是在PoolChunk中具体的位置,关于这一块的算法
// 读者可以阅读本人前面对PoolChunk进行讲解的文章
long allocate() {
// 如果elemSize为0,则直接返回0
if (elemSize == 0) {
return toHandle(0);
}
// 如果当前PoolSubpage没有可用的元素,或者已经被销毁了,则返回-1
if (numAvail == 0 || !doNotDestroy) {
return -1;
}
// 计算下一个可用的内存块的位置
final int bitmapIdx = getNextAvail();
int q = bitmapIdx >>> 6; // 获取该内存块是bitmap数组中的第几号元素
int r = bitmapIdx & 63; // 获取该内存块是bitmap数组中q号位元素的第多少位
bitmap[q] |= 1L << r; // 将bitmap数组中q号元素的目标内存块位置标记为1,表示已经使用
// 如果当前PoolSubpage中可用的内存块为0,则将其从链表中移除
if (--numAvail == 0) {
removeFromPool();
}
// 将得到的bitmapIdx放到返回值的高32位中
return toHandle(bitmapIdx);
}
这里allocate()方法首先会计算下一个可用的内存块的位置,然后将该位置标记为1,最后将得到的位置数据放到返回值的高32位中。这里我们继续看其是如何计算下一个可用的位置的,如下是getNextAvail()的源码:
private int getNextAvail() {
int nextAvail = this.nextAvail;
// 如果是第一次尝试获取数据,则直接返回bitmap第0号位置的long的第0号元素,
// 这里nextAvail初始时为0,在第一次申请之后就会变为-1,后面将不再发生变化,
// 通过该变量可以判断是否是第一次尝试申请内存
if (nextAvail >= 0) {
this.nextAvail = -1;
return nextAvail;
}
// 如果不是第一次申请内存,则在bitmap中进行遍历获取
return findNextAvail();
}
private int findNextAvail() {
final long[] bitmap = this.bitmap;
final int bitmapLength = this.bitmapLength;
// 这里的基本思路就是对bitmap数组进行遍历,首先判断其是否有未使用的内存是否全部被使用过
// 如果有未被使用的内存,那么就在该元素中找可用的内存块的位置
for (int i = 0; i < bitmapLength; i++) {
long bits = bitmap[i];
if (~bits != 0) { // 判断当前long型元素中是否有可用内存块
return findNextAvail0(i, bits);
}
}
return -1;
}
// 入参中i表示当前是bitmap数组中的第几个元素,bits表示该元素的值
private int findNextAvail0(int i, long bits) {
final int maxNumElems = this.maxNumElems;
final int baseVal = i << 6; // 这里baseVal就是将当前是第几号元素放到返回值的第7~10号位置上
// 对bits的0~63号位置进行遍历,判断其是否为0,为0表示该位置是可用内存块,从而将位置数据
// 和baseVal进行或操作,从而得到一个表征目标内存块位置的整型数据
for (int j = 0; j < 64; j++) {
if ((bits & 1) == 0) { // 判断当前位置是否为0,如果为0,则表示是目标内存块
int val = baseVal | j; // 将内存快的位置数据和其位置j进行或操作,从而得到返回值
if (val < maxNumElems) {
return val;
} else {
break;
}
}
bits >>>= 1; // 将bits不断的向右移位,以找到第一个为0的位置
}
return -1;
}
上面的查找过程非常的简单,其原理起始就是对bitmap数组进行遍历,首先判断当前元素是否有可用的内存块,如果有,则在该long型元素中进行遍历,找到第一个可用的内存块,最后将表征该内存块位置的整型数据返回。这里需要说明的是,上面判断bitmap中某个元素是否有可用内存块是使用的是~bits != 0来计算的,该算法的原理起始就是,如果一个long中所有的内存块都被申请了,那么这个long必然所有的位都为1,从整体上,这个long型数据的值就为-1,而将其取反~bits之后,值肯定就变为了0,因而这里只需要判断其取反之后是否等于0即可判断当前long型元素中是否有可用的内存块。
内存释放
下面我们继续看PoolSubpage是如何对内存进行释放的,如下是free()方法的源码:
boolean free(PoolSubpage<T> head, int bitmapIdx) {
if (elemSize == 0) {
return true;
}
// 获取当前需要释放的内存块是在bitmap中的第几号元素
int q = bitmapIdx >>> 6;
// 获取当前释放的内存块是在q号元素的long型数的第几位
int r = bitmapIdx & 63;
// 将目标位置标记为0,表示可使用状态
bitmap[q] ^= 1L << r;
// 设置下一个可使用的数据
setNextAvail(bitmapIdx);
// numAvail如果等于0,表示之前已经被移除链表了,因而这里释放后需要将其添加到链表中
if (numAvail++ == 0) {
addToPool(head);
return true;
}
// 如果可用的数量小于最大数量,则表示其还是在链表中,因而直接返回true
if (numAvail != maxNumElems) {
return true;
