实验名称
利用scrapy爬虫爬取豆瓣Top250电影的详细信息
实验环境
系统环境:Win7, Mac OSX10.13.3
软件:Notepad++、IDLE、Python 3.6.5
实验内容
使用scrapy来爬取豆瓣电影TOP250的相关信息,其内容应包括:电影图片、电影名、电影职员、电影评分、评分人数和电影台词
实验过程
首先打开终端,输入:
scrapy startproject Motto
这时候,系统会直接生成了一个叫Motto的文件,文件夹下有Motto和scrapy.cfg两个文件:
第二级中的Motto文件夹下有:
首先,编写items.py文件,其代码为:
from scrapy.item import Item,Field
class MottoItem(Item):
# define the fields for your item here like:
movie_name = Field()#电影名
movie_staff = Field()#职员表
movie_star = Field()#评分
movie_comment = Field()#评分人数
movie_quote = Field()#经典的话
movie_photo = Field()#电影海报
pass
保存后,新建一个python文件,开始编辑爬虫,并将爬虫软件保存到spiders文件夹下,利用safari自带的显示页面源文件可以直接查看我们所要爬取数据的Xpath:

于是我们开始编辑爬虫文件a.py,其代码如下:
import scrapy
#引入容器
from Motto.items import MottoItem
class Mottospider(scrapy.Spider):
#设置name,用于启动爬虫
name = 'Top250'
allowed_domains = ["movie.douban.com"]
#填写爬取地址
start_urls = ['https://movie.douban.com/top250?start=0']
def parse(self,response):
for movie in response.xpath("//div[@class='item']"):
item = MottoItem()
item['movie_name'] = movie.xpath("div[2]/div[1]/a/span[1]/text()").extract()[0].strip()
item['movie_staff'] = movie.xpath("div[2]/div[2]/p[1]/text()[1]").extract()[0].strip()
item['movie_star'] = movie.xpath("div[2]/div[2]/div/span[2]/text()").extract()[0].strip()
item['movie_comment'] = movie.xpath("div[2]/div[2]/div/span[4]/text()").extract()[0].strip()
item['movie_quote'] = movie.xpath("div[2]/div[2]/p[2]/span/text()").extract()[0].strip()
item['movie_photo'] = movie.xpath("div[1]/a/img/@src").extract()[0].strip()
#返回信息
yield item
next_page = response.xpath('//span[@class="next"]/a/@href')
if next_page:
url = response.urljoin(next_page[0].extract())
yield scrapy.Request(url, self.parse)
#scrapy crawl Top250 -o items.json -t json
接下来,开始启动爬虫:打开终端,并在终端中输入:
scrapy crawl Top250
实验结果
运行后,可以在终端看到(截图仅展示部分数据):
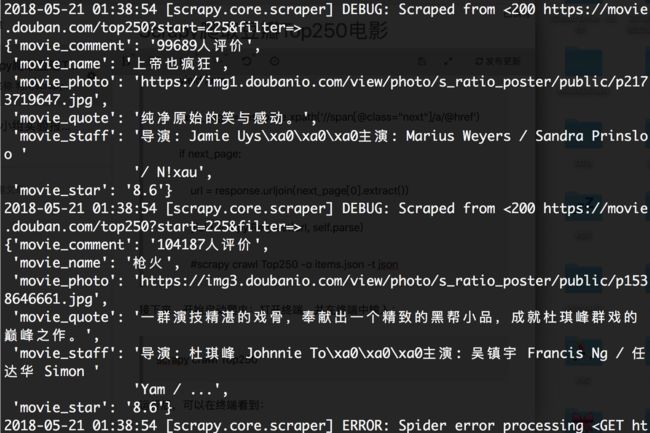
顺利爬到了我们所需要的数据。
接着,我们想要保存数据为.json格式,于是,在终端输入命令:
scrapy crawl Top250 -o Top250.json -t json
可以发现,在根目录Motto文件夹中,生成了一个名为Top50.json的文件,打开后发现其内容为(仅展示部分数据),大小约75K:
[
{"movie_name": "\u8096\u7533\u514b\u7684\u6551\u8d4e", "movie_staff": "\u5bfc\u6f14: \u5f17\u5170\u514b\u00b7\u5fb7\u62c9\u90a6\u7279 Frank Darabont\u00a0\u00a0\u00a0\u4e3b\u6f14: \u8482\u59c6\u00b7\u7f57\u5bbe\u65af Tim Robbins /...", "movie_star": "9.6", "movie_comment": "1034303\u4eba\u8bc4\u4ef7", "movie_quote": "\u5e0c\u671b\u8ba9\u4eba\u81ea\u7531\u3002", "movie_photo": "https://img3.doubanio.com/view/photo/s_ratio_poster/public/p480747492.jpg"},
{"movie_name": "\u9738\u738b\u522b\u59ec", "movie_staff": "\u5bfc\u6f14: \u9648\u51ef\u6b4c Kaige Chen\u00a0\u00a0\u00a0\u4e3b\u6f14: \u5f20\u56fd\u8363 Leslie Cheung / \u5f20\u4e30\u6bc5 Fengyi Zha...", "movie_star": "9.5", "movie_comment": "752884\u4eba\u8bc4\u4ef7", "movie_quote": "\u98ce\u534e\u7edd\u4ee3\u3002", "movie_photo": "https://img3.doubanio.com/view/photo/s_ratio_poster/public/p1910813120.jpg"},
{"movie_name": "\u8fd9\u4e2a\u6740\u624b\u4e0d\u592a\u51b7", "movie_staff": "\u5bfc\u6f14: \u5415\u514b\u00b7\u8d1d\u677e Luc Besson\u00a0\u00a0\u00a0\u4e3b\u6f14: \u8ba9\u00b7\u96f7\u8bfa Jean Reno / \u5a1c\u5854\u8389\u00b7\u6ce2\u7279\u66fc ...", "movie_star": "9.4", "movie_comment": "967683\u4eba\u8bc4\u4ef7", "movie_quote": "\u602a\u8700\u9ecd\u548c\u5c0f\u841d\u8389\u4e0d\u5f97\u4e0d\u8bf4\u7684\u6545\u4e8b\u3002", "movie_photo": "https://img3.doubanio.com/view/photo/s_ratio_poster/public/p511118051.jpg"},
]
为了将数据转化为中文,我们一开始是用Json格式在线转换器转换。后来发现可以通过修改Motto文件夹下的setting文件直接保存中文格式,于是,我们在setting.py中添加了如下代码:
FEED_EXPORT_ENCODING = 'UTF-8'
再次运行代码,我们发现最后输出的格式不再是Unicode!!!数据部分截图如下:

于是,我们的爬虫实验到此结束,详细过程可以参考以下视频:
不足之处还请多多指教