使用python爬取学校门户网站相关信息并格式化输出
其实真正来说我不是很会写技术文档,我觉得我先从这里开始吧。俗话说的好万事开头难,那我就开始写我的第一份技术文档了。
现在我做的一些事情都是在熟悉技术。我在学习python,并且在用python处理网页请求相关的内容。
我们学校的信息门户是必需要登录才能去看的。而且网页模块的排版比较不友好,很多重要信息例如讲座的通知,后勤的断水断电的通知没有办法很方便的及时获知。受到我舍友(手动@杨大潍)的启发,我就开始在期末花了一点时间做了这么一个脚本。以下我就将我在做相关工作时候遇到的问题做一下梳理和总结吧
使用到的python库:
- requests
- beautifulsoup4
- lxml解析器(bs4依赖项目)
首先我使用的是requests的库,相比于其他python的网络库来说,requests更加易用,简单。同时也比较适合我这样的小白。requests常用的方法就是get和post。requests.get返回的是收到的GET到的网页内容。
import requests
r = requests.get(url, headers, data)
print r.text就是这么easy~不过requests的库需要点击这里下载。至于安装方法,直接就是在winPowershell里或者terminal里输入:
python setup.py install 大部分在信息门户上的信息都是需要一定的用户权限来获得。一般的时候我们需要一个账号来登入网站才能够获得我们想要的信息的。由于我们学校的信息门户十分的简陋,他的用户认证手段比较老旧,同时这也方便我们处理。
我们在这里使用了chrome的开发者工具来记录GET请求的data结构。
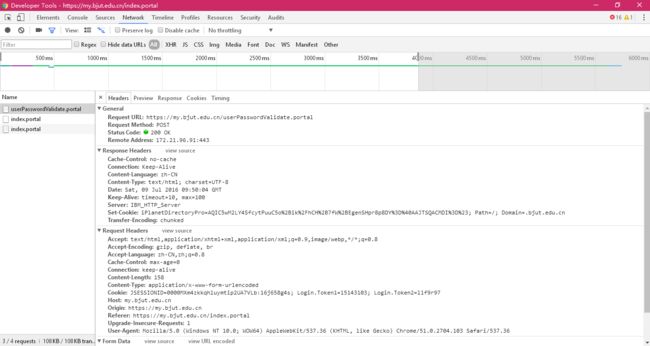
看到这个网页名字我们可以大致推测这个URL就是验证密码用户名的。
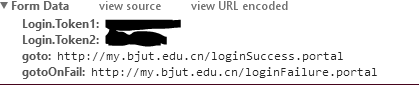
这里我们可以看到data的主要结构。token1是用户名,而token2是密码部分。goto显然就是成功后跳转的url,gotoonfail就是失败后跳转的url。
好了我们有了data结构和POST的目标我们就可以写程序了。
#coding:utf-8
import requests
from bs4 import BeautifulSoup
##刘方瑞:北京工业大学
##获取信息门户新通知的简单脚本实现
##可以拓展到检索所有信息门户的消息(院部处通知,讲座海报等等....
##认证信息dict对象
##Token1是用户名(学号)
##Token2是密码
Auth = {'Login.Token1':'AABBCCDD',
'Login.Token2':'passwd',
'goto':'http://my.bjut.edu.cn/loginSuccess.portal',
'gotoOnFail':'http://my.bjut.edu.cn/loginFailure.portal'}
##通过认证传送门获取信息门户的认证cookies
##学号结构: AA-BB-CC-DD A-学生入学年份后两位 B-学院号 C-班号 D-学生号码
ar = requests.get('https://my.bjut.edu.cn/userPasswordValidate.portal', Auth)
##利用获取的cookies来访问信息门户海报页面
r = requests.get('https://my.bjut.edu.cn/detach.portal?ignoreSessionInvalid=true&action=bulletinsMoreView&.ia=false&.pmn=view&.pen=pe438', cookies = ar.cookies)
print('HTTP Request: %d' %( ar.status_code ))到此为止我们完成了登录的所有操作。我之所以没有使用requests的session是因为我看到了这里网页进行认证以后向我们返回了一个cookie。而我们可以直接使用这个cookie来访问我们之后想要请求的页面,也就不需要跳转到登录成功的页面了(我在写脚本的时候的试验也证明了我的猜测)于是正如我写的一样,我是直接去请求我想要爬取的目录页面了。
下一步就要将我们请求到的内容交给beautifulsoup来处理解析了。这里我们使用了lxml解析器,相对来讲,它的速度会更快一些。不过我们处理的数据量不是那么的大,因此性能要求也不是那么的苛刻了。
至于beautifulsoup4的用法我们就不在这里赘述了(我认为还是非常好理解的一个网页解析器)直接上代码:
##使用beautifulsoup来解析获取的html
soup = BeautifulSoup(r.text, "lxml", from_encoding = 'utf-8')
tag = soup.find("ul", id = "blpe438")
a = 1
f = open('format.html','wb')
##标明网页使用GB18030来编码
header = 'Lecture Posters '
f.write(str(header) + '\n' + '')
##开始对所有海报下面的子节点枚举
for n in tag.children:
if (n!='\n'):
##删除带有img的a标签
n.a.decompose()
##使用beautifulsoup来获取每个单独页面的网址
url_tag = n.find('a', class_= "rss-title")
##print url_tag.encode('gb18030')
url = 'http://my.bjut.edu.cn/' + str(url_tag['href']).encode('gb18030')
url_name = (url_tag.string).encode('gb18030')
print url_name
print url
##使用之前会话的cookie对获得的网址来请求海报内容
poster = requests.get(str(url), cookies = ar.cookies)
poster_soup = BeautifulSoup(poster.text, "lxml", from_encoding = 'utf-8')
poster_tag = poster_soup.find('div', style = "padding:20px;")
print poster_tag.encode('gb18030')
##该死的信息门户使用的gb18030编码,妈的智障
##print n.encode('gb18030')
print
url_tag['href'] = url
f.write(str(a) + str(n.encode('gb18030')) + '\n' + poster_tag.encode('gb18030') + '\n')
a = a + 1
f.write('