} else {
// else分支表示当前PoolSubpage中没有任何一个内存块被占用了
// 这里如果当前PoolSubpage的前置节点和后置节点相等,这表示其都是默认的head节点,也就是
// 说当前链表中只有一个可用于内存申请的节点,也就是当前PoolSubpage,这里就不会将其移除
if (prev == next) {
return true;
}
// 如果有多个节点,则将当前PoolSubpage移除
doNotDestroy = false;
removeFromPool();
return false;
}
}
可以看到,对于free()操作,主要是将目标位置标记为0,然后设置相关属性,并且判断是否需要将当前PoolSubpage添加到链表中或者从链表移除。
PoolThreadCache
PoolThreadCahche是Netty内存管理中能够实现高效内存申请和释放的一个重要原因,Netty会为每一个线程都维护一个PoolThreadCache对象,当进行内存申请时,首先会尝试从PoolThreadCache中申请,如果无法从中申请到,则会尝试从Netty的公共内存池中申请。本文首先会对PoolThreadCache的数据结构进行讲解,然后会介绍Netty是如何初始化PoolThreadCache的,最后会介绍如何在PoolThreadCache中申请内存和如何将内存释放到PoolThreadCache中。
PoolThreadCache数据结构
PoolThreadCache的数据结构与PoolArena的主要属性结构非常相似,但细微位置有很大的不同。在PoolThreadCache中,其维护了三个数组(我们以直接内存的缓存方式为例进行讲解),如下所示:
// 存储tiny类型的内存缓存,该数组长度为32,其中只有下标为1~31的元素缓存了有效数据,第0号位空置。
// 这里内存大小的存储方式也与PoolSubpage类似,数组的每一号元素都存储了不同等级的内存块,每个等级的
// 内存块的内存大小差值为16byte,比如第1号位维护了大小为16byte的内存块,第二号为维护了大小为32byte的
// 内存块,依次类推,第31号位维护了大小为496byte的内存块。
private final MemoryRegionCache<ByteBuffer>[] tinySubPageDirectCaches;
// 存储small类型的内存缓存,该数组长度为4,数组中每个元素中维护的内存块大小也是成等级递增的,并且这里
// 的递增方式是按照2的指数次幂进行的,比如第0号为维护的是大小为512byte的内存块,第1号位维护的是大小为
// 1024byte的内存块,第2号位维护的是大小为2048byte的内存块,第3号位维护的是大小为4096byte的内存块
private final MemoryRegionCache<ByteBuffer>[] smallSubPageDirectCaches;
// 存储normal类型的内存缓存。需要注意的是,这里虽说是维护的normal类型的缓存,但是其只维护2<<13,2<<14
// 和2<<15三个大小的内存块,而该数组的大小也正好为3,因而这三个大小的内存块将被依次放置在该数组中。
// 如果申请的目标内存大于2<<15,那么Netty会将申请动作交由PoolArena进行。
private final MemoryRegionCache<ByteBuffer>[] normalDirectCaches;
这三个数组分别保存了tiny,small和normal类型的缓存数据,不同于PoolArena的使用PoolSubpage和PoolChunk进行内存的维护,这里都是使用MemoryRegionCache进行的。另外,在MemoryRegionCache中保存了一个有界队列(MPSC队列),对于tiny类型的缓存,该队列的长度为512,对于small类型的缓存,该队列的长度为256,对于normal类型的缓存,该队列的长度为64。在进行内存释放的时候,如果队列已经满了,那么就会将该内存块释放回PoolArena中。这里需要说明的是,这里的队列中的元素统一使用的是Entry这种数据结构,该结构的主要属性如下:
static final class Entry<T> {
// 用于循环利用当前Entry对象的处理器,该处理器的实现原理,我们后续将进行讲解
final Handle<Entry<?>> recyclerHandle;
// 记录了当前内存块是从哪一个PoolChunk中申请得来的
PoolChunk<T> chunk;
// 如果是直接内存,该属性记录了当前内存块所在的ByteBuffer对象
ByteBuffer nioBuffer;
// 由于当前申请的内存块在PoolChunk以及PoolSubpage中的位置是可以通过一个长整型参数来表示的,
// 这个长整型参数就是这里的handle,因而这里直接将其记录下来,以便后续需要将当前内存块释放到
// PoolArena中时,能够快速获取其所在的位置
long handle = -1;
}
PoolThreadCache中维护每一个内存块最终都是使用的一个Entry对象来进行的,从上面的属性可以看出,记录该内存块最重要的属性是chunk和handle,chunk记录了当前内存块所在的PoolChunk对象,而handle则记录了当前内存块是在PoolChunk和PoolSubpage中的哪个位置。
下面我们通过一幅图来对PoolThreadCache的数据结构进行一个整体的演示:

如上图所示展示的就是PoolThreadCache的结构示意图。从图中可以看出在一个PoolThreadCache中,主要有三个MemoryRegionCache数组用于存储tiny,small和normal类型的内存块。每个MemoryRegionCache中有一个队列,队列中的元素类型为Entry。Entry的作用就是存储缓存的内存块的,其存储的方式主要是通过记录当前内存块所在的PoolChunk和标志其在PoolChunk中位置的handle参数。对于不同类型的数组,队列的长度是不一样的,tiny类型的是512,small类型的是256,normal类型的则是64。
