jvm学习 Shenandoah垃圾收集器
系统学习请点击jvm学习目录
建议学习Shenandoah之前先学习G1垃圾收集器
前言
Shenandoah垃圾收集器是一个很有意思的垃圾收集器,它是第一款非Oracle公司开发的HotSpot垃圾收集器,以至于Oracle JDK将其排斥在外,所以它暂时只能出现在Open JDK中。它是一款立志于在任何堆内存下都要将垃圾收集的停顿时间限制的很低(10ms,没有实现~~不过也很厉害了,这也意味着对于吞吐量自然就···),也就是追求低延迟啦。
Shenandoah垃圾收集器可以说是G1垃圾收集器的一个修改版了(不能说是改进,只能说是修改,因为Shenandoah更激进,一味追求低延迟),所以,它与G1有着高度相似,当然为了追求低延迟,它也有一些修改的地方。
下面我们就将讲讲Shenandoah与G1区别与联系在哪。如果对G1不熟悉的小伙伴可以点击G1 垃圾收集器快速入门学习。
Shenandoah与G1的区别与联系
Shenandoah是在G1的基础上进行了修改,从而向低延迟的目标进发,回忆之前我们博客中讲G1的时候,在其Mixed GC阶段,主要分为初始标记、并发标记、重新标记、清除垃圾和最终回收阶段(evacuation),其中5个有3个都是STW的,除了并发标记其他都是STW,那么为了追求低延时,此刻Shenandoah选择将其中停顿时间较大的最终回收阶段给变成非STW的,也就是并发的,用户线程与垃圾回收线程同时运行。
这一块内容便是Shenandoah与G1的核心不同之处。我们下面一小节会详细的讲。
Shenandoah继承了G1的堆内存划分,也就是将堆内存划分成了一个个大小相等的Region,也有着存放大对象的Humongous区域,但是呢,Shenandoah不遵循分代理论,也就是说在Shenandoah立即收集器的规则里,没有老年代新生代一说了。不过在进行垃圾回收时,依然是选取回收效率高的Region回收。(没了分代理论了,自然也就没有G1中的young GC了,只剩下Mixed GC)。
Shenandoah垃圾回收器放弃了G1中的记忆集(卡表实现),改从用连接矩阵这种数据结构来解决跨Region引用的问题。
所谓连接矩阵,这里其实就是图论中讲到的邻接矩阵啦。
举个例子来说一下吧:
假设现在有A、B、C、D四个Region,其中B中的对象引用了D,D中对象引用了A,那么用连接矩阵就是这样表示:
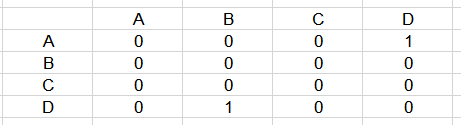
显然,通过这个连接矩阵,我们可以很方便的获得跨Region的引用情况,比起每个Region都维护一个卡表可以说方便很多,而且也节省了资源。
(奇思妙想嘻嘻:这里的连接矩阵都是0101的,感觉似乎可以用矩阵分解来降低维度,从而进一步节省存储空间,不过似乎没有必要,计算还更麻烦了)
Shenandoah工作过程
Shenandoah收集器的工作过程可以说大致上是和G1垃圾收集器中的差不多的,主要区别就是在于最终回收阶段啦,这里在Shenandoah中是并发进行的,所以我们称之为并发回收阶段(Concurrent Evacuation)。
Shenandoah垃圾回收期的工作过程可以大致划分为五个阶段:
- 初始标记(Initial Mark)
- 并发标记(Concurrent Mark)
- 重新标记(Final Mark)
- 并发清理(Concurrent Cleanup)
- 并发回收(Concurrent Evacuation)
下面对每个阶段分别进行介绍。
初始标记阶段:该阶段是标记GC ROOTS直接可达的对象。因为和G1不同,没有了young GC,没法借道,所以这里是需要STW的,不过时间非常短暂。
并发标记阶段:和用户线程一起并发工作,在可达性数上进行扫描,确认对象们的存活状态。该阶段是不需要STW的。
重新标记阶段:与G1一样,将在并发标记中被用户修改引用关系的对象重新扫描,避免出现并发可达性分析的安全问题。这里采用的是原始快照。同时,统计出回收价值最高的Region,将这些Region加入回收集。这个阶段当然是会STW的。
并发清理阶段:这个阶段和G1有点不同,因为在G1中,该阶段STW,而在Shenandoah中,却没有,该阶段作用一样,也是来清理回收集中那些无存活对象的Region。该阶段不需要STW。
并发回收阶段:该阶段是Shenandoah与G1的核心差异所在。将回收集里的存活对象复制到其他未使用的Region中,然后将原Region回收。看到这,你可能会说,这和G1有什么区别呢?G1也是做这些呀。
不一样,G1是STW之后,来复制对象,当然,这个阶段时间不短,这样的操作会十分的简单。
而在Shenandoah中,它不需要STW,也就是该阶段在Shenandoah中是并发的,哦哟,这可了不得,因为要知道,这会出并发安全问题的。所以针对此,Shenandoah进行了专门的安排。
咱们在下一小节来咱们讲一讲并发回收阶段的细节。
并发回收阶段的细节
在并发过程中实现存活对象的复制,其实是一个很困难的事情。这里主要存在两个问题:
- 复制完成之后,用户线程访问对象,是访问新对象还是访问旧的对象呢?如果是访问新对象怎么操作呢?
- 在并发过程中,如果出现并发安全问题,如何解决?
首先来解决第一个问题。
在存活对象完成复制之后,用户线程访问对象当然是要访问新的对象啦,因为此时旧对象的Region已经被视为可回收空间了嘛,当然不可能再用。
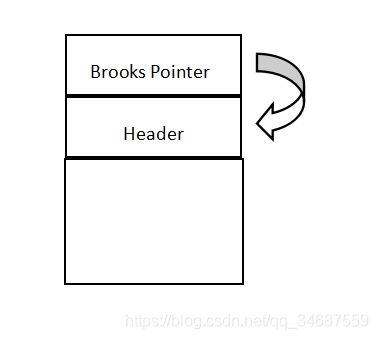
那么此时,对象的引用还是指向的是旧对象的地址,如何访问到新的对象呢?Shenandoah提出了一个办法:“Brooks Pointer”。
该办法就是在每个对象的最前面加上一个新的引用字段。这个引用字段指向对象。对于未移动的对象来说,它的引用指向自己。我们用一个示意图来说明一下。
如下图所示,引用指向自己。这也就意味着,在引入Brooks Pointer这个概念之后,我们访问一个对象的流程变成了:通过变量中存储的地址找到Brooks Pointer,再通过Brooks Pointer找到对象。
而经过了移动的对象,旧对象的Brooks Pointer则指向新对象。如下图所示。
此时访问对象的流程是:通过变量中存储的地址找到旧对象的Brooks Pointer,再通过旧对象的Brooks Pointer找到新对象的Brooks Pointer,再通过新对象的Brooks Pointer找到新对象。

如此,便解决了访问新对象的问题。
不过,这种方法也是有弊端的,很显然的就是将原本简单的对象访问流程变的更加繁琐,本来一步就能访问到对象,现在得两步,你说麻烦不麻烦。不过由于复制存活对象这事干的挺多,所以其实也还好,总体还是挺好的。
下面来解决第二个问题。
并发安全问题。在上面的问题的基础上,我们来设想这样一种情况:
- 垃圾收集线程复制了新的对象
- 用户线程更新了对象
- 垃圾收集线程将旧对象的Brooks Pointer指向新对象
如此一来,用户的更新操作落在了旧对象上,而新对象并未被操作,从而出现了安全问题。所以这个问题必须得解决。这个问题也可以说是一个同步问题,也是比较简单的,Shenandoah同时设置了读、写屏障来解决该问题。保证1,3是必须相继完成,不能被分割。
说完了上面两个问题,其实并发回收阶段的核心也讲的差不多了,接下来就简单的把并发回收阶段的具体流程简单的过一遍。
并发回收阶段流程:
- 并发复制:利用读写屏障和Brooks Pointer,将存活对象复制别的Region中去。
- 初始引用更新:设定一个线程集合点,确保并发回收阶段所有的收集线程都已经完成它们的对象移动任务。会STW很短一段时间,该阶段为下一阶段做准备。
- 并发引用更新:开始进行引用更新,将变量中的旧对象内存地址改成新对象的内存地址。沿着内存物理地址顺序进行。
- 最终引用更新:修正GC Roots中的引用,该阶段短暂的STW。
- 并发清理:将回收集中的Region回收。
总结
Shenandoah可以将总停顿时间限制的很低,相较G1、CMS还有其他的一些垃圾收集器,其可以说是低延迟了,很好的符合了当今硬件较强的时代,但是缺点也是显然,其吞吐量不如其他垃圾收集器。
总体来说Shenandoah和G1是非常相似的,在内存布局上,在整体的流程上,包括优先收集效益高的Region这一策略,都是非常相似的,但是也是有着显著不同的,比如回收阶段一个是并行,一个是并发,比如记忆集改成了连接矩阵。
总之,二者的目标是不一样的,可以说是发展方向不同的两兄弟(就好像佐助和鸣人一样)。
参考资料
- 《深入理解jvm》周志明