PoolThreadCache初始化
对于PoolThreadCache的初始化,这里单独拿出来讲解的原因是,其初始化过程是与PoolThreadLocalCache所绑定的。PoolThreadLocalCache的作用与Java中的ThreadLocal的作用非常类似,其有一个initialValue()方法,用于在无法从PoolThreadLocalCache中获取数据时,通过调用该方法初始化一个。另外其提供了一个get()方法和和remove()方法,分别用于从PoolThreadLocalCache中将当前绑定的数据给清除。这里我们首先看看获取PoolThreadCache的入口代码:
@Override
protected ByteBuf newDirectBuffer(int initialCapacity, int maxCapacity) {
// 从PoolThreadLocalCache中尝试获取一个PoolThreadCache对象,
// 如果不存在,则自行初始化一个返回
PoolThreadCache cache = threadCache.get();
// 由于当前方法是需要返回一个direct buffer,因而这里直接使用cache中的directArena
PoolArena<ByteBuffer> directArena = cache.directArena;
final ByteBuf buf;
if (directArena != null) {
// 如果directArena不为空,则直接调用其allocate()方法申请内存
buf = directArena.allocate(cache, initialCapacity, maxCapacity);
} else {
// 如果当前缓存中由于某种原因无法获取到directArena,则直接创建一个存有直接内存的ByteBuf,
// 一般情况下不会走到这一步
buf = PlatformDependent.hasUnsafe() ?
UnsafeByteBufUtil.newUnsafeDirectByteBuf(this, initialCapacity, maxCapacity) :
new UnpooledDirectByteBuf(this, initialCapacity, maxCapacity);
}
// 为ByteBuf设置内存泄露检测功能
return toLeakAwareBuffer(buf);
}
从上面的代码中可以看出,在最开始的时候,就会通过PoolThreadLocalCache尝试获取一个PoolThreadCache对象,如果不存在,其会自行初始化一个。这里我们直接看其是如何初始化的,如下是PoolThreadLocalCache.initialValue()方法的源码:
@Override
protected synchronized PoolThreadCache initialValue() {
// 这里leastUsedArena()就是获取对应的PoolArena数组中最少被使用的那个Arena,将其返回。
// 这里的判断方式是通过比较PoolArena.numThreadCaches属性来进行的,该属性记录了当前PoolArena被
// 多少个线程所占用了。这里采用的思想就是,找到最少被使用的那个PoolArena,将其存入新的线程缓存中
final PoolArena<byte[]> heapArena = leastUsedArena(heapArenas);
final PoolArena<ByteBuffer> directArena = leastUsedArena(directArenas);
Thread current = Thread.currentThread();
// 只有在指定了为每个线程使用缓存,或者当前线程是FastThreadLocalThread的子类型时,才会使用线程缓存
if (useCacheForAllThreads || current instanceof FastThreadLocalThread) {
return new PoolThreadCache(
heapArena, directArena, tinyCacheSize, smallCacheSize, normalCacheSize,
DEFAULT_MAX_CACHED_BUFFER_CAPACITY, DEFAULT_CACHE_TRIM_INTERVAL);
}
// 如果指定了不使用缓存,或者线程换粗对象不是FastThreadLocalThread类型的,则创建一个PoolThreadCache
// 对象,该对象中是不做任何缓存的,因为初始化数据都是0
return new PoolThreadCache(heapArena, directArena, 0, 0, 0, 0, 0);
}
private <T> PoolArena<T> leastUsedArena(PoolArena<T>[] arenas) {
if (arenas == null || arenas.length == 0) {
return null;
}
// 在PoolArena数组中找到被最少线程占用的对象,将其返回。这样做的目的是,由于内存池是多个线程都可以
// 访问的公共区域,因而当这里就需要对内存池进行划分,以减少线程之间的竞争。
PoolArena<T> minArena = arenas[0];
for (int i = 1; i < arenas.length; i++) {
PoolArena<T> arena = arenas[i];
if (arena.numThreadCaches.get() < minArena.numThreadCaches.get()) {
minArena = arena;
}
}
return minArena;
}
从上述代码可以看出,对于PoolThreadCache的初始化,其首先会查找PoolArena数组中被最少线程占用的那个arena,然后将其封装到一个新建的PoolThreadCache中。
内存申请
需要注意的是,PoolThreadCache申请内存并不是说其会创建一块内存,或者说其会到PoolArena中申请内存,而是指,其本身已经缓存有内存块,而当前申请的内存块大小正好与其一致,就会将该内存块返回;PoolThreadCache中的内存块都是在当前线程使用完创建的ByteBuf对象后,通过调用其release()方法释放内存时直接缓存到当前PoolThreadCache中的,其并不会直接将内存块返回给PoolArena。这里我们直接看一下其allocate()方法是如何实现的:
// 申请tiny类型的内存块
boolean allocateTiny(PoolArena<?> area, PooledByteBuf<?> buf, int reqCapacity, int normCapacity) {
return allocate(cacheForTiny(area, normCapacity), buf, reqCapacity);
}
// 申请small类型的内存块
boolean allocateSmall(PoolArena<?> area, PooledByteBuf<?> buf,
int reqCapacity, int normCapacity) {
return allocate(cacheForSmall(area, normCapacity), buf, reqCapacity);
}
// 申请normal类型的内存块
boolean allocateNormal(PoolArena<?> area, PooledByteBuf<?> buf,
int reqCapacity, int normCapacity) {
return allocate(cacheForNormal(area, normCapacity), buf, reqCapacity);
}
// 从MemoryRegionCache中申请内存
private boolean allocate(MemoryRegionCache<?> cache, PooledByteBuf buf, int reqCapacity) {
if (cache == null) {
return false;
}
// 从MemoryRegionCache中申请内存,本质上就是从其队列中申请,如果存在,则初始化申请到的内存块
boolean allocated = cache.allocate(buf, reqCapacity);
// 这里是如果当前PoolThreadCache中申请内存的次数达到了8192次,则对内存块进行一次trim()操作,
// 对使用较少的内存块,将其返还给PoolArena,以供给其他线程使用
if (++allocations >= freeSweepAllocationThreshold) {
allocations = 0;
trim();
}
return allocated;
}
这里对于内存块的申请,我们可以看到,PoolThreadCache是将其分为tiny,small和normal三种不同的方法来调用的,而具体大小的区分其实是在PoolArena中进行区分的(读者可以阅读本人前面的关于PoolArena介绍的文章)。在对应的内存数组中找到MemoryRegionCache对象之后,通过调用allocate()方法来申请内存,申请完之后还会检查当前缓存申请次数是否达到了8192次,达到了则对缓存中使用的内存块进行检测,将较少使用的内存块返还给PoolArena。这里我们首先看一下获取MemoryRegionCache的代码是如何实现的,也即cacheForTiny(),cacheForSmall()和cacheForNormal()的代码:
private MemoryRegionCache<?> cacheForTiny(PoolArena<?> area, int normCapacity) {
// 计算当前数组下标索引,由于tiny类型的内存块每一层级相差16byte,因而这里的计算方式就是
// 将目标内存大小除以16
int idx = PoolArena.tinyIdx(normCapacity);
// 返回tiny类型的数组中对应位置的MemoryRegionCache
if (area.isDirect()) {
return cache(tinySubPageDirectCaches, idx);
}
return cache(tinySubPageHeapCaches, idx);
}
private MemoryRegionCache<?> cacheForSmall(PoolArena<?> area, int normCapacity) {
// 计算当前数组下标的索引,由于small类型的内存块大小都是2的指数次幂,因而这里就是将目标内存大小
// 除以1024之后计算其偏移量
int idx = PoolArena.smallIdx(normCapacity);
// 返回small类型的数组中对应位置的MemoryRegionCache
if (area.isDirect()) {
return cache(smallSubPageDirectCaches, idx);
}
return cache(smallSubPageHeapCaches, idx);
}
private MemoryRegionCache<?> cacheForNormal(PoolArena<?> area, int normCapacity) {
// 对于normal类型的缓存,这里也是首先将其向右位移13位,也就是8192,然后取2的对数,这样就
// 可以得到其在数组中的位置,然后返回normal类型的数组中对应位置的MemoryRegionCache
if (area.isDirect()) {
int idx = log2(normCapacity >> numShiftsNormalDirect);
return cache(normalDirectCaches, idx);
}
int idx = log2(normCapacity >> numShiftsNormalHeap);
return cache(normalHeapCaches, idx);
}
这里对于数组位置的计算,主要是根据各个数组数据存储方式的不同而进行的,而它们最终都是通过一个MemoryRegionCache存储的,因而只需要返回该缓存对象即可。下面我们继续看一下MemoryRegionCache.allocate()方法是如何申请内存的:
public final boolean allocate(PooledByteBuf<T> buf, int reqCapacity) {
// 尝试从队列中获取,如果队列中不存在,说明没有对应的内存块,则返回false,表示申请失败
Entry<T> entry = queue.poll();
if (entry == null) {
return false;
}
// 走到这里说明队列中存在对应的内存块,那么通过其存储的Entry对象来初始化ByteBuf对象,
// 如此即表示申请内存成功
initBuf(entry.chunk, entry.nioBuffer, entry.handle, buf, reqCapacity);
// 对entry对象进行循环利用
entry.recycle();
// 更新当前已经申请的内存数量
++allocations;
return true;
}
可以看到,MemoryRegionCache申请内存的方式主要是从队列中取,如果取到了,则使用该内存块初始化一个ByteBuf对象。
前面我们讲到,PoolThreadCache会对其内存块使用次数进行计数,这么做的目的在于,如果一个ThreadPoolCache所缓存的内存块使用较少,那么就可以将其释放到PoolArena中,以便于其他线程可以申请使用。PoolThreadCache会在其内存总的申请次数达到8192时遍历其所有的MemoryRegionCache,然后调用其trim()方法进行内存释放,如下是该方法的源码:
public final void trim() {
// size表示当前MemoryRegionCache中队列的最大可存储容量,allocations表示当前MemoryRegionCache
// 的内存申请次数,size-allocations的含义就是判断当前申请的次数是否连队列的容量都没达到
int free = size - allocations;
allocations = 0;
// 如果申请的次数连队列的容量都没达到,则释放该内存块
if (free > 0) {
free(free);
}
}
private int free(int max) {
int numFreed = 0;
// 依次从队列中取出Entry数据,调用freeEntry()方法释放该Entry
for (; numFreed < max; numFreed++) {
Entry<T> entry = queue.poll();
if (entry != null) {
freeEntry(entry);
} else {
return numFreed;
}
}
return numFreed;
}
private void freeEntry(Entry entry) {
// 通过当前Entry中保存的PoolChunk和handle等数据释放当前内存块
PoolChunk chunk = entry.chunk;
long handle = entry.handle;
ByteBuffer nioBuffer = entry.nioBuffer;
entry.recycle();
chunk.arena.freeChunk(chunk, handle, sizeClass, nioBuffer);
}
内存释放
对于内存的释放,其原理比较简单,一般的释放内存的入口在ByteBuf对象中。当调用ByteBuf.release()方法的时候,其首先会将释放动作委托给PoolChunk的free()方法,PoolChunk则会判断当前是否是池化的ByteBuf,如果是池化的ByteBuf,则调用PoolThreadCache.add()方法将其添加到PoolThreadCache中,也就是说在释放内存时,其实际上是释放到当前线程的PoolThreadCache中的。如下是add()方法的源码:
boolean add(PoolArena<?> area, PoolChunk chunk, ByteBuffer nioBuffer,
long handle, int normCapacity, SizeClass sizeClass) {
// 通过当前释放的内存块的大小计算其应该放到哪个等级的MemoryRegionCache中
MemoryRegionCache<?> cache = cache(area, normCapacity, sizeClass);
if (cache == null) {
return false;
}
// 将内存块释放到目标MemoryRegionCache中
return cache.add(chunk, nioBuffer, handle);
}
public final boolean add(PoolChunk<T> chunk, ByteBuffer nioBuffer, long handle) {
// 这里会尝试从缓存中获取一个Entry对象,如果没获取到则创建一个
Entry<T> entry = newEntry(chunk, nioBuffer, handle);
// 将实例化的Entry对象放到队列里
boolean queued = queue.offer(entry);
if (!queued) {
entry.recycle();
}
return queued;
}
netty 中的引用计数接口ReferenceCounted
前面在介绍netty的池化内存模型,那么从池中申请的内存是何时被释放呢,netty提供了一个引用计数接口ReferenceCounted:
public interface ReferenceCounted {
/**
* Returns the reference count of this object. If {@code 0}, it means this object has been deallocated.
*/
int refCnt();
/**
* Increases the reference count by {@code 1}.
*/
ReferenceCounted retain();
/**
* Increases the reference count by the specified {@code increment}.
*/
ReferenceCounted retain(int increment);
/**
* Records the current access location of this object for debugging purposes.
* If this object is determined to be leaked, the information recorded by this operation will be provided to you
* via {@link ResourceLeakDetector}. This method is a shortcut to {@link #touch(Object) touch(null)}.
*/
ReferenceCounted touch();
/**
* Records the current access location of this object with an additional arbitrary information for debugging
* purposes. If this object is determined to be leaked, the information recorded by this operation will be
* provided to you via {@link ResourceLeakDetector}.
*/
ReferenceCounted touch(Object hint);
/**
* Decreases the reference count by {@code 1} and deallocates this object if the reference count reaches at
* {@code 0}.
*
* @return {@code true} if and only if the reference count became {@code 0} and this object has been deallocated
*/
boolean release();
/**
* Decreases the reference count by the specified {@code decrement} and deallocates this object if the reference
* count reaches at {@code 0}.
*
* @return {@code true} if and only if the reference count became {@code 0} and this object has been deallocated
*/
boolean release(int decrement);
}
我们重点关注refCnt(),retain(),release()三个方法
- refcnt() : 返回对象当前的引用计数
- retain() : 将对象的引用计数增加1
- release() : 将对象的引用计数减少1
接口的实现者当调用release()方法后,如果发现对象的引用计数为0,将会执行回收逻辑。我们以常用的PooledDirectByteBuf为例

可以看到PooledDirectByteBuf实现了ReferenceCounted接口,而release方法的实现在父类AbstractReferenceCountedByteBuf中
@Override
public boolean release() {
return handleRelease(updater.release(this));
}
@Override
public boolean release(int decrement) {
return handleRelease(updater.release(this, decrement));
}
private boolean handleRelease(boolean result) {
if (result) {
deallocate();
}
return result;
}
/**
* Called once {@link #refCnt()} is equals 0.
*/
protected abstract void deallocate();
当引用计数变为0的时候,会调用deallocate对资源进行释放,deallocate的实现在父类PooledByteBuf中
@Override
protected final void deallocate() {
if (handle >= 0) {
// 清除对象相关属性
final long handle = this.handle;
this.handle = -1;
memory = null;
// 释放PoolChunk中申请的内存空间
chunk.arena.free(chunk, tmpNioBuf, handle, maxLength, cache);
tmpNioBuf = null;
chunk = null;
// 回收这个PooledByteBuf
recycle();
}
}
void free(PoolChunk<T> chunk, ByteBuffer nioBuffer, long handle, int normCapacity, PoolThreadCache cache) {
if (chunk.unpooled) {
// 如果是非池内内存,直接destroy
int size = chunk.chunkSize();
destroyChunk(chunk);
activeBytesHuge.add(-size);
deallocationsHuge.increment();
} else {
SizeClass sizeClass = sizeClass(handle);
// 尝试将申请的内存块放到线程本地缓存
if (cache != null && cache.add(this, chunk, nioBuffer, handle, normCapacity, sizeClass)) {
// cached so not free it.
return;
}
// 放入缓存失败,复原chunk中对应的内存块(复原二叉树)
freeChunk(chunk, handle, normCapacity, sizeClass, nioBuffer, false);
}
}
文章转载,参考了以下博客
Netty 内存管理: PooledByteBufAllocator & PoolArena 代码探险
Netty内存池之PoolArena详解
Netty内存池之PoolChunk原理详解
Netty内存池之PoolSubpage详解
Netty内存池之PoolThreadCache详解